
性能超越 20 倍大模型,阶跃星辰多模态"小核弹" Step3-VL-10B 开源!
2026-01-24 17:40
38
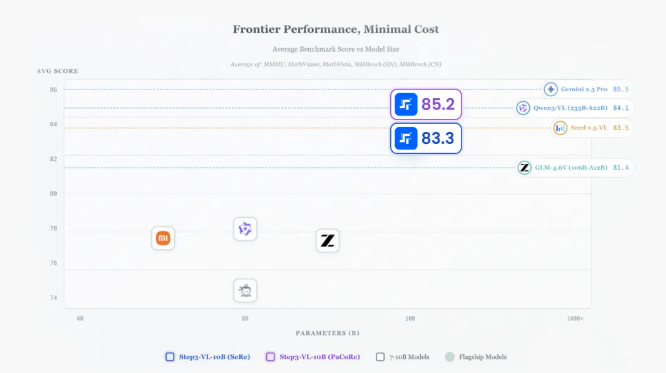
说实话,当看到一个只有10B参数的模型能跟那些动辄上百亿参数的大家伙掰手腕时,确实让人有点意外。Step3-VL-10B这次开源,算是给行业带来了一个不小的惊喜——原来小模型也能有大智慧。
你能想象吗?这个小家伙在视觉感知、逻辑推理、数学竞赛这些测试里,居然能跟GLM-4.6V(106B)、Qwen3-VL-Thinking(235B)这种重量级选手打得有来有回,甚至在某些项目上还能反超。更厉害的是,它还能媲美Gemini 2.5 Pro、Seed-1.5-VL这些顶级闭源模型。
这意味着什么?那些过去只能在云端服务器上跑的复杂任务,现在能直接塞进你的手机或笔记本里了。GUI操作、复杂文档解析、高精度计数,这些活儿都能在端侧搞定。
Base和Thinking两个版本都已经开源,想试试的话可以直接去下载。
10B参数,200B性能
Step3-VL-10B有三个比较突出的特点:
极致视觉感知标杆:在同等参数量级里,它的识别和感知精度算是拔尖的。通过PaCoRe(并行协调推理)机制,模型在复杂计数、高精度OCR、空间拓扑理解这些难啃的骨头上,表现确实稳。
深层逻辑推演与长程推理:靠着规模化强化学习的持续打磨,Step3-VL-10B在10B这个体量上实现了推理能力的质变。不管是竞赛级数学题、真实编程环境还是视觉逻辑题,它都能通过严密的思维链推导出答案。
强大端侧Agent交互:基于海量GUI专用预训练数据,模型能精准识别并操作复杂界面,这让它成为端侧Agent的核心引擎。
Step3-VL-10B提供SeRe(顺序推理)和PaCoRe(并行协调推理)两种玩法,在STEM推理、识别、OCR文档、GUI Grounding、空间理解、代码等方面,都拿到了千亿级模型才有的分数,而且PaCoRe范式表现更抢眼。
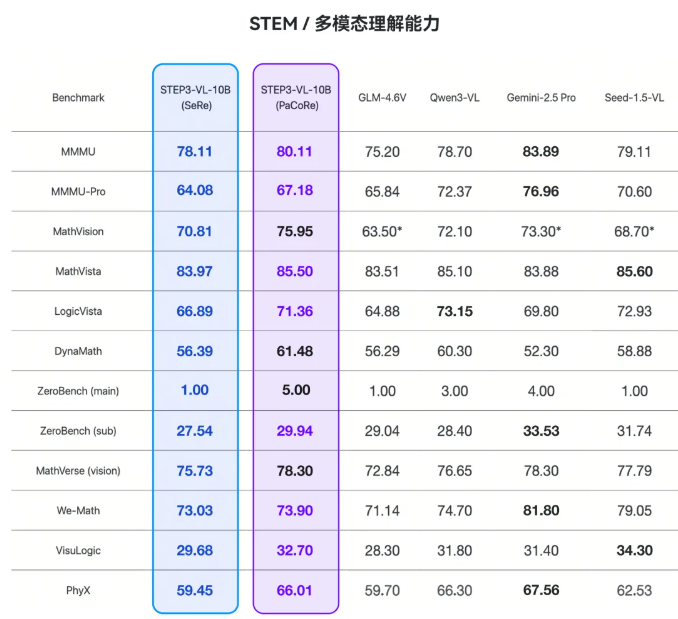
1、STEM/多模态推理
STEM和多模态推理是检验模型"深度智能"的硬指标。Step3-VL-10B在MMMU、MathVision这些测试中,成绩超过了GLM-4.6V、Qwen3-VL等一众模型。
2、竞赛数学
数学这块,Step3-VL-10B表现尤其抢眼。在AIME 25/24等数学竞赛题上几乎拿满分,达到世界第一梯队水平。这说明它已经具备了顶尖人类数学选手的思维能力,逻辑严密性甚至比很多千亿级模型还要强。
3、2D/3D空间推理
Step3-VL-10B在多个空间推理基准里都发挥得不错,特别是在BLINK、CVBench、OmniSpatial、ViewSpatial这些需要精细感知配合复杂逻辑的测试中,性能明显超过同规模模型。
4、代码
在真实动态编程环境下,Step3-VL-10B超越了不少世界一流的多模态模型。
为什么能做到?三项关键设计
能达到这个性能水平,主要靠三方面的设计:
全参数端到端多模态联合预训练:抛弃了传统分阶段冻结模块的套路,直接在1.2T高质量多模态数据集上全参数联合训练。这种方式让视觉特征和语言逻辑在底层语义空间深度对齐,给模型打下了扎实的感知能力和跨模态推理基础。
大规模多模态强化学习演进:率先把大规模强化学习引入多模态领域,经过超过1,400次迭代优化。模型在视觉识别、数理逻辑推理、通用对话等方面能力都有质的提升,而且实验数据显示,模型性能还在往上走,远没到天花板。
并行协调推理机制(PaCoRe):创新性地引入PaCoRe机制,支持推理阶段的动态算力扩展。通过并行探索多个感知假设并进行多维证据聚合,这个机制大幅提升了模型在竞赛级数学、复杂OCR识别、精准物体计数、空间拓扑推理中的准确度。
靠着这套"三位一体"架构,Step3-VL-10B证明了智能水平不完全取决于参数规模。凭借更高质量、更有针对性的数据构建,加上系统化的后训练和强化学习策略,10B级模型同样能在多项基准测试中跟10-20倍体量的模型正面硬刚,甚至实现反超。
这也意味着,世界一流的多模态能力可以用更低成本、更少算力获得了。过去集中在云端的超级智能正在逐步向端侧下沉,推动终端走向"主动理解与可执行交互",重塑人机交互体验。
Step3-VL-10B(包括Base模型和Thinking模型)已经开源,欢迎你来试用交流,也期待开源社区一起来微调这个模型,共同推动小模型实现智能跃迁!
0
好文章,需要你的鼓励