
月之暗面发布 WorldVQA:多模态大模型的 “视觉百科全书” 测试
2026-02-04 21:21
54
2月4日,月之暗面(Moonshot AI)发布多模态大模型(MLLMs)评估基准WorldVQA,核心聚焦“原子级视觉世界知识”,解决当前评测中“视觉感知失败与认知推理失败难以区分”的痛点。该基准通过“隔离干扰、聚焦实体识别”的设计,揭示前沿MLLMs在事实性视觉理解上的知识空白与过度自信问题,相关数据集已开源(https://huggingface.co/datasets/moonshotai/WorldVQA)
一、研究背景:打破“感知与推理”的缠绕,定位视觉幻觉根源
当前多模态模型评测(如MMMU、MMStar)侧重复杂逻辑推理,却忽视“基础视觉知识”这一核心前提——当模型答错“某古迹的历史”,无法判断是“没认出古迹(感知问题)”还是“不懂历史(推理问题)”。
月之暗面团队指出,多模态智能的底层是“像素→实体身份”的精准映射(即“内部视觉百科全书”),若模型无法完成这一步,只能成为“描述性引擎”而非“知识型观察者”,这正是视觉幻觉的核心来源。
因此,WorldVQA的核心设计理念是**“原子隔离(Atomic Isolation)”**:剔除OCR、算术、多跳推理等干扰,仅聚焦最基础问题——“这个视觉实体到底叫什么”,纯粹测试模型的视觉知识储备。
二、WorldVQA的核心构成:3500个VQA对,覆盖9大领域
该基准通过“严谨构建+双门控验证”确保数据可靠性,全面覆盖从“常识到长尾”的视觉知识:
1.数据规模与语言分布
共包含3500个VQA对,其中中文1260个(36%)、英文2240个(64%);
难度分三档:简单(Easy)31.17%、中等(Medium)40.77%、困难(Hard)28.07%,困难题聚焦“长尾罕见实体”(如小众物种、冷门手工艺品)。
2.九大语义领域,覆盖多元视觉知识
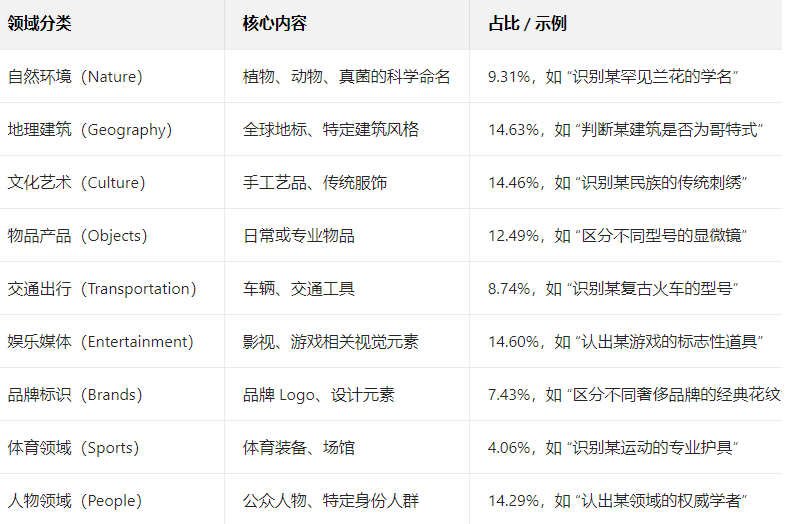
3.数据可靠性保障
双门控验证:先由高性能MLLM做一致性检查,再经人类专家盲审,确保问题与答案的准确性;
去重处理:对主流预训练语料库严格筛查,避免数据泄露,防止模型“背题”影响评测结果。
三、实验结果:顶级模型“集体翻车”,三大关键发现
月之暗面团队对13个前沿闭源/开源模型(如Gemini-3-pro、GPT-5.2、Kimi K2.5)进行测试,结果暴露多模态模型的视觉知识短板:
1.准确率天花板未超50%,长尾实体成最大挑战
表现最好的模型为Gemini-3-pro(47.4%)和月之暗面自家的Kimi K2.5(46.3%),但均未突破50%;
开源模型表现更差,Qwen3-VL-32B准确率仅17.7%,说明当前MLLMs对“非流行视觉实体”的识别能力严重不足。
2.领域表现两极分化,自然与文化成“重灾区”
优势领域:品牌(Logo识别)、体育(装备识别),因这类知识在预训练数据中曝光度高;
劣势领域:自然(物种学名)、文化(传统手工艺品),模型常给出泛化答案(如只说“花”,无法说出具体品种“蝴蝶兰”),暴露专业视觉知识空白。
3.诚实度差异显著,小模型易“编造答案”
保守策略:GPT-5.1等大模型对不确定的实体“不回答”,减少幻觉;
过度自信:部分小模型(如Grok-4-fast-reasoning)会为模糊实体“编造名称”,缺乏“知识边界自知力”,进一步印证视觉幻觉的普遍性。
四、行业意义:为多模态预训练指明新方向
WorldVQA的价值不仅是“评测工具”,更重构了多模态模型的优化逻辑:
告别“重推理、轻知识”:当前模型多是“流行文化通”,但在自然科学(物种分类)、人类多元文化(传统工艺)上储备浅薄,未来预训练需补充更多“专业、长尾”的视觉知识数据;
定位幻觉根源:模型无法精准识别实体,是后续推理产生幻觉的基础,WorldVQA为“从源头减少幻觉”提供了评测标准;
开源赋能行业:数据集开源后,可帮助更多团队针对性优化模型的视觉知识模块,推动多模态模型从“能描述”向“真懂行”进化。
WorldVQA的发布,首次将多模态模型的“视觉基础知识”纳入核心评测维度,打破“复杂推理=强多模态能力”的误区。其测试结果表明,要让模型成为“可靠的视觉观察者”,需先补全“视觉百科全书”,而非一味堆叠推理能力。
0
好文章,需要你的鼓励