
双雄对决!Claude Opus 4.6 与 GPT-5.3-Codex 同步更新,AI 圈打响能力竞赛
2026-02-06 22:01
50
2月6日,AI行业迎来重磅“双响炮”——Anthropic与OpenAI几乎同时发布新一代旗舰模型:Claude Opus 4.6与GPT-5.3-Codex。
两款模型分别聚焦“全能办公+Agent能力”与“编程攻坚+桌面操作”,在跑分、功能、生态适配上各有突破,同时围绕安全防护、定价策略推出新规则,标志着AI模型竞争从“单点能力比拼”进入“全场景生态对决”阶段。
一、核心跑分对比:各擅胜场,数据集差异导致难直接硬刚
两款模型的测评数据集存在差异(如SWE-Bench OpenAI用多语言Pro版,Claude用Python单语言Verified版;OSWorld OpenAI用修复300+问题的Verified版),仅Terminal-Bench 2.0(终端编程)可直接对比,其余需结合场景看优势:
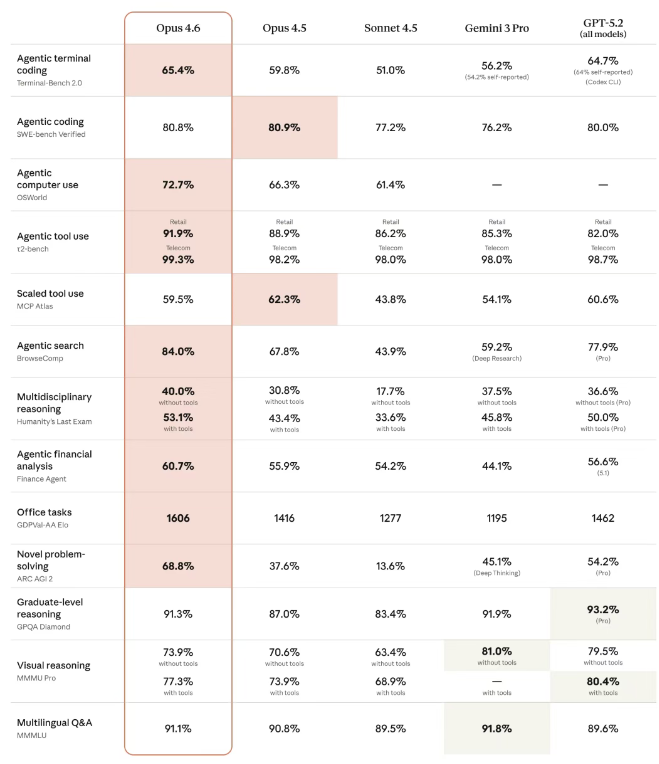
核心结论:Claude Opus 4.6胜在“全能办公+长上下文+多学科推理”,GPT-5.3-Codex强在“编程攻坚+桌面操作+安全能力”,针对性差异显著。
二、模型核心升级:Claude补办公短板,GPT-5.3-Codex强化编程与桌面
1.Claude Opus 4.6:全能办公+Agent能力再升级
基础能力突破:100万token上下文窗口支持超长篇文档处理;自适应思考(Adaptive thinking)可自主判断是否开启深度推理,搭配low/medium/high/max四档Effort参数,平衡效率与精度;
产品线联动更新:
Claude Code:新增“agent teams(智能体团队)”,支持多Agent并行处理大规模代码检查等拆分任务;
Claude in Excel:升级规划模式,可自动将非结构化数据整理为规范表格;
Claude in PowerPoint:推出研究预览版,能识别企业PPT模板(布局、字体、颜色),支持单页简化文本/添加图表,或一次性生成10张幻灯片后微调;
实用功能:beta版上下文压缩——长期对话/Agent任务逼近窗口上限时,自动生成摘要替换原内容,不丢失关键信息。
2.GPT-5.3-Codex:编程+桌面操作双爆发
核心融合:整合GPT-5.2-Codex的编码性能与GPT-5.2的推理/专业知识,推理速度提升25%,完成同等任务token消耗减半;
桌面操作质变:OSWorld-Verified(视觉桌面操作)从38.2%跃升至64.7%,能通过截图识别桌面任务并自主操作,逼近人类基准;
场景案例:推出两款演示游戏(赛车、潜水),支持网页端直接体验;可自动优化网页价格展示(如将年费转化为折扣月费呈现),贴近商业落地需求;
生态覆盖:上线即全量开放Codex app、CLI、IDE插件、网页版,暂未提供API接口。
三、定价与安全:阶梯定价vs全量开放,安全防护双管齐下
1.定价策略:Claude分档计费,GPT-5.3-Codex暂未披露API价
表格
Claude Opus 4.6定价标准定价(200k tokens内)高级定价(超200k tokens)
输入(Input)10.00/百万tokens
输出(Output)37.50/百万tokens
GPT-5.3-Codex:无API定价,全平台(app/CLI/IDE/网页)免费开放使用;API形式的GPT-4o将于一周后下架。
2.安全防护:双方针对性加固高风险场景
Anthropic(Claude Opus 4.6):
推进模型可解释性研究,追踪回答背后的决策逻辑,提前发现边缘场景误导风险;
新增6个网络安全探针,检测并拦截可能被滥用的攻击型输出(因模型网络安全能力增强,需防范被用于恶意攻击);
OpenAI(GPT-5.3-Codex):
整理恶意话术识别规则,当用户提问匹配“攻击套路”时,自动降低回答详细程度;
为开源项目提供免费代码库扫描服务,提前发现安全漏洞。
四、行业趋势:模型更新日常化,Agent形态成新战场
两款模型同步发布,暴露AI行业三大趋势:
更新节奏加速:从“重大发布会”转向“日常迭代”,功能优化更贴近实际使用场景;
能力分化显著:不再追求“全能冠军”,而是聚焦垂直场景突破(Claude攻办公,GPT-5.3-Codex守编程);
Agent生态竞争:双方均强化多Agent协作、长时任务执行能力,未来竞争焦点将从“模型本身”转向“Agent形态适配与工作流融合”。
0
好文章,需要你的鼓励