
MiniMax M2.5 登顶 OpenRouter:以 “实用主义” 破局 AI 模型竞争
2026-02-23 11:32
74
2026年2月,MiniMax发布的M2.5模型在OpenRouter平台强势登顶——发布7天调用量达破纪录的3.07T tokens,在100K-1M长文本(Agent核心消耗场景)任务中以20%的占比领跑,远超Kimi K2.5(18.5%)与Gemini 3 Flash Preview(4.9%)。
在SWE-bench Verified等主流评测中,其80.2%的得分与Claude Opus 4.6(80.8%)、Gemini 3.1 Pro(80.6%)差距不足1分,证明benchmark跑分已不再是模型竞争力的核心,而“解决真实场景问题”的实用能力成为开发者选择的关键。
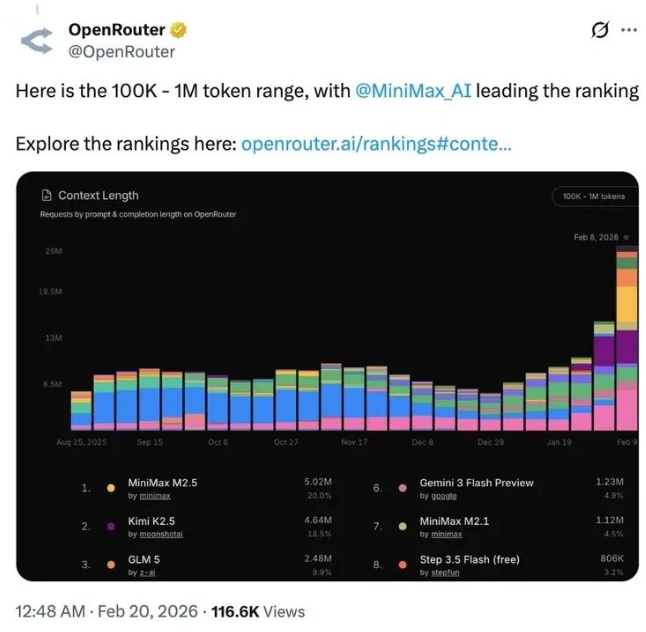
一、核心优势:直击Agent时代的核心需求
M2.5的成功源于对“效果、价格、速度”不可能三角的精准平衡,所有优化均围绕Agent与编程场景的实际痛点展开:
1.部署友好:10B激活参数的“性价比甜点位”
模型规格:总参数230B,激活参数仅10B,是头部旗舰模型中私有化部署门槛最低的选择,无需高端算力即可落地;
全场景适配:支持PC、App、React Native、Flutter等全栈开发,可一次性交付前端+后端+数据库的完整项目,适配OpenClaw等Agent脚手架,自然语言可直接转化为电脑操作;
开源支持:2月13日全球开源,支持本地化部署,进一步降低开发者使用门槛。
2.成本碾压:重新定义Agent使用经济性
价格优势:输入0.3美元/百万Token、输出2.4美元/百万Token,仅为Claude主力模型价格的1/12,且价格稳定无波动;
极致低成本:按100 tokens/秒输出速度,连续工作1小时成本仅1美元;50 tokens/秒速度下成本低至0.3美元,1万美元可支持4个Agent连续工作一年,彻底打破Agent规模化部署的成本壁垒。
3.能力聚焦:死磕Coding与Agent核心场景
编程能力跻身第一梯队:SWE-Bench Verified得分80.2%,Multi-SWE-Bench(多语言复杂场景)得分51.3%,超越Claude Opus 4.6,具备“原生Spec行为”——编码前主动拆解架构、功能与UI设计,复刻真实架构师工作流程;
Agent与工具调用顶尖:在BrowseComp、Wide Search等Agent任务中,以更少轮次消耗取得更优效果,较上一代提升20%;办公场景中,GDPval-MM测评框架平均胜率达59.0%,适配Word、PPT、Excel金融建模等高阶需求;
长任务稳定性:引入Process Reward(过程奖励)机制,全链路监控任务质量,解决长上下文场景中“跑偏”问题,处理数据统计、复杂流程等繁琐任务时表现突出。
4.推理优化:效率与吞吐双突破
极速推理:M2.5-lightning版本支持100 TPS以上输出速度,是主流模型的2倍;8xH200 TEP8环境下,10-25s TTFT(首次响应时间)可稳定维持2500 tok/s/GPU吞吐;
工程化创新:采用Windowed FIFO平衡吞吐与稳定性,通过树状结构合并重复前缀,实现40倍训练加速,每一环优化均直指业务场景的效率压力。
5.技术创新:Forge RL框架实现泛化能力跃迁
M2.5的核心技术突破在于自研工业级Agent RL训练框架Forge,解决了传统模型与Agent“混为一谈”的训练痛点:
解耦设计:将Agent及环境与模型基础能力分离,通过中间层实现物理隔离与智能调度,避免相互干扰;
泛化适配:支持接入各类Agent框架训练,可适配见过或未见过的“脚手架”,大幅提升真实场景兼容性;
加速与优化:结合异步调度策略实现40倍训练加速,采用CISPO优化与过程奖励机制,平衡任务效果与响应速度,将“真实耗时”纳入奖励函数。
二、成功逻辑:从“内部痛点”到“行业刚需”
M2.5的研发思路源于MiniMax内部的真实需求——公司团队在搭建各类Agent解决业务问题时,发现现有模型无法平衡效果、价格与速度。因此,M系列模型的迭代始终以“解决自身痛点”为核心:
内部渗透率验证:M2.5已自主完成公司30%的整体任务,覆盖研发、产品、销售等多职能,新提交代码中80%由其生成;
快速迭代闭环:108天内从M2、M2.1迭代至M2.5,SWE-bench Verified成绩从69.4%飙升至80.2%,进步曲线行业领先;
资本市场认可:模型发布推动MiniMax股价累计涨幅超413%,市值突破2656亿港元,成为2026年港股AI板块领涨标的。
三、行业启示:AI模型竞争进入“实用主义”时代
M2.5的登顶标志着AI模型竞争的核心已从“刷榜跑分”转向“价值交付”:
跑分差距失效:头部模型在核心评测中得分差距不足1分,单纯靠榜单难以形成竞争力;
场景聚焦为王:放弃“全知全能”的泛化追求,聚焦Agent与编程等高频场景做深做透,反而更易获得开发者青睐;
成本成为关键变量:Agent规模化部署的核心瓶颈是成本,M2.5的低价策略彻底激活长文本、高频率的使用需求。
未来,模型的竞争力将更多取决于“是否能解决具体问题”——当技术差距逐渐缩小,像M2.5这样“懂开发者痛点、适配真实场景、控制使用成本”的实用型模型,将成为AI时代的核心赢家。
0
好文章,需要你的鼓励