5月29日消息,百度 PaddlePaddle 团队宣布 PaddleOCR-VL-1.6 的正式发布。这是 PaddleOCR-VL 系列的最新升级版本,专注于文档解析,属于轻量级视觉语言模型。
核心亮点与性能
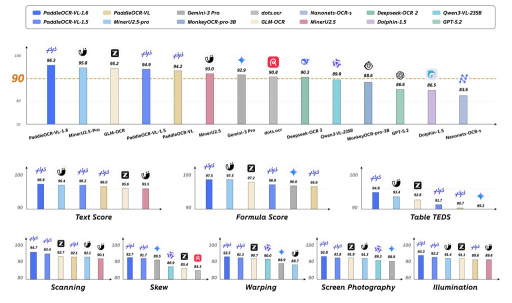
OmniDocBench v1.6:96.33%,新 SOTA,全面超越开源和闭源方案。同时在 OmniDocBench v1.5 和 Real5-OmniDocBench(真实场景基准)上刷新纪录。文本、公式、表格识别全面领先。显著提升领域:表格识别、古籍/罕见字识别、印章识别与定位、图表理解、经典文本识别。
模型架构
与 1.5 版本架构完全一致,支持零成本无缝迁移(即插即用),无需修改代码即可直接升级。
参数规模:约 1.0B(轻量高效) 支持语言:109 种(含中、英、日、韩、俄、阿、印地语等多种复杂文字) 核心能力:不仅执行 OCR,还能理解文档结构并准确定位复杂元素,如文本、表格、公式、图表、印章、手写体和古籍文字 输出格式:支持结构化输出(Markdown、JSON 等),非常适合 RAG、文档智能、知识提取等场景 技术优化:采用区域感知数据优化 + 渐进式后训练策略,针对上一版本的弱势区域进行针对性增强
获取与使用方式
2. PaddleOCR 集成使用(最方便)
与前辈相比
总结评价
PaddleOCR-VL-1.6 是当前轻量级文档解析领域最强的开源方案之一,以极小的参数量(约1B)实现了接近甚至超越更大模型的性能,尤其适合需要高精度结构化输出的企业级应用(合同、报表、学术论文、古籍数字化等)。如果你正在使用 PaddleOCR-VL-1.5,强烈建议直接升级到 1.6,几乎零成本就能获得明显提升。