5 月 29 日,自变量机器人团队重磅发布全球首个事件级预测具身智能世界模型 WALL-WM,彻底颠覆传统机器人逐帧学习动作的行业模式。
该模型创新性将世界模型预测单位从时间帧切换为语义事件,重构机器人感知、预判与动作执行逻辑,大幅强化跨场景、跨物体泛化能力,相关研究成果已正式发表学术论文。
一、传统具身 VLA 模型的核心行业痛点
当前主流视觉 - 语言 - 动作(VLA)模型普遍采用逐帧训练模式,把机器人完整动作拆分为数十帧细微画面逐帧学习。
模型仅能记忆肢体每毫米位移变化,无法理解抓取、放置等任务核心目标,一旦更换物体、场景或动作节奏微调,就极易出现任务失败。
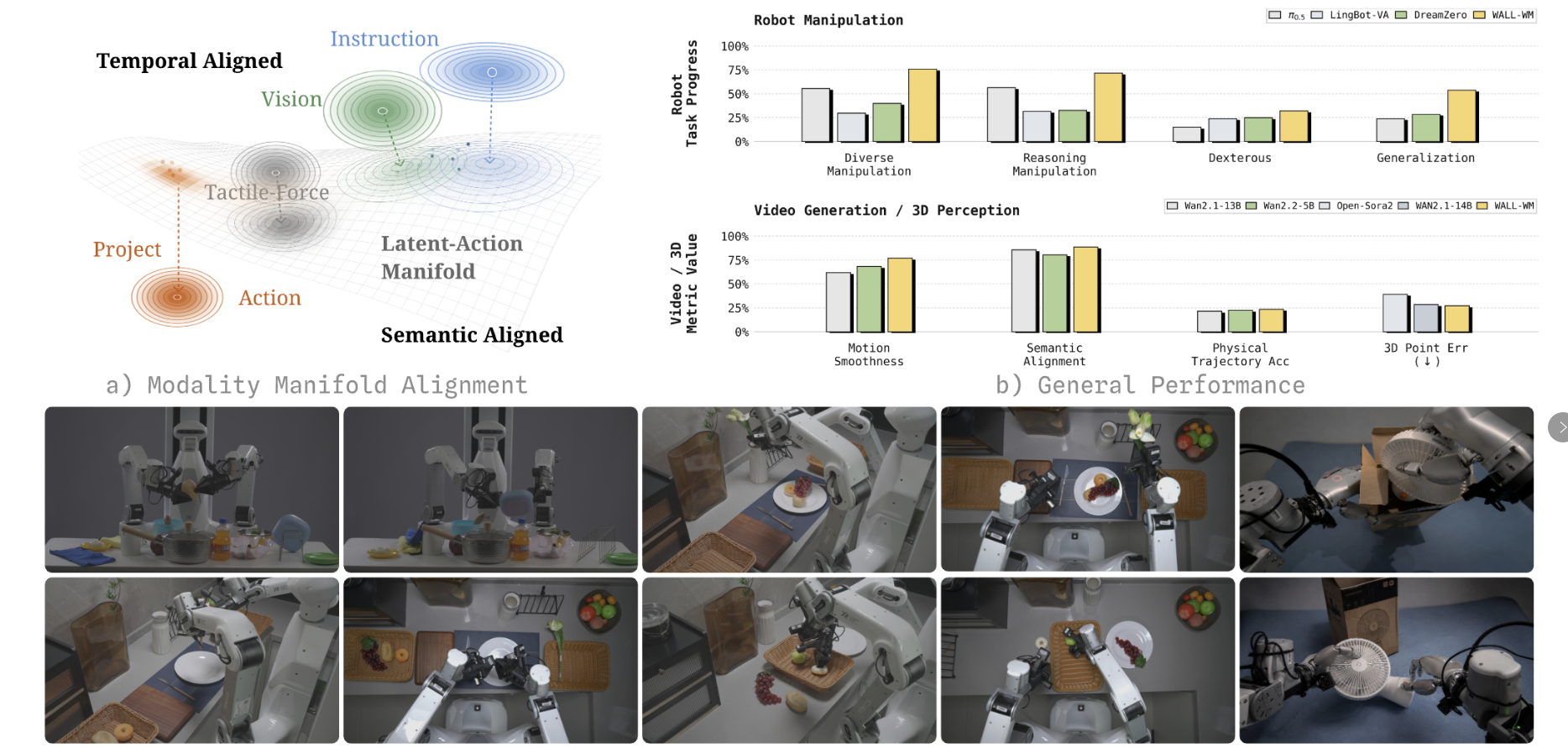
同时行业存在底层逻辑缺陷:文本、视觉、动作三类信息拥有不同流形几何与时间尺度,文本侧重高层语义、视觉为连续高维观察、动作受物理规则强约束。
强行将三者压缩至同一共享空间,会偏离物理先验特性,这也是众多 VLA 模型真机落地表现远不及理论底座水平的核心原因。
二、核心突破:事件级建模重塑机器人认知
WALL-WM 带来反行业常规的全新解法,以语义事件替代时间帧作为模型预测基本单位。
不再逐帧预判 0.1 秒、0.2 秒的画面变化,而是直接推演抓取、抬升、放置等关键事件的最终状态,跳过所有冗余中间帧,并反向生成完整动作轨迹。
模型采用以事件为中心的训练逻辑,将机器人任务切分至有物理变化、语义明确的事件边界。伸手、接触、闭合夹爪、移动等独立语义事件,可实现语言描述、视频画面、机器人动作的精准串联。凭借事件跨场景通用抽象属性,机器人摆脱固定动作模板束缚,灵活适配各类陌生环境。
三、多层技术架构与创新设计赋能性能
WALL-WM 搭建三层核心技术链路,分别为事件指令入口、事件世界模型、多视角时空融合,形成从任务解读、场景预演到全视角感知的完整闭环。
模型支持事件模式、统一模式双推理机制,共享同一套权重,既可承接上层规划指令灵活输出可变长度动作,也能自主完成实时闭环控制,适配多类应用场景。
在技术细节上,模型实现视频与动作模型分工生长,保留互联网视频的物理动态先验,动作模型专注视觉变化向机器人轨迹转化。通过视锥掩码、管状掩码解决多视角几何对齐难题,同时独创阶梯式思维链解码,拆分串行推理流程,兼顾机器人决策可解释性与实时控制低延迟需求。
四、全链路系统工程与实测性能领跑行业
WALL-WM 并非单一模型创新,而是构建了从数据、训练到部署的完整系统工程。
团队打造金字塔数据结构,融合百万级网络视频、人类动作视频、机器人真机数据;采用四级层级化标注与双聚类采样,拆分长任务序列,优化数据分布,让稀有场景与长尾样本得到充分训练。训练部署层面,依托分布式算法提升模型收敛效率,通过多事件打包降低算力损耗;部署阶段利用模型蒸馏、FP8 量化缩减推理延迟与显存占用,适配机器人实时控制需求。
实测结果显示,WALL-WM 在视频生成质量、3D 空间感知、真机基准任务中,全面超越 π0.5、DreamZero、Open-Sora 2.0 等主流模型,在新指令、新物体、新场景下均具备顶尖泛化执行能力。此次 WALL-WM 的发布,标志着具身智能行业从参数跑分、Demo 演示迈向真实落地竞争新阶段,为家用服务机器人、工业灵巧操作等场景的规模化商用,提供了全新的技术范式。