6 月 1 日,MiniMax 正式推出全新旗舰大模型MiniMax M3。作为国产前沿模型,M3 同时集齐顶尖编程 Agent 能力、百万级超长上下文、原生多模态三大核心优势,也是国内首个、全球唯一具备全套能力的开源模型。
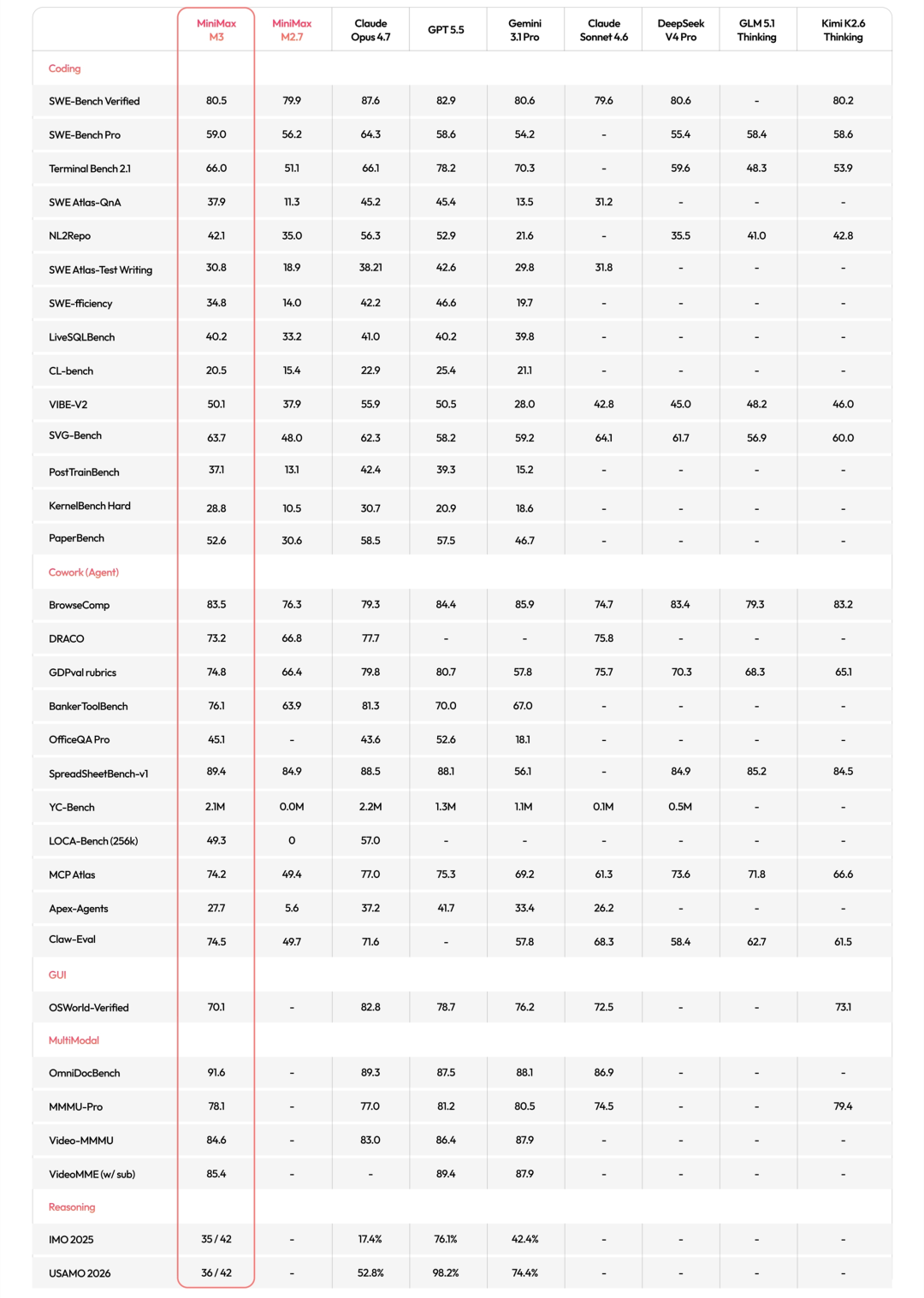
其综合实力在多项权威评测中超越 GPT-5.5、Gemini 3.1 Pro,逼近 Claude Opus 4.7,未来将开放开源权重,支持私有化部署与二次微调。
一、自研 MSA 稀疏架构,突破超长上下文瓶颈
为解决传统大模型长上下文计算量大、推理缓慢的痛点,MiniMax M3 底层采用MSA 自研稀疏注意力架构,摒弃传统全注意力机制的固有缺陷。
通过 KV 分块筛选、外层聚合查询等创新设计,精准优化注意力分配,计算效率远超 Flash-Sparse-Attention 等主流开源方案。M3 API 最高支持100 万 token 超长上下文,保底可用 512K token。在百万上下文场景下,单 token 计算量仅为上代模型的 1/20,预填充阶段提速超 9 倍,解码阶段提速超 15 倍,且能力无损对标全注意力模型。高效架构让模型轻松处理超长论文、完整代码仓库、多轮复杂 Agent 任务,实现上下文维度规模化扩展。
二、编程与 Agent 实力拉满,多项评测领跑全球
编程和智能体能力是 MiniMax M3 核心强项,在国际权威榜单中表现亮眼:
SWE-Bench Pro 超越 GPT-5.5 与 Gemini 3.1 Pro;
BrowseComp 智能体评测 83.5 分反超 Opus 4.7;
Claw-Eval 自主 Agent 评测拿下全场最高分。
实战能力更具说服力,M3 可自主耗时 12 小时复现 ICLR 获奖论文,完成代码提交、实验绘图与结论验证;还能从零攻坚 NVIDIA Hopper 架构 FP8 内核优化,24 小时内完成千次工具调用,将硬件利用率从 7.6% 提升至 71.3%,实现 9.4 倍加速。同时模型可自主完成大模型数据合成、训练迭代全流程,综合实力仅次于 Opus 4.7 和 GPT-5.5,领先行业多数模型。
三、原生多模态训练,深度适配全场景应用
MiniMax M3 从训练初始就采用多模态混合训练,重构数据管线将预训练数据扩容至 100 万亿 token,依托交错数据训练模式,实现文本、图像、视频语义深度融合,告别后期补丁式适配。
模型支持图片、视频输入,具备电脑桌面远程操作能力,可跨应用完成办公自动化任务。
在 OmniDocBench 多模态文档评测中,得分超越 Gemini 3.1 Pro,擅长解析图表、公式与长文档,完美适配学术研究、办公自动化、多媒体内容理解等场景。
四、配套生态完善,高性价比即将开源
MiniMax 同步上线专属 Agent 产品MiniMax Code,依托 M3 能力实现任务拆解、集群协作、自主反思修正,可无人干预连续运行数天,还支持电脑端跨系统自动化操作。
定价方面,M3 推出三档 Token 套餐,同等价格下用量约为 Claude 订阅的 15 倍,支持思考与极速双模式按需切换。官方已确认 M3 即将登陆 GitHub 与 HuggingFace 开源,开放模型权重与技术报告,开发者可自由部署私有集群、定制微调,将为国产 AI 开源生态注入全新活力。