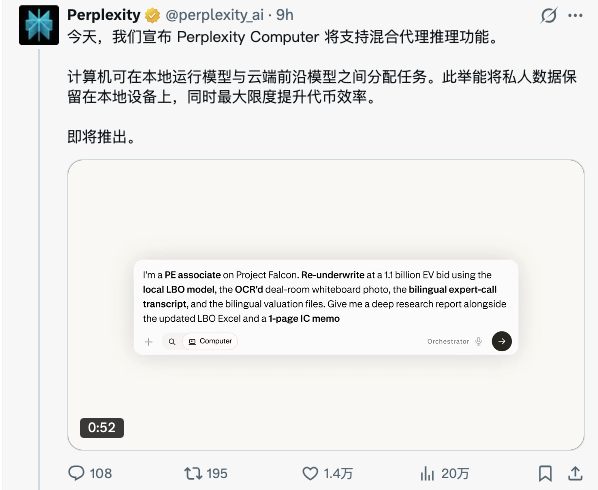
6月3日消息,Perplexity在台北国际电脑展(Computex 2026)的Intel主题演讲上正式发布混合代理推理(Hybrid Agentic Inference),CEO Aravind Srinivas使用Intel Core Ultra Series 3处理器进行现场演示。核心机制是让系统自身决定每个任务片段应在本地还是云端执行——敏感数据(金融记录、健康信息等)留在设备端模型处理,需要前沿模型能力的复杂推理交给云端,无需用户手动选择。
Perplexity称此前没有产品实现过这种自动化的任务级路由。该功能将于7月全面推送,首批支持Windows笔记本。
从Personal Computer到混合推理:架构层面的实质性升级
理解此次发布需要回溯Perplexity Computer的演进。2月25日Perplexity Computer以云端多模型编排Agent形态上线,调度约20个前沿模型(Claude、Gemini、GPT、Grok等)完成复杂任务。3月Ask 2026开发者大会上发布的Personal Computer将能力下沉到本地设备,可访问Mac文件系统和原生应用,文件在安全沙箱中创建,操作可审计和回滚。5月7日Personal Computer向全部Mac用户开放。
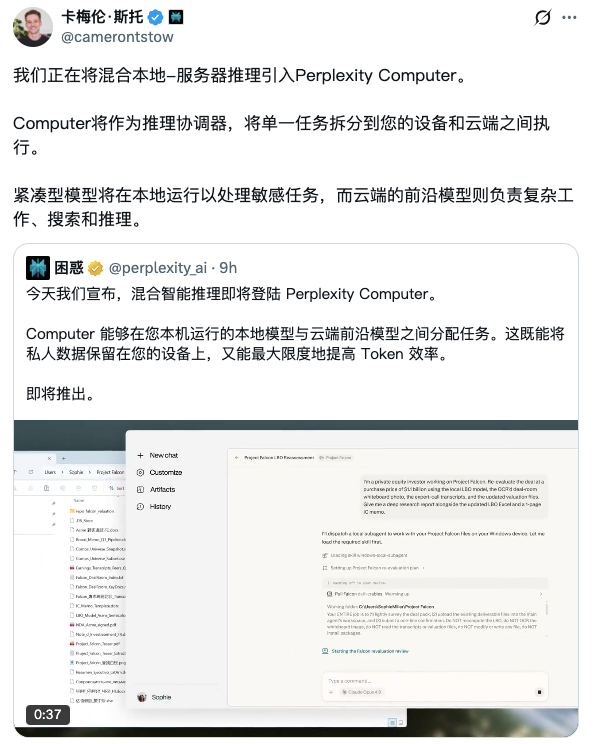
但此前版本的"混合"分工相对清晰:本地负责文件访问,重计算交给Perplexity服务器。此次在Computex发布的混合推理编排器是架构层面的升级——系统不仅选择用哪个模型,还自动决定每个计算步骤在哪个物理位置执行。一个任务可以跨多个执行位置,编排完全自动化。
Srinivas在Bloomberg播客中解释了编排器的工作原理:"编排器是一个软件层,决定一个查询或AI工作负载的某个部分是应该在设备端本地完成,还是需要云端服务器的更强计算能力。"这一设计同时优化三个维度:隐私保护(敏感数据不出设备)、每瓦特token效率(充分利用本地硬件)、以及降低云端GPU负载。
值得注意的是,此次演示和首批推送仅限Intel处理器和Windows平台。这是Intel与Perplexity的合作安排——Intel正在Computex推广其Core Ultra Series 3(基于18A工艺的首款产品),Perplexity的混合推理是其展示AI PC能力的核心案例。
Perplexity将推出自有本地模型,嵌入Perplexity Computer
与混合推理编排器同步宣布的另一个关键信息是:Perplexity将推出可在用户个人硬件上运行的本地模型,直接集成至Perplexity Computer中。
这与编排器是两个不同层次的事情。编排器解决的是"在哪里跑"的路由问题,本地模型解决的是"跑什么"的供给问题。此前Perplexity不控制自有基础模型,作为编排平台调用Claude、Gemini、GPT等约20个第三方模型。推出自有本地模型意味着Perplexity开始在模型供给侧布局,至少在本地推理场景下不再完全依赖第三方。
Perplexity给出的价值主张是三重的:充分利用本地硬件性能、保障隐私安全、提升每瓦特token效率,同时在需要时仍可调用服务器端GPU上的前沿模型。该功能标注"Coming soon to Windows laptops",与混合推理编排器的7月推送时间线大致吻合,但具体模型参数、架构和支持的硬件门槛均未披露。
两种新方式将健康数据导入Perplexity Computer
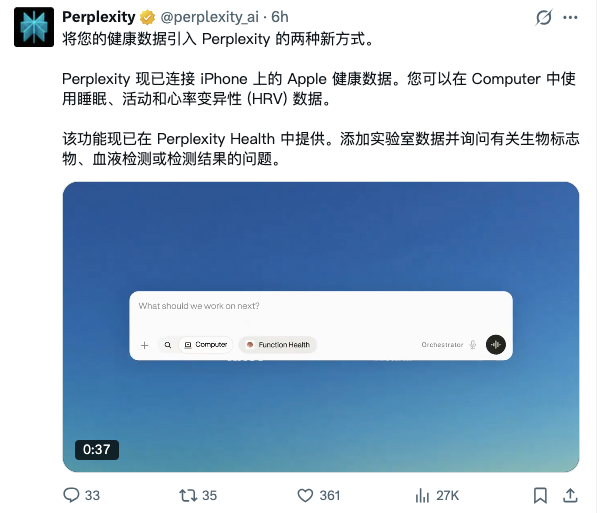
Perplexity Health目前已上线两种数据导入方式,与混合推理的"敏感数据本地处理"场景直接相关。
第一种是连接iPhone上的Apple Health。用户可将Apple Watch/iPhone采集的睡眠、活动(步数、运动)、HRV(心率变异性)等数据接入Perplexity Computer,直接在Agent对话和任务中调用。
第二种是添加实验室数据。用户可查询生物标志物、血液检测或检查面板结果,数据来源覆盖超170万家医疗机构的电子健康记录(通过b.well和Terra API接入),同时支持Fitbit、Withings、Ultrahuman等可穿戴设备,Oura和Function即将上线。
两类数据汇入同一个个性化仪表盘,支持跨来源提问。功能面向Pro和Max订阅用户(美国优先)。健康数据仅用于回答用户问题,Perplexity承诺不用于训练或出售。
竞品对比:混合推理是差异化卡位,本地模型改变竞争定位
混合代理推理层面,Perplexity目前没有直接竞品做到同等粒度的自动化任务路由。微软的MXC安全容器解决的是Agent隔离问题,不涉及推理负载的动态分配;Apple Intelligence的本地-云端分流偏向通用任务而非Agent级编排。Perplexity的差异化在于将"在哪里计算"的决策嵌入推理流程本身,而非让用户或开发者预先配置。
自有本地模型的推出则改变了Perplexity的竞争定位。此前它是纯粹的编排层,不拥有模型;一旦开始在本地推理场景中部署自有模型,它就同时成为模型提供商和编排平台,与上游模型厂商的关系会变得更加微妙。
健康数据领域是多方混战。OpenAI的ChatGPT Health在2026年1月率先接入Apple Health,微软Copilot Health也在布局。Perplexity Health的覆盖广度——170万家EHR提供商+多平台可穿戴+Apple Health的组合——是目前接入范围最广的方案。
需要注意的局限
混合代理推理目前尚未面向用户开放,7月推送时间表存在不确定性。首批仅支持Intel处理器+Windows,Mac和其他芯片平台的支持时间未公布。自有本地模型的具体型号、参数规模和架构均未披露,本地推理的能力边界不明确。编排器如何处理跨域数据分类的边界情况(某些数据既涉及隐私又需要复杂推理)没有技术细节。此外,Computex上的展示是与Intel的联合商业活动,Perplexity在技术层面对Intel平台的实际依赖程度尚不清楚。Health功能仅限美国Pro/Max用户,EHR接入依赖b.well的网络覆盖范围。