在 Anthropic 与 OpenAI 的模型大战愈演愈烈之际,谷歌悄然推出颠覆性文本生成模型DiffusionGemma。
它首次将图像领域成熟的扩散技术应用于大语言模型,彻底打破传统自回归架构的速度瓶颈,实现了 “印刷机式” 的并行文本生成,同时以 Apache 2.0 协议完全开源,为本地部署与商业应用打开了全新空间。
一、性能炸裂:速度碾压自回归,消费级显卡可跑
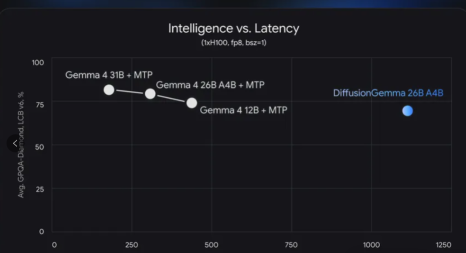
DiffusionGemma 的核心优势是极致的生成速度。实测数据显示,在单块 H100 显卡上(FP8 精度,batch size=1),它的输出速度突破1000 token/s;在消费级 RTX 5090 上也能达到 700+ token/s,是同规格自回归模型的 4 倍。
即便是搭载 MTP 加速的 Gemma 4 26B,速度也仅为 300+ token/s。参数与部署门槛同样亲民:这款 26B 参数的 MoE 模型,推理时仅激活 3.8B 参数,经过 FP8 量化后仅需 18GB 显存即可运行,一张 RTX 4090 就能实现流畅的本地部署。
目前模型权重已在 Hugging Face 开放下载,采用允许商用的 Apache 2.0 协议,开发者可直接用于生产环境。
二、技术革新:从 “打字机” 到 “印刷机” 的架构革命
传统 GPT、Claude 等大模型均采用自回归架构,如同打字机一般逐 token 生成文本,每输出一个新词都需要重新加载全部模型权重,导致本地运行时 GPU 算力大量闲置,陷入 “内存带宽瓶颈”。DiffusionGemma 则借鉴了 Stable Diffusion 的图像生成逻辑,采用 “印刷机式” 并行生成模式:
首先铺开一张包含 256 个 token 的随机噪声画布,然后通过多轮迭代去噪,高置信度的 token 先被锁定,再以此为线索修正其余部分,最终整段文字同时收敛成型。这种模式充分调动了 GPU 的并行计算能力,将瓶颈从内存搬运转变为算力输出,而这正是 GPU 最擅长的领域。
三、独特能力:双向注意力实现实时自我纠错
除了速度优势,扩散架构还赋予了 DiffusionGemma 自回归模型难以具备的双向注意力能力。传统自回归模型生成第 N 个 token 时,只能看到前面的内容,无法预判后续逻辑;而 DiffusionGemma 的所有 token 同时生成,每个 token 都能感知全局上下文,支持边生成边修正错误。
谷歌用数独游戏直观展示了这一优势:由于数独需要前后数字相互约束,自回归模型的解题成功率几乎为 0,而微调后的 DiffusionGemma 成功率飙升至 80%。这一特性让它在代码补全、行内编辑、复杂 Markdown 格式化等需要全局协调的场景中,拥有天然的结构性优势。
四、定位与行业影响:谷歌的 “速度赛马” 实验
谷歌明确表示,DiffusionGemma 目前定位为 “实验性模型”,其综合能力仍略逊于同参数的 Gemma 4,生产环境仍推荐使用标准自回归模型。它的核心适用场景是对速度敏感的本地交互,比如实时对话、快速草稿生成、轻量代码编写等。尽管并非颠覆性的全能模型,但 DiffusionGemma 的意义远超技术演示本身。
谷歌为其配备了完整的生态支持,NVIDIA 从 RTX 消费级显卡到 H100 数据中心芯片全线适配,vLLM、MLX、Unsloth 等主流推理框架均已提供支持。它的开源彻底打开了扩散文本模型的赛道,证明了并行生成的可行性,为下一代大模型的技术路线提供了全新方向。
这场由谷歌发起的 “速度革命”,或将倒逼整个行业重新思考大模型的架构设计。未来,自回归与扩散架构很可能形成互补,分别主导高质量生成与极速交互场景,共同推动 AI 能力的进一步普惠。