6月15日,商汤旗下 SenseNova 团队在 Hugging Face 发布了 SenseNova-U1 系列的第三个专项优化版本——SenseNova-U1-8B-MoT-Interleaved。这是一款专门针对图文交错生成(interleaved image-text generation)场景调优的多模态模型,核心改进集中在多页面内容的叙事连贯性、角色与风格一致性,以及文字渲染和布局质量上。
模型权重已上线 Hugging Face,采用 Apache 2.0 协议开源,允许商用。
这个模型解决什么问题
图文交错生成是一种让模型在同一个输出流中交替产出文字和图像的能力。典型场景包括儿童绘本、旅行日记、产品说明书、教程指南等——这类内容需要多个页面之间保持视觉风格统一、角色形象一致,同时文字叙事自然衔接。
SenseNova U1 系列从 4 月发布起就将图文交错生成作为核心能力之一。但在基础版本(8B-MoT)和后续的信息图版本(8B-MoT-Infographic)中,这一能力的表现仍处于 Beta 状态——官方此前明确标注「RL 尚未针对视觉编辑、推理和交错任务做专项优化」。
Interleaved 版本正是对这一短板的定向补强。根据官方发布说明,该版本在三个维度做了改进:跨页面叙事的连贯性显著增强;角色身份与艺术风格在多页面内容中保持稳定;文字渲染更清晰、布局更可靠、视觉瑕疵更少。
U1 系列的架构基础
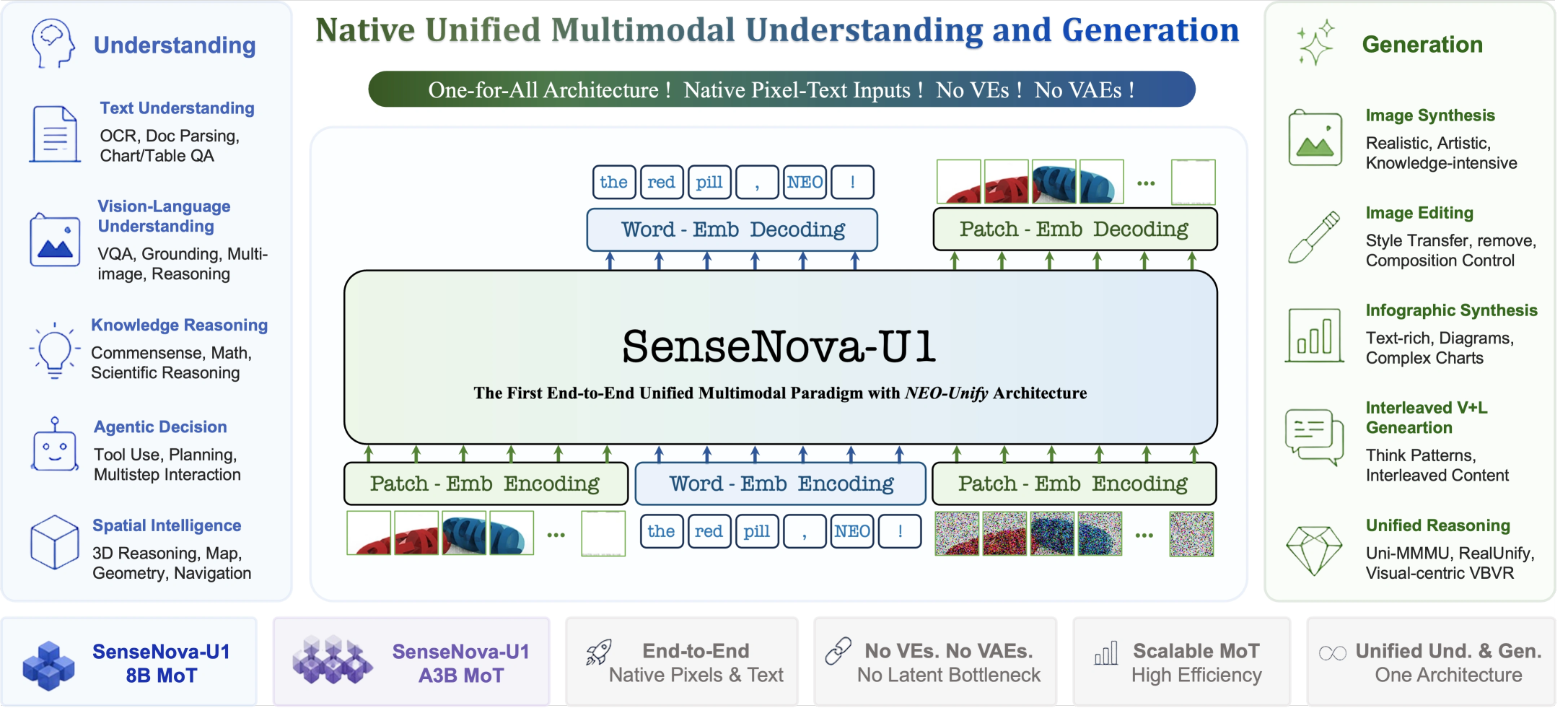
要理解 Interleaved 版本的定位,需要先了解它所在的 SenseNova U1 系列。
U1 系列于 2026 年 4 月 27 日首次发布,定位是「原生统一多模态模型」。与主流多模态架构不同,U1 的核心架构 NEO-Unify 采取了一个激进的设计选择:同时去掉了视觉编码器(Visual Encoder)和变分自编码器(VAE),让语言和视觉信息在像素到文字的层面上端到端统一建模。
这意味着 U1 不是把一个语言模型和一个图像生成模型通过适配器拼接在一起,而是用同一个模型原生处理理解、推理和生成任务。官方用的措辞是「从模态拼接到真正统一」。
在参数规模上,8B-MoT 中的「8B」指约 80 亿理解参数和约 80 亿生成参数。目前公开的还有一个更轻量的 A3B 版本(约 30 亿激活参数)。官方表示更大规模的版本在规划中。
U1 系列的迭代时间线
商汤在不到两个月内为 U1 系列发布了三个专项版本:
2026 年 4 月 27 日,发布基础版 SenseNova-U1-8B-MoT 和指令微调版 SenseNova-U1-8B-MoT-SFT,同步发布推理代码和权重,Apache 2.0 协议。同期在 HuggingFace 上线了 A3B 轻量版本。
2026 年 5 月 15 日,发布信息图专项版 SenseNova-U1-8B-MoT-Infographic,针对高密度信息可视化场景优化。在 BizGenEval 基准上,hard/easy 分别从基础版的 39.8/61.1 提升到 46.6/65.4,IGenBench Q-ACC/I-ACC 从 51.3/4.2 提升到 69.5/17.0。
2026 年 6 月 11 日,发布图文交错专项版 SenseNova-U1-8B-MoT-Interleaved,即本文报道的版本。
这个迭代节奏说明商汤的策略是:先发布通用基础模型,再根据具体应用场景逐步推出专项调优版本。信息图和图文交错是目前优先级最高的两个方向。
对创作者和开发者意味着什么
U1-Interleaved 最直接的受众是需要批量生成多页图文内容的创作者和开发者。
在应用场景层面,如果你在做绘本、漫画分镜、图文教程、产品手册等需要多页面视觉一致性的内容,这个模型的改进方向正好对准了核心痛点。此前的基础版在跨页面生成时,角色外观漂移和风格断裂是普遍反馈的问题。
在集成层面,模型可以通过 SenseNova-Skills(OpenClaw)仓库作为技能接入 Agent 工作流,提供统一的工具调用接口。也可以通过 SenseNova-Studio 在线免费体验,无需本地 GPU。
在部署层面,8B-MoT 版本的权重约 35.2 GB,官方提供了 --vram_mode 选项,可以将语言模型层保留在 CPU 固定内存上按需加载到 GPU,降低显存占用。
局限与需要关注的问题
几个方面需要保持预期管理。
首先,Interleaved 版本发布时没有公布具体的基准得分改进数据。相比信息图版本发布时给出了 BizGenEval 和 IGenBench 的量化对比,Interleaved 版本目前只有定性描述(「显著增强」「保持稳定」),缺乏可量化的评测参考。
其次,U1 系列整体仍处于早期阶段。基础版发布时官方标注了 Beta 状态,明确指出 RL 尚未针对视觉编辑和交错任务专项优化。Interleaved 版本是否已经移除了这一 Beta 标注,需要查看模型卡的最新说明。
第三,开源社区的独立评测还很少。U1 系列在 GitHub 上的关注度(约 40 Star)相比同期发布的其他多模态模型仍较低,社区反馈样本有限。
最后,8B 参数规模在当前多模态模型赛道中属于轻量级。NEO-Unify 架构的「去编码器」设计虽然理论上更高效,但在实际生成质量上能否与更大规模的传统架构模型竞争,还需要更多对比数据。
竞品参考
图文交错生成目前还不是一个竞争白热化的赛道,但已有几个值得对比的参照。
Gemini 的多模态输出支持图文混排,但不开源也不提供权重。GPT-4o 的图像生成能力近期大幅增强,同样封闭。在开源侧,EMU3、Janus 等模型也在探索统一多模态架构,但在图文交错这个具体方向上的专项优化较少。 SenseNova U1 的差异化在于:端到端无编码器架构 + 开源权重 + 按场景出专项版本的迭代策略。在「可部署的开源图文交错生成模型」这个细分品类里,目前选择确实不多。
相关链接
- 在线体验:SenseNova-Studio(免费,无需 GPU)