最近,Anthropic研究产品经理Theodora(Theo)Chu的一段内部分享视频在开发者圈子里引发了广泛讨论。
Theo在分享中提到,越来越多的开发者已经不再停留于"听说过Claude"的阶段,而是在日常工作中切实感受到了效率的飞跃。有人说Claude让自己的工作效率翻了一倍,也有人认为提升了整整十倍。更值得关注的是,Claude已经深度渗透进Anthropic自身的工程流程——Anthropic内部超过80%的代码由Claude负责合并。
这意味着,模型的角色正在发生根本性转变。它不再只是一个回答问题的工具,而是在一个具备反馈、验证与修正机制的环境中持续执行任务。Theo将这一核心理念概括为:"Close the Loop(闭合循环)——给模型一种验证自身输出结果的方式。"
这次分享的核心命题是:你该如何适应这个正在到来的新世界,又该如何面向未来而非过去来构建你的产品?
网友rari 0xwhrrari对此评价道:"这比市面上大多数卖300美元的Agent课程含金量都要高。"
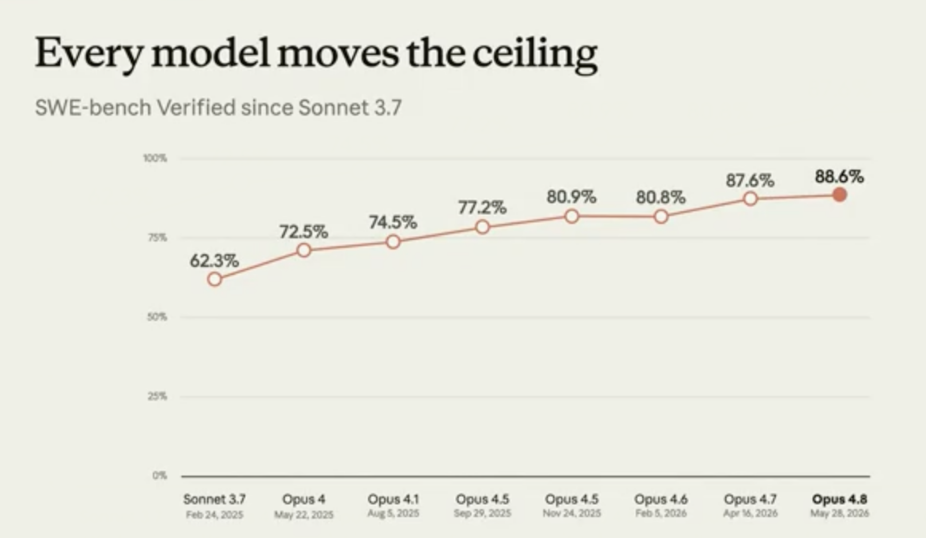
一年之内,模型失败率大幅压缩
Theo以编程评估基准SWE-bench Verified作为切入点。这个基准由一系列真实GitHub issue组成,模型需要理解问题、修改代码,并通过测试验证自己确实解决了任务,是Anthropic内部追踪Claude编程能力演进的核心评测工具。
数据对比相当直观:一年前的Sonnet 3.7得分约为60%,而最新的Opus 4.8已经达到88%。换算一下,这意味着一年前的模型在同类任务上的失败次数,大约是今天的三倍。
演讲中最值得开发者注意的不是分数本身,而是背后的含义:模型能力的提升,本质上是失败率的快速下降。失败率降低之后,模型才真正具备承担更长、更复杂、更贴近真实工作场景任务的条件。
更令人惊讶的是,在最新的Mythos和Fable系列模型中,SWE-bench这一基准已经出现接近饱和的迹象——曾经足够有区分度的测试题,今天可能已经无法有效衡量模型之间的真实差距。
这对开发者来说是一个重要警示:如果你还在用一年前的任务测试今天的模型,很可能正在系统性地低估模型真正的能力边界。
新模型的三项核心能力跃升
一、先规划,再动手
Theo展示了同一个任务在新旧两款模型上的表现对比——让模型一次性重建Claude.ai网站。
旧模型的典型做法是上来就写大量代码、调用大量工具,几乎没有任何前置规划。表面看界面结构似乎合理,但实际运行并不完整,功能无法真正闭环。
Theo用了一个生动的类比:"有点像我装宜家家具的方式——一上来就动手,完全不看说明书,拼到一半才发现做错了,这才意识到应该先回去看说明书。"
以Opus 4.8为代表的新模型则展现出了自适应思考能力。它们会先在内部深度推演具体方案,在规划阶段就主动捕捉潜在错误——你甚至能在其推理过程中看到"实际上……"或"算了,还是……"这样的自我修正表达。
这种先规划后执行的方式,让模型在正式动手时就能高效落地,显著减少了冗余的工具调用和多余代码。
Theo给开发者的建议是:给模型留出思考的空间。产品设计也应当为这种思考预留余地——使用自适应思考机制,让模型自行判断何时需要深度规划、需要规划多久。简单问题不必让模型大动干戈,但复杂任务应该给它充分的前置空间。
二、错误恢复与自我纠正
很多开发者在构建Agent时,把重心放在"让模型能调用更多工具"上。但Theo强调:工具调用本身还不够,模型必须知道自己什么时候做错了。
旧模型有一个典型问题——"doom looping":模型在任务失败后接到反馈,表示会换一种方式再试,但再次尝试时往往原路返回,根本没有真正改变解题路径,陷入循环而无法突破。
新模型在这一维度上有了实质性进步。它能够读取环境反馈、理解失败根因,并尝试走不同的执行路径。模型开始从被动执行指令,演变为具备一定程度的错误恢复能力。
这对Agent产品尤为关键。任务足够长,就一定会遇到错误:代码跑不通、页面操作失败、测试未通过、环境返回异常。真正有价值的Agent,不是永远不犯错,而是犯错之后能不能有效恢复。
Theo的建议是:开发者需要重新设计模型所处的环境,让环境能够给模型提供有效反馈。
"这也意味着,模型不会因为doom looping而无谓地消耗token,而是可以用更少的token完成任务。"
举个例子:如果你在构建一个应用生成Agent,就应该赋予它访问前端界面的能力,让它能够自己点击、自己测试、自己判断按钮是否可用、页面是否正常渲染。只有拿到这些真实的验证信号,模型才能形成"执行→验证→修正→再执行"的完整闭环。
这正是开发者rari 0xwhrrari所强调的那一点:close the agent loop——让模型能够验证自身的输出结果。
三、长程任务中的上下文连贯性
旧模型在处理长任务时经常陷入"跟丢主线"(Losing the Plot)的困境——做着做着就忘了最初的目标,或者在执行到中途时丢失了关键上下文和核心指令。
新模型在这一维度实现了显著突破,能够稳定地将注意力维持在百万Token甚至更高的规模上。这意味着开发者不再需要把上下文窗口切割得支离破碎,而是可以直接将整个代码库递给模型。
未来更合理的工作方式,是把更完整的任务交给模型:给它整个代码库而非单个文件,给它完整的产品需求而非孤立的函数片段,让它跑完整流程而非只处理局部步骤。
当三项能力叠加在一起
当规划能力、错误恢复能力和长上下文连贯性同时具备,Agent的运作形态就会发生根本性变化:先规划,再执行;执行后通过工具或人类反馈验证结果;发现问题后调整计划,重新执行。这个循环持续运转,直到任务真正完成。
开发者该如何为未来构建产品?
随着模型能力持续跃升,用户可以让它承担运行时间更长、复杂度更高的任务,而完成效果也会远超以往。那么,开发者在工程和产品层面,应该如何调整自己的研发策略?
策略一:保持野心,动态刷新评估基准
不要总是测试那些一年前的模型就能完成的任务,而应该持续关注今天的模型尚未做到、但未来用户体验真正需要的能力边界。
Theo提到一个常见误判:新模型发布后,有些客户反馈"我的Evals只提升了1%,这个模型好像没多大进步"。但实际上问题不在模型,而在Evals本身已经过时——它们根本没有覆盖到新模型真正提升的能力维度。
Evals要面向未来设计。把用户最新反馈的失败场景,以及你希望产品未来达到的能力方向,都纳入测试用例。如果某些历史遗留问题证明无法突破,立刻用更难的题目替换。
策略二:精简"脚手架",给模型松绑
Theo反复强调的另一个建议是:shrink your scaffolding——精简模型周围的"脚手架"。
所谓脚手架,是指开发者为修补旧模型各种短板而在其周围堆砌的系统提示词、外部逻辑、各类约束和补丁:某次格式错了加一条规则,某次没遵守要求再加一段约束,某次工具调用失败再套一层逻辑……这些补丁在旧模型时代或许管用,但当新模型的指令遵循能力大幅提升后,这些旧补丁反而可能制造新问题。
Theo举了Anthropic自身的一个例子:团队一度以为新模型在Claude.ai的引用功能上出了Bug,排查后才发现,是因为新模型太"听话",精准执行了一行早已写在系统提示词里、却早就过时的引用格式指令。只需删掉那行旧指令,功能立刻恢复正常。
针对意图编写简洁的提示词,明确最终想要的结果,而不是围绕旧模型的失败经验过度包装。给模型更多自主空间,你才能真正看清它的能力天花板在哪里。
策略三:闭环设计,让模型验证自身输出
这是构建自改进Agent最核心的工程原则。具体包含三个层面:
给模型留出思考与工作的空间。在产品设计上引入自适应思考机制,允许模型进行前置推理,甚至通过"投入度拨盘"让模型自由调节在某个复杂问题上的钻研深度。
以受控方式开放高权限。要发挥Agent的自主性,就必须赋予它在环境中采取行动的能力。Anthropic在Claude Code中推出了"自动模式"分类器,能够在开发者的控制需求与模型的自主空间之间找到动态平衡,自动甄别哪些操作是安全可执行的。 为模型配备自我质检工具。为Agent提供类似"Computer Use"这样的自动化验证能力,让它能够自行访问前端界面、点击测试、通过真实环境反馈发现自身错误,从而实现代码层面的自我迭代与修正。
模型正在变得越来越强,Agent的形态也在随之加速演进。开发者能做的,是确保自己构建的产品跟得上这个变化的节奏——而不是还在用昨天的标准,评估今天的模型。