6月26日消息,GrandCode竞赛编程AI背后的团队DeepReinforce发布了Ornith-1.0,一个专为智能体编码设计的开源自改进模型系列。完整阵容覆盖9B/31B密集模型和35B/397B混合专家模型四个规格,基于Gemma 4和Qwen 3.5构建,全部以MIT许可在Hugging Face开源。据DeepReinforce公布的基准数据,旗舰版397B在Terminal-Bench 2.1(77.5)和SWE-Bench Verified(82.4)上超越Claude Opus 4.7,9B边缘版可匹配Gemma 4-31B等更大模型。
核心创新:模型自己写训练脚手架
当前主流编码智能体的标准做法是将模型与人工设计的固定脚手架(harness)配对——脚手架负责组织提示、协调工具调用和引导解题流程,模型在脚手架框架内生成代码。Ornith-1.0改变了这一范式:模型在强化学习过程中学会自己编写脚手架。
具体机制是每个RL步骤分两阶段运行。第一阶段,模型根据当前任务和上一轮使用的脚手架,提出改进后的新脚手架。第二阶段,模型在该新脚手架的条件下生成解决方案。解题结果的奖励信号同时回流到两个阶段,使模型不仅优化代码生成能力,还同步优化组织搜索轨迹的策略本身。
这种自编写脚手架的方式引入了奖励黑客风险——模型可能学会读取测试文件并硬编码预期输出。DeepReinforce描述了三层防御:固定信任边界(环境和测试隔离不可被模型修改)、确定性监视器(禁止操作触发零奖励并排除出训练)、冻结LLM裁判(在验证器之上进行否决)。
基准数据:同规模开源SOTA,但仍落后Opus 4.8
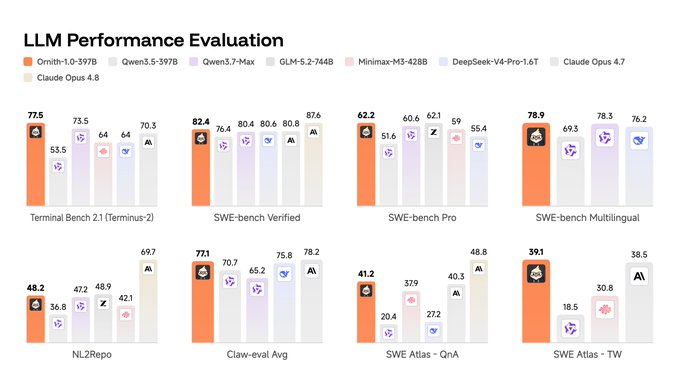
DeepReinforce将Ornith-1.0定位为同等规模开源模型中的SOTA。旗舰版397B MoE的表现:Terminal-Bench 2.1得分77.5,超过Claude Opus 4.7(70.3)、MiniMax M3(66.0)和DeepSeek-V4-Pro(67.9);SWE-Bench Verified得分82.4,同样超过Opus 4.7(80.8)。
但需要注意上限:397B仍落后于Claude Opus 4.8(Terminal-Bench 85.0、SWE-Bench 87.6)和更大规模的GLM-5.2-744B(Terminal-Bench 81.0)。"同等规模开源SOTA"的限定词是准确的。
效率向更值得关注。35B MoE在Terminal-Bench上得分64.2,超过体量大十倍的Qwen 3.5-397B(53.5)。9B密集模型得分43.1(Terminal-Bench)和69.4(SWE-Bench),可在单块80GB GPU上运行,匹配Gemma 4-31B等3倍以上体量的模型。对于资源受限的开发者和需要本地部署的场景,9B版本的性价比是最直接的实用价值。
团队背景:从GrandCode到CUDA-L1再到Ornith
DeepReinforce并非新面孔。2026年4月,该团队的GrandCode系统在Codeforces Round 1087-1089三场连续比赛中全部排名第一,击败所有人类选手(包括传奇大师级选手),成为首个在竞赛编程领域全面超越人类的AI系统。更早的CUDA-L1项目是一个强化学习驱动的GPU内核优化框架,在250个任务上实现平均3.12倍加速。IterX则是面向编码智能体的优化循环工具。
从GrandCode的竞赛编程到Ornith-1.0的工程编码,DeepReinforce的路线是一致的:用强化学习方法重新定义编码AI的训练范式。Ornith-1.0将这一路线从封闭系统扩展到了开源社区——9B到397B的完整规格矩阵加MIT许可,使得任何开发者都可以在本地复现和扩展这套自脚手架方法。
所有模型权重已在Hugging Face发布,提供FP8和GGUF格式,支持vLLM和SGLang部署。推荐采样参数为temperature=0.6、top_p=0.95、top_k=20。