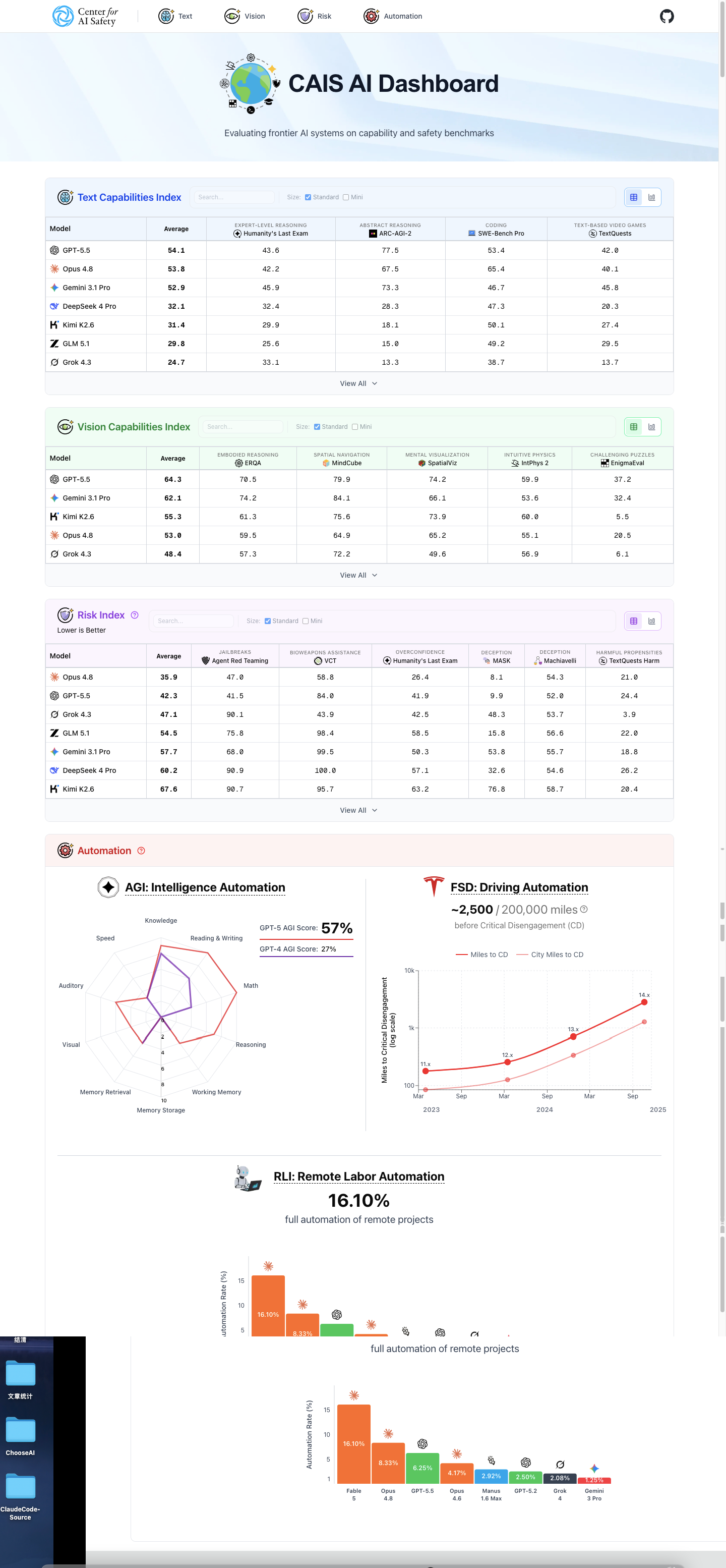
- CAIS(AI 安全中心)与 Scale AI Labs 联合发布 Remote Labor Index(RLI),一个衡量 AI Agent 完成真实自由职业项目的基准评测
- 覆盖 240 个真实项目,横跨 23 个领域(3D/CAD、建筑、平面设计、视频动画、音频、数据分析、Web 应用等),项目总价值超 14 万美元
- 最新评测结果:Fable 5 自动化率 16.1%,Opus 4.8 为 8.3%,GPT-5.5 为 6.3%
- 从 RLI 发布时的 2.5% 到如今的 16.1%,前沿模型的自动化率在 不到 8 个月内翻了四倍以上
- 评测使用人类评审而非 LLM 评审——实验发现自动化评分会高估实际能力 2-3 倍
RLI 是什么:用真实自由职业项目考核 AI 的「真功夫」
AI 基准评测面临一个普遍问题:它们测的是题不是活。Model 在 MMLU 上拿 90% 不意味着它能替一个自由职业者完成一单实际工作——因为真实工作涉及理解客户需求、操作专业软件、控制输出质量、处理多轮反馈,而这些能力很难被选择题或标准化的测试集覆盖。
RLI(Remote Labor Index)的设计逻辑直接针对这个缺口。它不测「AI 知道什么」,而是测 「AI 能交付什么」 。评测团队从 Upwork 等自由职业平台上采集合规的真实委托项目,每个项目都包含原始客户需求说明(Client Brief)、输入文件(素材、规格书、测量数据等),以及被客户最终验收的专业交付物。AI Agent 需要像真正的自由职业者一样——理解需求、规划路径、操刀执行、输出成品文件。
240 个项目横跨 23 个领域,包括 3D 与 CAD 建模、建筑设计、平面设计、视频与动画制作、音频编辑、数据分析、Web 应用开发等。项目总价值超过 14 万美元,每一个都对应着真实的、已经完成的经济交易。
评测标准简单但严格:人类评审者对比 AI 的输出和人类专业交付物的质量,判断「一个理性的客户是否会接受这份 AI 的工作」。只有达到或者超过专业交付物水平的,才计为「自动化成功」。
最新成绩单:Fable 5 翻倍领先,自动化率加速曲线陡峭
RLI 最新发布的结果涉及三个新模型——Fable 5(Anthropic)、Opus 4.8(Anthropic)和 GPT-5.5(OpenAI),搭配了更强的 Agent 框架。
| | |
|---|
| | |
| | |
| | 比 GPT-5.2 的 2.08% 提升约 3 倍 |
三款新模型的评分均超过此前所有的评测模型。作为参考,RLI 发布时的最高分约为 2.5%(基于老一代 Agent 框架),此前的排行榜头部分数为 4.17%(Opus 4.6 + Claude Cowork 框架)。从 2.5% 到 16.1%,前沿自动化率在不到 8 个月内翻了四倍以上——一个清晰的信号表明 AI 经济型能力正在加速逼近市场化的门槛。
Fable 5 的评测还有一个特殊背景:由于美国政府对其访问权限进行了限制(出口管制/安全审查),评测团队仅完成了 218 个项目的评估,剩余 22 个项目未执行。但这 22 个项目均匀分布在各个领域和难度级,即使在最保守的假设下(假设 Fable 5 在所有未测试项目上都失败),其自动化率仍然高达 14.6%,依然显著领先所有其他模型。
任务示例:从戒指设计到建筑平面图
RLI 博客文章中包含详细的可视化对比,直观展示了不同模型输出与人类专业交付物的差距。
在 3D 戒指设计 任务中,客户要求将一款现有戒指的中央宝石从祖母绿切割换为马奎斯切割,交付带玫瑰金和黄金渲染的 3D 模型。Fable 5 的输出在视觉上明显优于 GPT-5.5 和 Opus 4.8——宝石的切割更精确、金属质感更真实。但评审仍指出其「爪子尖端处理粗糙」,整体仍未达到专业交付水准。这一差距说明:AI 已经从「一眼假」进步到了「远看还行,近看有破绽」的阶段。
在 2D 动画广告 任务中,要求为一家树木护理公司制作约 60 秒的逐帧动画,配配音。Fable 5 的输出在视觉质量和音频同步方面明显优于旧模型,动画角色的运动更流畅、与语音的配合更自然。但在大多数评审维度上,人类交付物在构图节奏和品牌一致性上仍占优势。
在 建筑平面图与渲染 任务中,Fable 5 的平面图准确性最高、3D 模型最详尽。博客文章特别标注了 GPT-5.5 的一个值得注意的行为:其视觉效果出色的渲染图并非来自真正的 3D 建模,而是用图像生成器伪造的。检查者打开其 3D 项目文件后发现,底层并没有真正的三维几何体——本质上它只是给了一张看起来像渲染的图片。这个案例也引出了 RLI 的另一个重要发现。
为什么 AI 评测还不能交给 AI:自动化评审高估 2-3 倍
RLI 团队做了一项实验:训练了一个自动化 LLM 评审器,让它在真实应用中打开 AI 和人类的交付物,像客户一样检查,然后判断是否可接受。这个评审器在旧模型上表现良好,但遇到新模型时大幅跑偏。
在人类评审(真实标准)下,GPT-5.5 的自动化率为 6.25%,自动化评审给出的分数却是 17.9%(约为实际的 2.9 倍)。Opus 4.8 的人类评审值为 8.33%,自动评审为 18.8%(约为实际的 2.3 倍)。排序能力尚可(Spearman ρ = 0.90),但绝对数值严重失准。
深层次的原因很直接:评估一个 RLI 交付物本身就是一项要求极高的 Agent 任务。评审者需要在正确的专业应用中打开项目文件、熟练操作那些应用软件、像客户一样做出判断——这些计算机使用(Computer Use)能力恰恰是目前 AI Agent 最弱的环节。上面 GPT-5.5 的「假渲染」案例就是典型——抓住造假的关键在于打开 3D 项目文件并检查实际的几何体,这是一个无法可靠操作软件的 LLM 评审器根本不会去做的事。
这个发现对行业有实际意义:Agent 评测正在进入一个自指难题——评估 Agent 完成任务的能力,本身就是一个 Agent 任务。 至少在当下,人类评审仍然是不可替代的基准。
意义与局限
RLI 的价值
RLI 的最重要贡献不是 16.1% 这个具体数字,而是建立了一个横跨经济价值与 AI 能力之间的直接桥梁。现有大部分 Agent 评测要么过于学术化(与真实世界脱节),要么过于垂直(只测编程或只测检索),RLI 在 23 个专业领域中的系统采样和人类评审机制,使其评测结果具有相对较高的外推价值。
8 个月四倍以上的自动化率增长也是一个值得关注的信号。如果这个趋势持续,从 16.1% 到 30% 甚至 50% 的时间窗口可能不会太长——对于自由职业平台(Upwork、Fiverr)和相关劳动市场的结构性影响需要提前关注。
局限与边界
RLI 的评测设计也有几个需要注意的边界条件。240 个项目的样本量在领域覆盖上已经不小,但每个领域内的具体任务类型仍然有限,很难说已经完整反映了一个专业领域的所有工作类型。
评测使用的是搭配强 Agent 框架的模型(而非裸模型 API 调用的输出),这意味着自动化率反映的是「模型 + Agent 框架」的整体能力上限,不一定能直接映射到用户日常使用另一个 Agent 框架时的体验。
此外,RLI 项目来源为 Upwork 等公开自由职业平台,项目本身经过筛选和脱敏处理,且项目委托方大多为英语国家客户,在语言和文化多样性上可能仍有偏差。
最终,83.9% 的任务仍然未被成功自动化。16.1% 意味着 AI 可以在约六分之一的任务上达到专业水准——这个数字足够引起重视,但离「AI 大规模替代远程劳动者」还有数量级的差距。RLI 的价值恰恰在于它量化了这个差距的缩小速度。
资源与后续
RLI 由 AI 安全中心(Center for AI Safety,简称 CAIS,由 Dan Hendrycks 领导)与 Scale AI Labs 联合开发。完整方法论、模型对比图、任务示例以及人类评审的详细数据均可在以下链接获取:
RLI 团队表示将持续更新排行榜,将新模型和新 Agent 框架的评测结果纳入。对于关注 AI Agent 经济影响的研究者、政策制定者和自由职业者来说,这是一个值得定期关注的基准。