近日国产 AI 语音模型 ViiTorVoice 在全球权威评测 Seed-TTS 中登顶综合榜首,凭借极致的发音准确率与首创的片段级编辑能力,打破了传统语音合成 “修改必重录” 的行业痛点。
该模型由云上曲率团队研发,核心指标全面超越主流竞品,更通过非自回归架构的底层创新,实现了语音内容的精细化定向修改,为短剧制作、有声书录制、广告配音等场景带来生产效率的革命性提升。
一、登顶权威评测:发音准确率刷新行业天花板
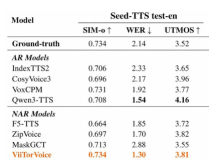
Seed-TTS 是当前业界公认严苛度最高的 TTS 标准评测体系,覆盖发音相似度、词错率、语音自然度三大核心维度。
ViiTorVoice 在评测中交出了突破性成绩:英文词错率(WER)低至 1.32,中文词错率降至 0.99,成为全球首个中文词错率突破 1.0 大关的公开模型,整体表现全面超越 Qwen3-TTS、CosyVoice3、Fish Audio 等一众主流产品。
词错率是衡量语音模型稳定性的核心指标,数值越低代表发音越准确、出现幻觉错字的概率越小。中文 0.99 的成绩意味着模型发音稳定性极强,专业术语、专有名词的还原度极高,彻底摆脱了早期 AI 语音错字频出的问题,为专业级内容生产提供了可靠的能力底座。
二、核心差异化突破:片段级局部编辑 重构生产工作流
局部定向编辑是 ViiTorVoice 最具颠覆性的能力,也是其区别于所有同类产品的核心壁垒。
传统语音合成采用 “整段生成” 模式,一旦需要修改台词中的人名、产品名、专业术语,就必须整段重录,且很难匹配原有音色、呼吸节奏、气口停顿与背景底噪,后期拼接调试的成本极高。
ViiTorVoice 实现了真正的片段级修改:用户可指定单个词语、短句或音频片段进行独立重生成,其余未修改部分的音色、情绪、节奏、底噪完全保持不变,衔接处过渡自然无拼接痕迹。该能力直接重构了语音内容的生产流程:影视后期改台词无需演员返棚重录,几十小时的有声书修正错字仅需几分钟,短剧出海只需替换关键词即可快速生成多语言版本,整体后期效率提升数十倍。
三、底层技术支撑:NAR 架构兼顾效果与推理效率
局部编辑能力的实现,源自团队在底层架构上的反常识选择。
当前主流语音模型多采用 AR 自回归架构,逐帧预测生成语音,这种模式下修改中间内容会引发链式反应,后续所有音频都会发生变化,天然不支持局部编辑,且整体推理延迟偏高。ViiTorVoice 采用 NAR 非自回归架构,基于类似 “完形填空” 的 Masked LM 思路实现局部修改:需要调整某段音频时,系统仅对目标区域 “挖空”,模型结合前后文的声学特征精准填补空缺,既保证了风格与上下文完全统一,也无需全量重新生成。
该架构同时带来了效率红利:端到端首帧生成时间压缩至 60 毫秒以内,远低于行业普遍的 150-200ms 水平;配合一致性蒸馏技术将推理步数从 32 步压缩至 4-8 步,高并发场景下计算成本显著更低,更适配规模化商业落地。
四、全场景能力补齐:情绪精细控制 + 无文本跨语种克隆
除核心编辑能力外,ViiTorVoice 在质感与适配性上也实现了全面升级。
一方面是精细化的副语言控制:引入图像领域成熟的 CFG 技术,可通过特殊 Token 精准控制笑声、叹气、哭腔等细节,还能区分不同程度的情绪、调节重音位置,彻底摆脱千篇一律的机械 AI 音色,大幅提升语音的真人质感。
另一方面是无参考文本跨语种克隆:传统语音克隆需要配套精准的文字稿,小语种场景下受语音转写准确率限制极易失败。ViiTorVoice 无需文本参考,仅通过一段纯音频即可提取说话人音色特征,直接生成中英日韩等多语种内容,完美适配短剧出海、多语言配音等商业场景。
目前 ViiTorVoice-NAR 的 1B 参数版本已正式开源,开发者可自由获取完整模型组件;商业端已实现每日数十万小时的稳定处理量,落地模式成熟。该模型的出现标志着 AI 语音正式从 “一次性生成” 进入 “可精细化编辑” 的新阶段,如同文字拥有了 Word、图片拥有了 Photoshop,语音内容首次具备了非线性编辑能力,将全面推动音频内容产业的效率升级。