
图生图AI的一致性集体翻车,常用其创作的我们该拿什么拯救?

目录
1.前言
2.无奈于模型的功能不足
3.对于一致性,我们还能补救
4. 写在最后
之所以想到写这个话题,是因为最近发现,当自己想把控多图关联性强的情节和细节的时候,就会一直受AI生图前后不一致的折磨。
真的很费时间。
尽管之前讲过banana和即梦4.0在一致性上相对良好,但只要你想创作出新意十足、起承转合完美的作品,你就会感受到迎面很多故意找茬的大兵小将,阻挠你走向“一致性”的道路。
估计在做分镜、生漫画的大家大概也同我一样,不想在各生图工具摸爬打滚、耗费一、两天后还是得到不满意的结果,想尽快找到解决此类问题的良药。
那我就把自己最近看到、测出、总结出的图生图一致性的特点和技巧分享给大家。也可以看作是抛砖引玉,大家能一起讨论和成长吧!
文章主要从模型的不足、图保持一致性的方法两方面讲述,其中会带着案例说明。为了能更好地理解文意,大家请边看这个提示词文档边浏览下文哦~
(ps:以下图片均由AI生成)
一、无奈于模型的功能不足
模型图生图整体情况
对于生成关联性较强的几张图,图生图是首选。
之前我还抱着侥幸心理——这个AI一致性不行就换一个。但现实是每个能多图参考的都换过了,即梦到可灵,到夸克,到chatgpt,再到Nano banana,结果发现:
在生成复杂图(场景、构图复杂)的情况下,没有能仅2-3次就顺利生成细节一致的AI模型。
其中可灵、夸克(具体是其中的midjourney)更是连生成场景、主体大体一样都做不到,它们的多图参考更适用于组图。
剩下的3个,无论你使用哪类提示词,你都无法让模型统一所有细节。
这里我将图生图的提示词分为两类。一类是“描述型提示词”,另一类是“变动型提示词”。前者指对你想生成的画面进行整体性描述,后者指重点写出相较于参考图变动部分的指令。
3个模型的一致性情况
即梦4.0和chatgpt 5的外形、主体尺寸等一致性问题较为突出。
它俩的限制和翻车记录如下:
即梦4.0
1.描述型提示词:
- 写提示词时,人物或重要物品需要描述,否则多人图模型不知你指的是谁。不能前一句提到B主体,后一句再写A主体说的话,否则导致气泡框指向有问题。
- 主体和物品的尺寸比例很难按照提示词变化。
- 出现小物品移位、消失、颜色变动等问题。
2.变动型提示词(尺寸问题)
- 写提示词时,主体尺寸模糊处理,结果为:主体尺寸没有太大变化。
- 写提示词时,用绝对数描述尺寸,结果为:改不了大小,且数值会在图上标示。因为没有其他物品的尺寸,模型并不清楚该数值具象化后有多大。
- 写提示词时,用相对大小描述尺寸,结果为:朝比较的物品变形。
(即梦尺寸问题:上为参考图,中和下为生成图)
chatgpt 5
1.变动型提示词
(1)尺寸问题:
- 写提示词时,主体尺寸模糊处理,结果为:尺寸轻松改好,但又产生新的尺寸和细节不一致问题。
- 写提示词时,用绝对数描述尺寸,结果为:尺寸轻松改好,图中不像即梦4.0会标记尺寸,不过还是产生新的尺寸和细节不一致问题
- 写提示词时,用相对大小描述尺寸,结果为:不像即梦4.0会变形,尺寸改好和描述相符,但产生新的细节问题。
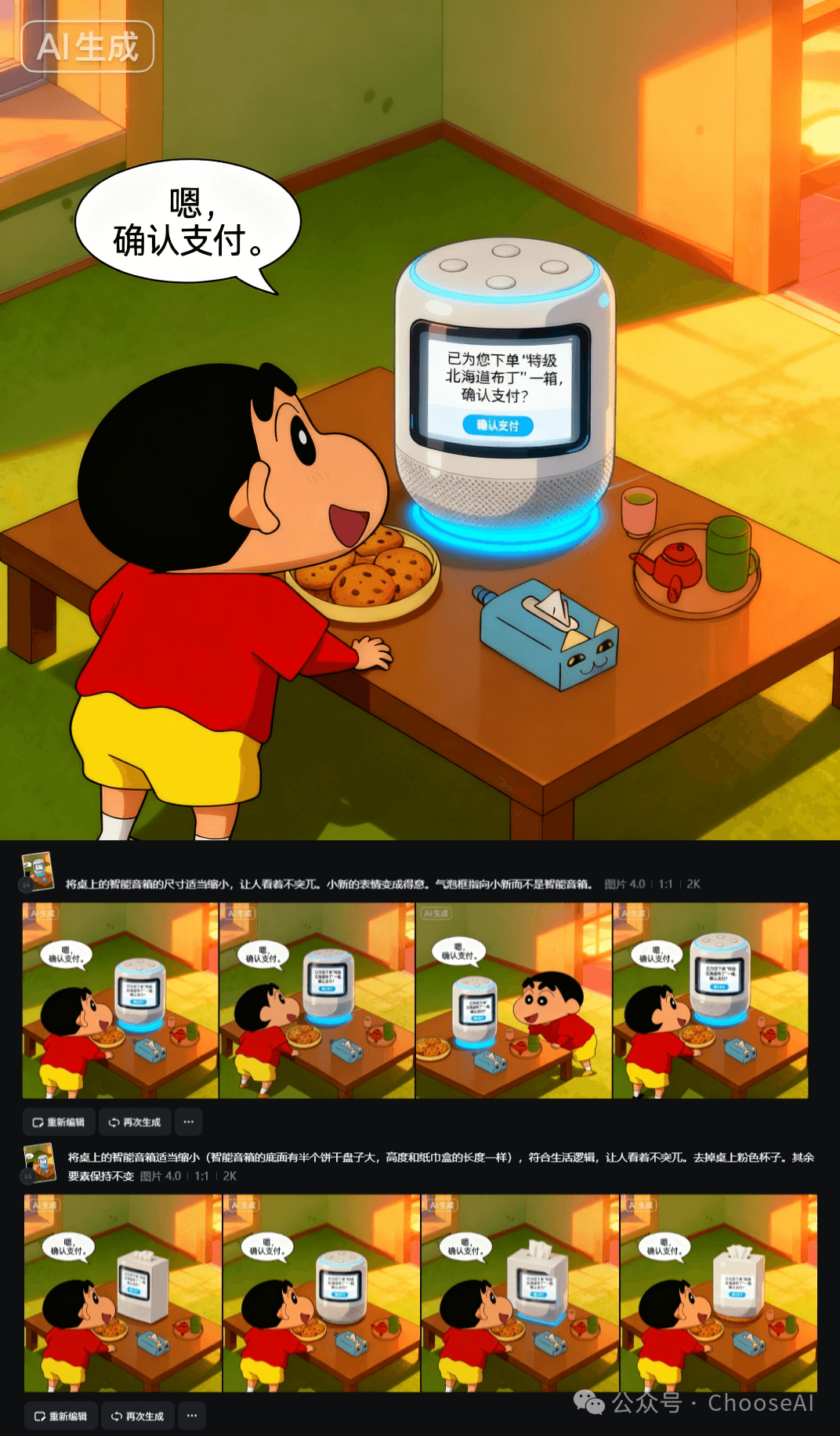
(2)语言问题:
- 智能音箱屏幕上的中文无法生成。(语言理解能力:即梦4.0>chatgpt 5>banana)

(gpt5尺寸/语言问题:第一格为参考图,其余为生成图)
与即梦4.0、chatgpt 5相比,Nano banana更适用描述型提示词。
以下是banana两种提示词的测试结果和特点:
Nano banana
1.描述型提示词:
- 提示词需要用英文。
- 效果比修改型提示词好多了,可以改变距离、姿势、表情,但表情容易崩,还有一致性问题和说话指向性等其他细节问题。
- 模型会根据具体内容自主选择文中展示的语种,此处智能音箱屏幕选择的是日文、英文。
2.修改型提示词:
- 不会调整人与物之间的距离与角度,只是在原有姿势、布局下增删元素。
- 有一致性问题和说话指向性等其他细节问题。

(banana细节问题:上为参考图,下为生成图)
二、对于一致性,我们还能补救
基础补救方法-操作上的技巧
简单来说,就是“固定提示词+绕开生图平台bug”的方式。对于没有任何编程基础的小白而言,这是最可行的方式。具体方法如下:
绝招一:图文锚点,保留核心要素和要求。
这里强调的图锚点是以三视图(正面图、侧面图、背面图)作为参考图生图,尤其当主体要素为重点的时候。这样才能让生图工具记住主体的外形、颜色、装饰等各种细节,增大细节符合预期的概率。
比如由人物三视图生成的分镜:

(上为参考图,下为生成图)
文字锚点其实就是套用提示词模板,大多是主体驱动型和环境驱动型的提示词模板,轻改动作、表情、位置、视角等需要变化的要素,保留核心结构和对应参数即可。
绝招二:顺应平台特点设计画面。
从大量实践中我们可以发现,平台对于人物外貌和着装、环境细节容易出现不一致。前者倒是可以通过三视图来规避,而后者统一就很难。
针对环境细节,我们可以换个思路——不是硬要平台将复杂的环境组成保持不变,而是设计简单的环境来规避。
简单的环境指背景单一、不会有对比明显的多样物品、不会体现空间布局的近景环境。比如“一片芦苇荡”“坐在沙发上,沙发靠着白墙,近景”,而不是“芦苇荡在河边,三边被田野地包围”“坐在客厅的沙发上,沙发靠着墙”。
尤其是室内环境,若不局限于特写或近景,很容易就展现空间布局。室内一般放置的物品数不胜数,一致性很容易就翻车。
绝招三:简化提示词批量生成分镜图。
之前我在写Nano banana、即梦4.0和混元3.0的时候有提到,这仨都可以批量生成自己写的漫画或绘本故事。故事没有对话、要求越简单,就越能顺畅生成。
所以利用这一点,想要效率高的我们不妨降低要求、抓大放小。用一句话提示词先生成一组大体符合要求的图片,然后再以此为参考图调整细节。
因为只有一句话提示词,所以你只需要把握故事类型和主体,剩下的“设计故事具体情节和细节”,就放手让AI自由发挥。
绝招四:引导观众转移注意力。
也就是说,若是因剧情需要,环境不能简单,环境的一致性问题避无可避,那么就不用纠结一致性问题,而是着眼于整体剧情,让剧情更有吸引力,从而让观众忽略一致性问题。
这更适用于为了做视频而图生图的场景。
进阶补救方法-机器语言学习
上面的基础方法总有缺陷,比如难以生成有复杂场景、多轮对话的漫画,比如难以生成需要按照固定剧本走的漫画。
若我们想要有更多的场景能适用,想要贴合商业需求,就需要上机器语言这个“武器”了。
这里重点讲json。
json的本质是静态的数据或文本,用来描述信息和意图,是一种描述性语言。它由键值对、列表、文本字符串等要素构成。
换句话说就是,在生图方面,它能以精确的数值描述图像上的各要素,实现一致性地精准把控;能打破国内平台对提示词的字数限制(即梦800字以内,可灵700字以内);能将细腻复杂的构图用机器语言结构化地展示;能一次性批量生成一致性高的图像。(案例见云文档)
“天下没有免费的午餐”。你想要一致性高、人物和场景精美的分镜图,还是得沉下心去熟悉json语言,学习能够调用编程语言程序的AI工具,如ComfyUI,或直接学习python/java等编程语言和部署流程。
三、写在最后
目前图像一致性高还不能实现。但在未来,相信AI平台生图技术能打破一致性的诸多障碍,让我们能轻松玩转分镜图。
不过我们还需谨记,逐利的商业本质始终会让“图像一致性高”、“经济成本低”、“耗时少”成为一组“不可能三角”。
而令三者兼具的本事,需要我们自己深入学习并潜心练就。
今天的提示词分享就到这里了,若你对图片高度一致性还有其他方法,欢迎在评论区分享和讨论,也欢迎大家入群交流哦~
