
StreetReaderAI:通过上下文感知多模态AI让街景变得无障碍
如今每个主要地图服务中都可用的交互式街景工具,彻底改变了人们虚拟导航和探索世界的方式——从预览路线、检查目的地到远程游览世界级旅游景点。但迄今为止,屏幕阅读器无法解读街景图像,也没有替代文本。现在我们有机会通过多模态AI和图像理解,重新定义这种沉浸式街景体验,使其对所有人都具有包容性。这最终可能让谷歌街景这样的服务——拥有超过2200亿张图像,覆盖110多个国家和地区——对盲人和低视力社区更加无障碍,提供沉浸式视觉体验,开启新的探索可能性。
在UIST'25会议上发表的论文《StreetReaderAI:使用上下文感知多模态AI让街景变得无障碍》中,我们介绍了StreetReaderAI,这是一个概念验证的无障碍街景原型,使用上下文感知的实时AI和无障碍导航控制。StreetReaderAI由盲人和明眼无障碍研究人员团队迭代设计,借鉴了无障碍第一人称游戏和导航工具的先前工作,如Shades of Doom、BlindSquare和SoundScape。

核心功能主要功能包括:
对附近道路、交叉路口和地点的实时AI生成描述
与多模态AI代理就场景和当地地理进行动态对话
使用语音命令或键盘快捷键在全景图像之间进行无障碍平移和移动
StreetReaderAI通过将地理信息源和用户当前视野输入Gemini,提供街景场景的上下文感知描述。
StreetReaderAI使用Gemini Live提供关于场景和当地地理特征的实时互动对话。

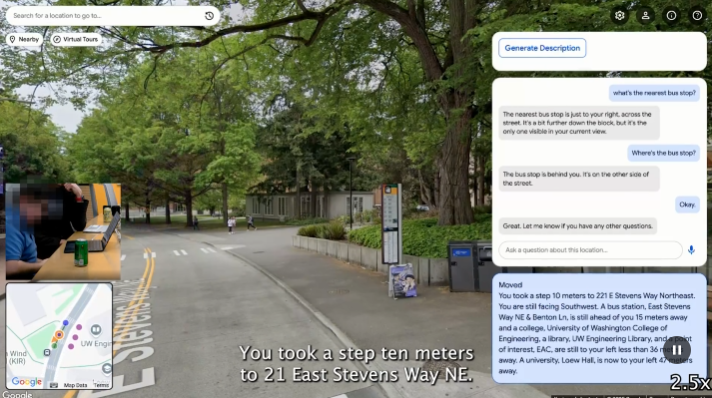
在StreetReaderAI中导航
StreetReaderAI提供沉浸式的第一人称探索体验,就像以音频作为主要界面的视频游戏一样。
StreetReaderAI通过键盘和语音交互提供无缝导航。用户可以使用左右方向键移动视野来探索周围环境。当用户平移时,StreetReaderAI分享音频反馈,将当前朝向说成基本方位或中间方位(例如"现在面向:北方"或"东北方")。它还表达用户是否可以向前移动,以及他们当前是否面向附近的地标或地点。
要移动,用户可以使用向上箭头"虚拟行走",或使用向下箭头后退。当用户在虚拟街景中移动时,StreetReaderAI描述用户行走的距离和关键地理信息,如附近的地点。用户还可以使用"跳跃"或"传送"功能快速移动到新位置。
StreetReaderAI如何充当虚拟导游
StreetReaderAI的核心是两个由Gemini支持的底层AI子系统:AI描述器和AI聊天。两个子系统都接收静态提示和可选的用户配置文件,以及关于用户当前位置的动态信息,如附近地点、道路信息和当前视野图像(即街景中显示的内容)。
AI描述器
AI描述器作为上下文感知的场景描述工具,结合关于用户虚拟位置的动态地理信息以及当前街景图像的分析,生成实时音频描述。
它有两种模式:强调盲人行人导航和安全的"默认"提示,以及提供额外旅游信息(如历史和建筑背景)的"导游"提示。我们还使用Gemini预测可能对盲人或低视力旅行者感兴趣的、特定于当前场景和当地地理的后续问题。
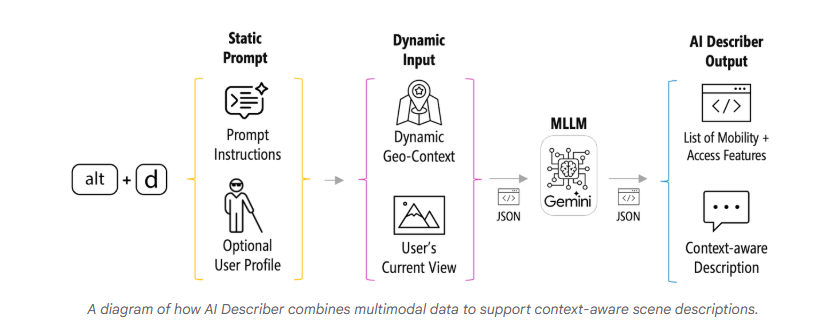
AI聊天
AI聊天建立在AI描述器基础上,但允许用户询问关于当前视图、过去视图和附近地理的问题。聊天代理使用谷歌的多模态实时API,支持实时交互、函数调用,并临时保留单个会话中所有交互的内存。我们跟踪并发送每次平移或移动交互,以及用户的当前视图和地理上下文(如附近地点、当前朝向)。
AI聊天的强大之处在于它能够保持用户会话的临时"记忆"——上下文窗口设置为最多1,048,576个输入标记,大致相当于超过4000张输入图像。由于AI聊天在每个虚拟步骤中接收用户的视图和位置,它收集关于用户位置和上下文的信息。用户可以虚拟走过一个公交车站,转过一个角落,然后问:"等等,那个公交车站在哪里?"代理可以回忆其先前的上下文,分析当前的地理输入,并回答:"公交车站在你身后,大约12米远。"
与盲人用户测试StreetReaderAI
为了评估StreetReaderAI,我们与11名盲人屏幕阅读器用户进行了现场实验室研究。在会话期间,参与者了解了StreetReaderAI并使用它探索多个位置,评估前往目的地的潜在步行路线。
总体而言,参与者对StreetReaderAI反应积极,在李克特量表(1-7分,1表示"完全无用",7表示"非常有用")上对总体实用性的评分为6.4(中位数=7;标准差=0.9),强调了虚拟导航和AI之间的相互作用、交互式AI聊天界面的无缝性以及所提供信息的价值。参与者的定性反馈一致强调了StreetReaderAI在导航方面的重大无障碍进步,指出现有的街景工具缺乏这种水平的无障碍性。交互式AI聊天功能也被描述为使关于街道和地点的对话既有趣又有帮助。
在研究期间,参与者访问了超过350个全景,并发出了超过1000个AI请求。有趣的是,AI聊天的使用频率是AI描述器的六倍,表明对个性化、对话式查询的明显偏好。虽然参与者发现StreetReaderAI有价值,并熟练地将虚拟世界导航与AI交互结合起来,但仍有改进空间:参与者有时在正确定向、区分AI响应的真实性以及确定AI知识的限制方面遇到困难。
研究结果
作为首个无障碍街景系统的研究,我们的研究还首次分析了盲人对街景图像提出的问题类型。我们分析了所有917次AI聊天交互,并为每次交互标注了最多三个标签,这些标签来自23个问题类型类别的涌现列表。四种最常见的问题类型包括:
空间定位:27.0%的参与者最关心物体的位置和距离,例如"公交车站离我站的地方有多远?"和"垃圾桶在长凳的哪一边?"
物体存在:26.5%的参与者查询人行道、障碍物和门等关键特征的存在;"这里有人行横道吗?"
一般描述:18.4%的参与者通过请求当前视图的摘要来开始AI聊天,经常问"我面前有什么?"
物体/地点位置:14.9%的参与者询问事物在哪里,例如"最近的交叉路口在哪里?"或"你能帮我找到门吗?"
StreetReaderAI的准确性
由于StreetReaderAI严重依赖AI,一个关键挑战是响应准确性。在参与者向AI聊天提出的816个问题中:
703个(86.3%)得到了正确回答
32个(3.9%)是错误的
其余要么部分正确(26个;3.2%),要么AI拒绝回答(54个;6.6%)
在32个错误响应中:
20个(62.5%)是假阴性,例如声称自行车架不存在但实际存在
12个(37.5%)是误识别(例如将黄色减速带解释为人行横道)或因AI聊天尚未在街景中看到目标而导致的其他错误
需要更多工作来探索StreetReaderAI在其他环境和实验室设置之外的表现。
下一步是什么?
StreetReaderAI是让街景工具对所有人无障碍的有希望的第一步。我们的研究突出了盲人用户从街景图像中想要什么信息、询问什么问题,以及多模态AI回答这些问题的潜力。
有几个机会可以扩展这项工作:
走向地理视觉代理:我们设想一个更自主的AI聊天代理,可以自己探索。例如,用户可以问"这条路上的下一个公交车站是什么?"代理可以自动导航街景网络,找到车站,分析其特征(长凳、遮蔽物),然后报告。
支持路线规划:同样,StreetReaderAI还不支持完整的起点到终点路由。想象一下问"从最近的地铁站到图书馆的步行路线是什么样的?"未来的AI代理可以"预先行走"路线,分析每张街景图像以生成盲人友好的摘要,注意潜在障碍,并确定图书馆门的确切位置。
更丰富的音频界面:StreetReaderAI的主要输出是语音。我们还在探索更丰富的非语言反馈,包括空间化音频和从图像本身合成的完全沉浸式3D音频声景。
虽然是"概念验证"研究原型,但StreetReaderAI有助于展示使沉浸式街景环境无障碍的潜力。
本文来源于:StreetReaderAI: Towards making street view accessible via context-aware multimodal AI