
Adobe新推出的"修正AI"功能可改变配音情感表达
在Adobe MAX创意大会期间的演示中,Adobe展示了一段配有平实、略显乏味旁白的短视频。这段旁白本身并无特别之处,但在调出文字稿、选中文本并从预设情感列表中进行选择后,声音表现完全改变了——从平淡变得自信,又从自信转为耳语,整个过程仅需几秒钟。
Adobe将这项技术称为"修正AI"(Corrective AI),这是该公司在洛杉矶举行的年度MAX创意大会期间的MAX Sneaks展示环节中演示的众多功能之一。Sneaks是Adobe展示其正在开发的未来技术和原型的平台,其中许多功能最终会在几个月内进入Adobe完整的创意套件。
在今年的MAX大会上,Adobe为Firefly发布了生成式语音功能,不仅可以使用多种预设声音,还能添加情感标签来改变语调。这项修正AI功能将该功能引入了更实用的工作流程中。创作者无需使用完全由AI生成的声音,而是可以对现有的配音表演进行润色调整。
音频轨道智能分离技术
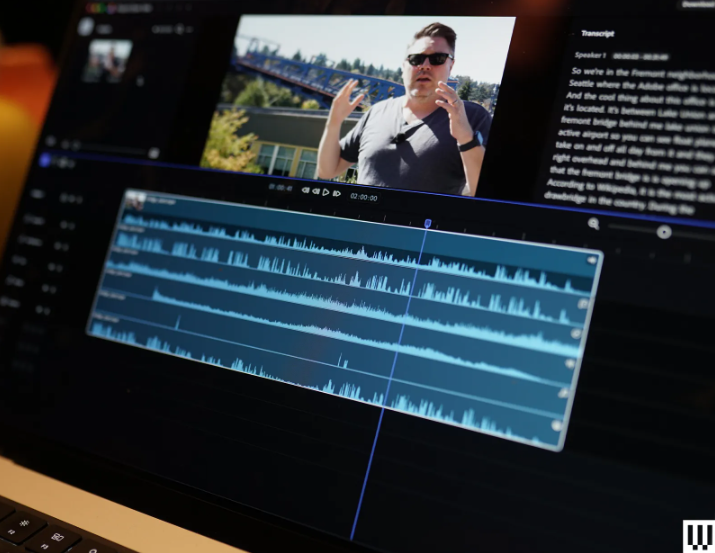
Adobe工程师Lee Brimelow还展示了AI如何从单个音轨中提取不同部分以创建多个轨道。这项名为Project Clean Take的Sneaks原型目前限于五个轨道,但可以分离人声、环境噪音、音效等。AI模型分离轨道的准确性令人惊讶。在一个示例中,演示了某人在吊桥前说话的场景,吊桥铃声完全盖过了主持人的声音。运行AI模型后,铃声消失了。更值得一提的是,通过单独调整这些分离轨道的音量,还可以将铃声重新加回来。
在另一个示例中,Adobe演示了这项技术如何在创作者在公共场所拍摄时发挥作用,特别是当背景播放有授权音乐时。众所周知,未经授权的音乐很容易通过YouTube等平台的自动系统导致版权警告。在演示中,Adobe的AI模型能够分离音乐,用Adobe Stock中的类似曲目替换,并应用效果以赋予其原始曲目的混响和氛围感,所有这些只需几次点击即可完成。
实用性导向的AI工具
这些功能利用AI解决视频编辑和创作者的日常问题,帮助修复损坏的音频或节省重新录制配音表演的时间和麻烦。Adobe还将在Sneaks展示会上展示新的生成式AI功能。对于音效设计师,该公司展示了其AI模型如何自动分析视频并添加音效,据称这些音效均由AI生成,但可安全用于商业用途。

Adobe工程师Oriol Nieto加载了一段包含多个场景和旁白但没有音效的短视频。AI模型分析了视频并将其分解为场景,应用情感标签和每个场景的描述。然后,音效就出现了。AI模型识别出一个带有闹钟的场景,并自动创建了音效。它识别出主角(在这个例子中是一只章鱼)驾驶汽车的场景,并添加了关门的音效。
效果并非完美。闹钟声音不够真实,在两个角色拥抱的场景中,AI模型添加了不自然的衣物摩擦声,效果不佳。Adobe没有手动编辑,而是使用了对话界面(类似ChatGPT)来描述更改。在汽车场景中,没有来自汽车的环境音。演示者通过对话界面要求AI模型为场景添加汽车音效,而不是手动选择场景。系统成功找到了场景,生成了音效,并将其完美放置。
从原型到产品的演进
这些实验性功能目前尚未推出,但它们通常会进入Adobe的产品套件。例如,去年在Sneaks上展示的Harmonize功能——一项在Photoshop中自动以准确颜色和光照将素材放置在场景中的功能——现在已经集成到Photoshop中。预计这些新功能将在2026年某个时候推出。
对行业的影响
Adobe发布这些功能的时机,正值视频游戏配音演员结束了近一年的罢工,以确保获得围绕AI的保护——当游戏开发商想要通过AI重现配音演员的声音或形象时,公司需要获得同意并提供披露协议。配音演员一直在为AI将对该行业产生的影响做准备,而Adobe的新功能,即使不是从头开始生成配音,也是AI正在推动创意产业转变的又一标志。
本文来源于:Adobe’s ‘Corrective AI’ Can Change the Emotions of a Voice-Over