
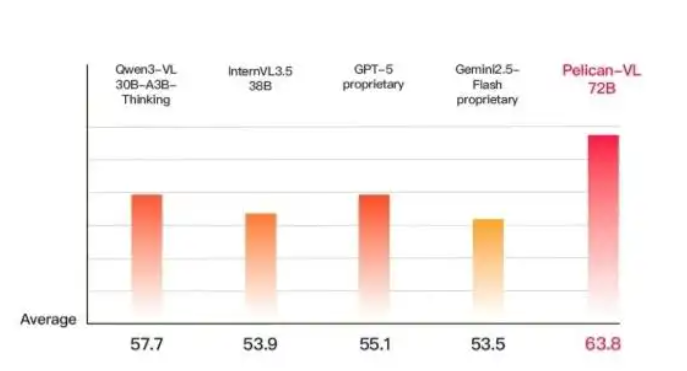
国产具身大模型登顶全球!Pelican-VL性能超越GPT-5 15.79%
2025年11月13日,北京人形机器人创新中心扔下一颗“技术核弹”——正式开源具身智能多模态大模型 Pelican-VL 1.0。
这不是又一个普通的大模型发布,而是一次真正意义上的国产突破:参数规模覆盖7B到72B,训练动用超1000块A800 GPU,单次检查点耗时超5万GPU小时,性能不仅碾压同级别开源模型,甚至在多项具身任务上超越GPT-5、Gemini等闭源巨头。
更关键的是——它完全开源。
代码、权重、推理框架全部开放,意味着全球开发者都能免费使用这个“机器人通用大脑”。
一夜之间,中国在具身智能赛道,从追赶者变成了领跑者。
什么是Pelican-VL?不只是VLM,更是机器人的“行动中枢”
Pelican-VL 1.0被官方称为“最大规模的开源具身多模态大脑模型”。但它的意义远不止参数数字。
传统视觉语言模型(VLM)擅长“看图说话”——给你一张照片,它能描述内容;给你一段指令,它能生成图像。
但Pelican-VL的目标是“看图做事”。
当人类说“把红苹果放进竹篮”,它不仅要识别“红苹果”和“竹篮”的位置,还要判断:
苹果是否易碎?需轻拿轻放;
篮子开口朝哪?手该从哪个角度伸入;
如果第一次没对准,如何微调手腕姿态?
这种从“感知”到“决策”再到“动作规划”的全链路能力,才是真正的具身智能(Embodied Intelligence)。
Pelican-VL正是为此而生。
DPPO训练法:让AI学会“刻意练习”,像人类一样复盘进步
Pelican-VL之所以强大,核心在于其独创的 DPPO(Deliberate Practice Policy Optimization)训练范式。
想象一个学生做数学题:第一次做错,老师指出错误,他总结经验,下次同类题型就能答对。DPPO正是模拟这一过程。
训练分为两个阶段循环进行:
第一阶段:强化学习(RL)发现弱点
模型在模拟环境中执行任务,系统自动记录失败案例——比如抓取滑落、路径碰撞、指令误解。通过多样化奖励机制,模型“意识到”自己在哪类场景下表现不佳。
第二阶段:监督微调(SFT)针对性补强
团队将这些失败样本与高质量成功案例混合,重新训练模型。如同老师给学生整理“错题本”,让AI在薄弱环节反复练习,直至掌握。
整个过程通过难度感知采样和滚动日志记录实现闭环迭代。
结果?
模型在保持通用能力的同时,具身任务性能提升20.3%,远超基线。
这种“自我纠错+持续进化”的机制,让Pelican-VL具备了类似人类的元认知能力——不仅能完成任务,还能反思“为什么没做好”。
三大核心能力:让机器人真正“活”在物理世界中
Pelican-VL的强大,体现在三个维度的深度融合:
多模态理解与推理
它处理的不只是静态图像,而是包含时间维度的视频流。
在厨房场景中,它能分辨“切菜板上的番茄”和“冰箱里的番茄”,并根据任务动态调整操作策略。
空间-时间认知
得益于数万小时视频训练,模型能理解动作的先后逻辑。
例如:“先移开挡路的牛奶盒,再拿后面的咖啡杯”——这种常识性规划,正是当前多数AI缺失的。
具身交互与泛化
最惊艳的是其零样本操作能力。
面对从未见过的物体(如软质海绵、充气气球),Pelican-VL能基于物理常识预测抓取力度,并生成安全操作路径。
测试显示,它在“轻柔抓取”任务中,显著优于现有开源模型。
更令人振奋的是,它还能实现长程任务分解。
面对“请把鞋放到鞋架、垃圾扔进垃圾桶、脏衣服放进洗衣机”这样的复合指令,模型会自动拆解为多个子任务,依次执行并反馈进度——这已接近人类助理的水平。
开源即赋能:降低90%研发门槛,加速产业落地
Pelican-VL的真正革命性,在于开源策略。
过去,具身智能研发门槛极高:企业需自建数据集、训练集群、部署框架,动辄投入数千万。而如今,任何团队只需:
下载Pelican-VL 7B或72B模型;
接入自家机器人硬件;
用少量场景数据微调。
几天内,就能拥有一个具备高级空间推理与操作能力的“机器人大脑”。
官方已在Hugging Face、ModelScope、GitHub同步开放全部资源,并提供LoRA微调脚本。
这意味着高校实验室、创业公司甚至个人开发者,都能站在巨人肩膀上快速验证想法。
正如一位业内人士所言:“以前我们是在黑暗中摸索造轮子,现在Pelican-VL直接给了我们一辆车。”