
Nano Banana Pro:Google DeepMind 的新一代图像生成与编辑模型
Google的AI攻势还在继续。前几天Gemini 3 Pro刚在前端领域掀起波澜,今天就轮到设计行业了。刚发布的Nano Banana Pro(Gemini 3 Pro Image)在图像生成能力上又来了次重拳出击,初级设计师的饭碗,可能真得悬了。
不再「瞎猜」,Nano Banana Pro终于学会了先思考再画画
这次更新的核心功能包括:最高4K分辨率输出、支持对话式多轮编辑、最多可将14张图像组合成1张、还集成了Google搜索能力提供实时知识支持。
Nano Banana本来就以角色一致性强和对话编辑见长,但Pro版本的进化在于——它把Gemini 3的深度思考能力完整接入了图像生成流程。生成一张图之前,会先做物理模拟和逻辑推演,而不只是凭视觉模式"胡猜"。
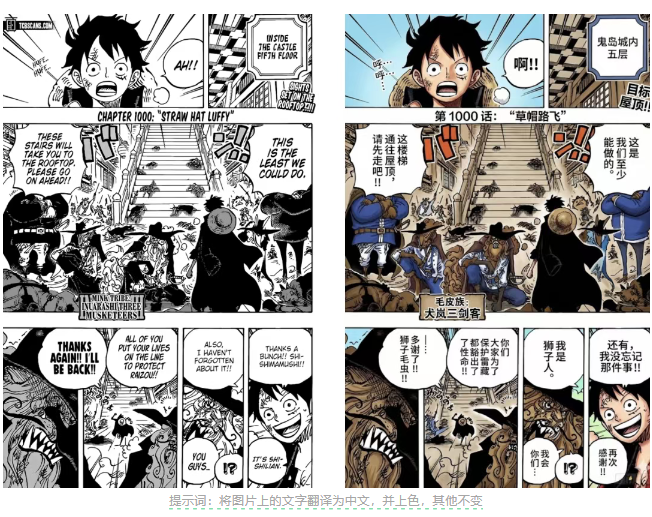
跨模态理解在Nano Banana Pro身上体现得更彻底了。凭借Gemini 3增强的多语言推理能力,你可以直接生成多种语言文字,或者一键本地化、翻译内容。
比如给模型一页漫画,让它上色并把气泡里的英文翻成中文。Pro版本上色干净,光影自然,文字识别准确,英文排版也和气泡形状严丝合缝。从识别到翻译再到重排一气呵成,表现得就像真的在"理解"这张图。

设计师过去需要反复调整的多语言漫画、国际化海报,现在可以直接让AI一步到位。这种从识别、翻译到设计的连贯处理方式,正是原生多模态架构最有威力的一面。
文字生成能力经实测表现也不错,尽管偶尔需要多试几次。64k的输入Token上限意味着它能理解极长的文本提示词——无论是详细的分镜脚本,还是复杂的多语言排版需求。
针对前代分辨率偏低的问题,Nano Banana Pro把画质直接拉到4K,还允许自由设定更多长宽比。电影海报、宽屏壁纸、纵向分镜,都能直接生成。
更厉害的是它支持最多14张输入图像的组合编辑,同时保持最多5个角色的外貌一致。配合多轮对话能力,你可以不断调整、融合多个素材,直到达到理想效果。把草图变成产品,或将蓝图转换成逼真的3D建筑,都能轻松实现。
专业级创意控制能力也很到位。你可以选择、微调或变换图像中的任何部分,从调整镜头角度、改变风格到应用高级调色,甚至改变场景光照——把白天变成夜晚,或创造散景效果。这些过去需要在Photoshop里精细操作的活儿,现在一句话就行。
搜索+生成=?Google给出了终极答案
如果说搜索是Gemini 3的「左脑」,那图像生成就是「右脑」。
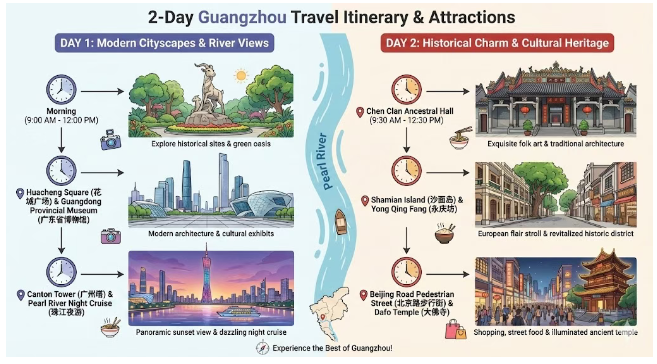
Nano Banana Pro架构中最具颠覆性的能力,其实是搜索增强功能(Grounding with Search)。传统搜索是用户搜索、引擎给链接、用户点进网站。而Pro版本直接把搜索结果转化为可视化内容。
当你要求生成「在广州旅游的2天行程可视化」时,Nano Banana Pro生成的图包含详细行程地图、中英文注释、景点等。再比如它能根据提示词从搜索中获取最新天气状况,再把温度、风力、湿度、天气趋势等数据转化为鲜明、富有设计感的视觉内容。
这项能力之所以重要,是因为它让创造过程具备了事实基础、实时性和可验证性。搜索不愧是Google的看家本领,无论技术积累的厚度,还是理解力上都已经领先一个身位。
产品定位上,Google采用了双模型策略:旧版Nano Banana用于快速有趣的日常编辑,Pro版本则专注复杂构图与顶级画质的专业需求。你可以根据场景自由选择。
对消费者和学生来说,Nano Banana Pro已在Gemini应用中全球开放,只需选择「生成图像」并启用「Thinking(思考)」模式即可使用。免费用户有限额度,超出后会自动切回原版。Google AI Plus、Pro和Ultra订阅用户则有更高额度。在美国地区,Google搜索的AI模式中,Pro与Ultra用户已经能体验到。NotebookLM中的Pro版本也面向全球订阅用户开放。
值得注意的是,Google在AI透明度问题上采取了双重策略。所有AI生成内容都会嵌入不可见的SynthID数字水印,你现在可以在Gemini应用中直接上传图像,询问它是否由Google AI生成。这项能力很快会扩展到音频与视频。
既然Nano Banana Pro已经强大到这个地步,那问题来了——普通人该如何最大化发挥它的能力?
Google DeepMind的产品经理Bea Alessio给出了详细使用指南。最基本的用法当然是随便说一句话,让模型自己猜你想要什么。但如果想达到专业水准,就需要像导演一样思考。

一个完整的提示词应该包含六个要素:主体(谁或什么)、构图(如何取景)、动作(正在发生什么)、场景(在哪里)、风格(什么审美)、编辑指令(如何修改)。
想要更精细的控制,还需要进一步明确:画幅比例(9:16竖版海报还是21:9电影宽屏)、镜头参数(低角度、浅景深f/1.8)、光线细节(逆光的黄金时刻,拉长阴影)、调色方向(电影级调色,偏青绿色调)、以及具体的文字内容和样式。
这种「摄影指导式」的提示词写法,正是Nano Banana Pro和传统图像生成模型的分水岭。因为它真能理解这些专业术语,并准确转化为视觉输出。
看到这里,再回头看Google这几天连环发布的产品,就不难明白它想传达什么了。
无论是前几天发布的Gemini 3 Pro预览版,还是今天亮相的Nano Banana Pro,Google试图向世人证明:通往AGI(通用人工智能)的道路,必须是多模态原生的。只有一个能看、能听、能理解结构、能处理逻辑的模型,才可能对世界进行完整的「思考」。
从技术层面看,Nano Banana系列让图像生成正式进入了「先理解再表达」的阶段。当AI开始理解迷宫的路径、物体的结构、文字的含义甚至UI的交互逻辑时,它就不再只是个画图工具,而是具备视觉思维能力的智能体。
从商业层面看,极低的推理成本和生成式UI的出现,将彻底改变内容生产和信息分发的逻辑。过去的互联网由一个个固定网页构成,而未来的互联网更可能是一块块随你需求即时生长的界面。设计不再只是人的手艺,界面也不再是团队层层打磨的成果。越来越多的视觉内容,会先交给AI,再由人去补充或微调。
Google显然已经提前看见了那个新世界,并且开始把入口推到所有人面前。这场AI图像生成的革命,才刚刚开始。