
全球首个!小米开源融合具身智驾大模型MiMo-Embodied
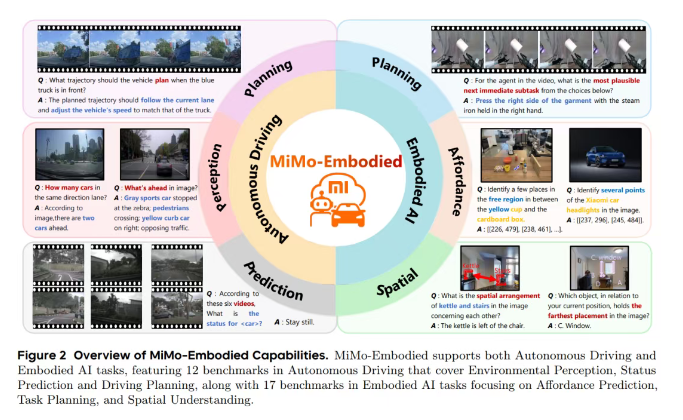
发布多款自研大模型后,小米在具身智能领域又交出了一份重磅成果。小米具身智能团队发布首篇论文,提出统一具身智能与自动驾驶的新模型MiMo-Embodied。这个模型在17项具身任务和12项自动驾驶任务中都拿到了领先成绩,更关键的是,它从工程层面证明了机器人和自动驾驶这两个长期分离的技术领域,完全可以在同一框架下实现统一建模。
小米智驾团队的郝孝帅是论文核心第一作者,智驾团队首席科学家陈龙博士担任project leader。这是陈龙团队的首个重大成果。因为模型基于罗福莉团队之前发布的MiMo-VL进行了continue-train,所以作者栏里会看到罗福莉的名字。之前有媒体误解成罗福莉的首个小米成果,还引发了当事人发朋友圈澄清。
多任务统领式领先
论文主要围绕具身智能和自动驾驶两个方向做了系统实验,整体结果相当亮眼。简单说就是:MiMo-Embodied在17个具身智能任务和12个自动驾驶任务里,都拿到了全面领先的表现,多数关键基准上都排第一。
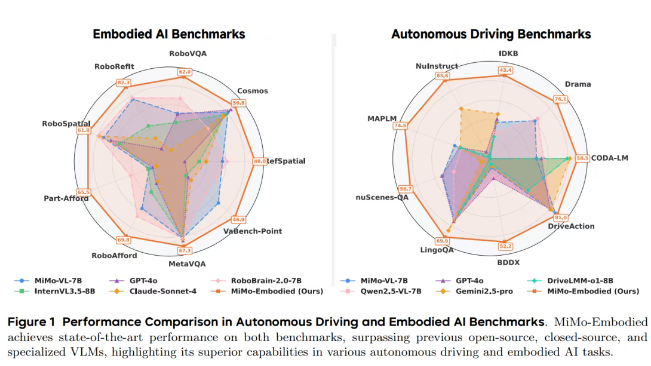
具身智能这块,评测涵盖了可供性推断、任务规划和空间理解三个能力维度。
可供性推断主要测试模型能不能正确理解物体的使用方式,比如识别物体上能操作的部位、精确指出指定位置、判断哪些区域可以放东西,或者从一堆相似物体里找到符合描述的那个。在这类任务中,MiMo-Embodied在五个主流基准上表现都很突出——RoboRefIt能从高度相似的物体中准确定位目标,Part-Afford能识别可操作部件,VABench-Point能根据文字精确给出坐标,整体达到当前最优水平。
任务规划方面测的是模型根据情境推断下一步行动的能力,像是根据视频判断任务后续步骤、从多个候选动作中选对的那个,或者推断接下来可能发生什么。MiMo-Embodied在RoboVQA、Cosmos-Reason1和EgoPlan2等基准里都处于领先位置,说明它在行动推理和任务结构理解上确实有两把刷子。
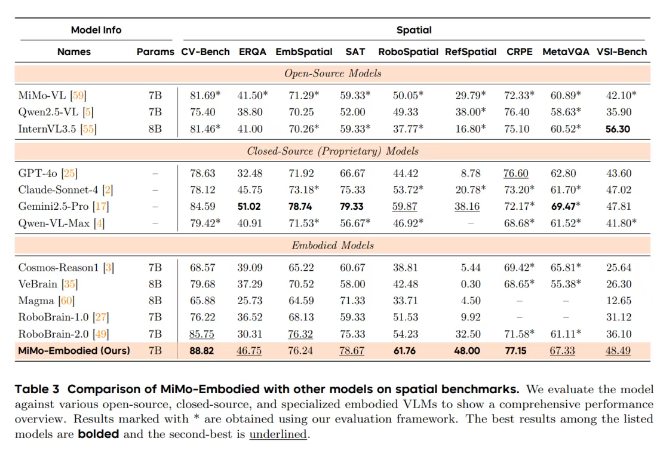
空间理解任务要求模型对场景中的空间关系有准确把握,包括判断物体间的相对方位、在图像中定位对象、输出精确坐标,或者回答涉及空间推理的问题。在九个代表性测试中,MiMo-Embodied在CV-Bench、RoboSpatial、RefSpatial与CRPE-relation等核心基准上拿到最高分,在EmbSpatial和SAT等任务里也保持在第一梯队。
自动驾驶方面,实验覆盖了场景感知、行为预测和驾驶规划三个核心模块。
场景感知要求模型看清路上的车辆、行人和交通标志,描述场景内容,识别潜在风险,输出关键目标位置。MiMo-Embodied在CODA-LM等复杂场景理解任务中的表现跟专用模型相当甚至更好,在DRAMA里对关键物体的定位精度最高,在OmniDrive和MME-RealWorld中也保持领先。
行为预测要求模型推测其他交通参与者可能采取的动作,比如车辆会不会变道、会不会让行,或者从多视角画面里理解整体交通流动趋势。MiMo-Embodied在MME-RealWorld和DriveLM等基准里表现稳定且领先,对动态交通场景理解得挺到位。
驾驶规划则要求模型给出车辆应该采取的动作并解释决策依据,同时保证遵守交通规则、规避风险。MiMo-Embodied在多个核心基准上取得领先,包括在LingoQA中准确解释驾驶行为,在DriveLM中从多视角场景推导合理规划,在MAPLM中理解道路结构参与决策,在BDD-X中清晰说明驾驶理由,整体表现甚至超过一些专门为自动驾驶设计的模型。
从单域到跨域的四阶段训练框架
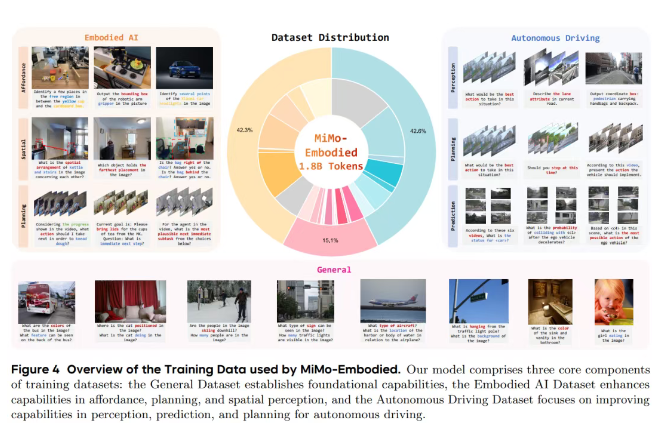
除了实验结果,团队还构建了一套四阶段训练流程,让模型能力从最初的具身理解逐步拓展到自动驾驶决策,并进一步发展出可解释的推理能力和更高输出精度。
这四个阶段都以罗福莉所属的Xiaomi LLM-Core(大语言核心团队)推出的MiMo-VL作为统一基础模型展开。整个训练体系按能力逐级递进来设计,每个阶段都为下一阶段打基础,形成一套连续且可扩展的演进路径。

第一阶段主要是具身智能相关的监督训练,数据覆盖可供性推断、任务规划和空间理解等任务。模型先学会看懂物体结构、识别可操作部位、理解场景空间关系,并能对任务过程做正确的下一步推断。
第二阶段专门引入自动驾驶领域的监督训练。模型开始学习处理复杂交通场景,训练数据包括多视角相机画面、驾驶视频、自动驾驶问答、关键目标坐标标注以及道路结构相关知识。这让模型掌握了动态场景分析、意图预测以及驾驶决策等关键能力。
第三阶段加入链式思维训练,就是让模型学会"把推理过程说出来"。训练数据里有明确推理步骤,模型被引导按"观察场景→分析要素→提出候选→给出理由→得出结论"的顺序组织回答。这样模型就能自洽地解释判断逻辑,不管是具身任务还是驾驶任务,都能给出清晰可读的推理链条。
第四阶段进行强化学习微调,进一步提升模型在细节层面的准确度。比如多选题根据对错给奖励,定位任务通过IoU分数提供精细反馈,推理回答用格式模板严格约束。通过这些规则化奖励机制,模型在坐标定位精度、推理质量及细节判断能力上都有明显增强。
打通两个世界的第一步
这项工作的价值不只在于性能领先,而在于它解决了长期困扰业界的核心难题:机器人和自动驾驶本来属于两个完全不同的世界,现在第一次被放进了同一个大脑里。
以前的模型要么专门做室内具身任务,要么专门做自动驾驶,两个方向从场景到感知到动作都完全割裂,彼此几乎没法共享能力。但MiMo-Embodied的实验结果证明,底层那些关键智能能力——空间理解、因果推理、动态场景分析,其实可以跨域迁移。机器人理解桌面物体的方式能帮汽车理解路口,汽车处理交通动态的能力也能让机器人更好地规划任务步骤。
"智能体"的边界第一次被打通了。
团队还专门构建了一个前所未有的大规模评测体系:17个具身智能基准加12个自动驾驶基准,覆盖可供性、规划、空间理解,以及感知、预测、驾驶决策等多维能力。模型在这么复杂全面的体系下依旧保持稳定领先,证明它不是"补短板",而是真正具备跨领域泛化智能。
更关键的是,MiMo-Embodied提供了一种可复制的范式。论文提出的四阶段训练路线:先学具身,再学驾驶,再叠加链式推理,最后用强化学习抠细节,实际上就是一条通往"通用具身智能体"的训练路径。它告诉行业:智能体能力不必分散在不同模型中,可以像上课一样逐层积累,让统一模型在多种复杂场景中都保持稳定表现。
从产业角度看,这更像一次"开锁"动作。小米把跨域智能这把钥匙直接扔给了开源社区,意味着未来小团队也能在这套基础上做改造,做出既能开车又能操作机械臂的多场景智能体。电动车越来越像"带轮子的智能体",机器人越来越像"带四肢的智能体",而MiMo-Embodied的出现,让这两条原本平行的技术路线第一次有机会汇流。
难得的是,这不是个性能勉强够用的概念模型,而是在17个具身测试加12个自动驾驶测试里都能打、还能赢的大模型,连不少闭源私有模型都被它压了一头。这项工作向行业明确证明:自动驾驶与具身智能的能力可以在同一体系中训练、评测和集成部署,这种统一方式为未来智能体发展打开了新方向,可能会重新塑造多场景智能系统的整体格局。