
StepFun AI 发布全新音频大语言模型 Step-Audio-R1,音频推理能力显著提升
近年以思维链为代表的扩展推理技术,在文本和视觉领域取得了巨大成功。
但是在音频领域,一个令人困惑的现象始终存在:音频语言模型似乎无法从思维链中受益,甚至表现出“想得越多,错得越多”的“反常缩放”现象。
目前大多数音频模型在训练时主要依赖于文本数据,导致它们的推理过程更像是阅读文字,而非实际聆听声音。StepFun团队称这一现象为“文本替代推理”。
StepFun AI团队近日推出了新的音频大语言模型Step-Audio-R1,这个模型在生成推理时可以有效利用计算资源,充分解决了当前音频AI模型在处理长推理链时准确性下降的问题。
研究团队指出,这个问题不是音频模型固有的局限,而是由于训练过程中采用了文本替代推理的方式。
为了应对这一问题,Step-Audio-R1要求模型在生成答案时必须基于音频证据进行推理。这种做法通过一种称为模态化推理蒸馏的训练方法来实现,这个方法特别选取并提炼出与音频特征相关的推理轨迹。
在冷启动阶段,团队使用了500万例样本,覆盖了超过1亿个文本标记和40亿个音频配对数据。在这个阶段,模型学习如何生成对音频和文本都有用的推理,还建立了基本的推理能力。
训练过程中,Step-Audio-R1模型经历了监督冷启动阶段和强化学习阶段,涉及文本和音频任务的混合。
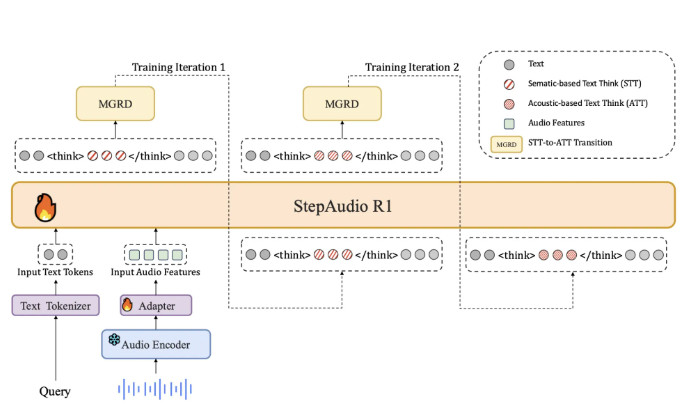
在架构上,Step-Audio-R1基于Qwen2音频编码器,对原始波形进行处理,并通过音频适配器将输出下采样至12.5Hz。然后,Qwen2.532B解码器消耗音频特征并生成文本。模型在生成答案时,始终会在特定标签内生成明确的推理块,这样可以确保推理的结构和内容得以优化,同时还不影响任务的准确性。
同时Step-Audio-R1通过一个降采样率为2的适配器,将音频编码器的输出与LLM解码器连接起来。
通过多轮模态化推理蒸馏,研究团队从音频问题中提取出真实的声学特征,并用强化学习进一步优化模型的推理能力。Step-Audio-R1在多个音频理解与推理基准测试中表现出色,其综合得分接近行业领先的Gemini3Pro模型。
StepAudio-R1能够生成真正基于声学特征的推理链,而不是基于转录文本进行思考。实验证明,StepAudio-R1在语音、环境音和音乐等多个维度的音频理解与推理基准测试中,超越Gemini 2.5 Pro,比肩Gemini 3 Pro。
StepAudio-R1的诞生,为构建能够跨越所有感官进行深度思考的真正多模态推理系统,开辟了一条全新的道路。