
阿里推出单张图像转LoRA工具DiffSynth-Studio:一张图炼出一个 LoRA
阿里通义实验室发布DiffSynth-Studio Qwen-Image-i2L,首创单张图像转LoRA工具,支持风格提取(2.4B参数)和细节增强(7.6B)。基于Qwen-VL生成LoRA模块,可无缝集成Stable Diffusion。Hugging Face下载量已破万,democratize个性化生成,适用于艺术/电商领域。
当其他大厂还在用API锁住核心能力时,阿里却选择了最激进的开源策略。
一张图炼出一个 LoRA
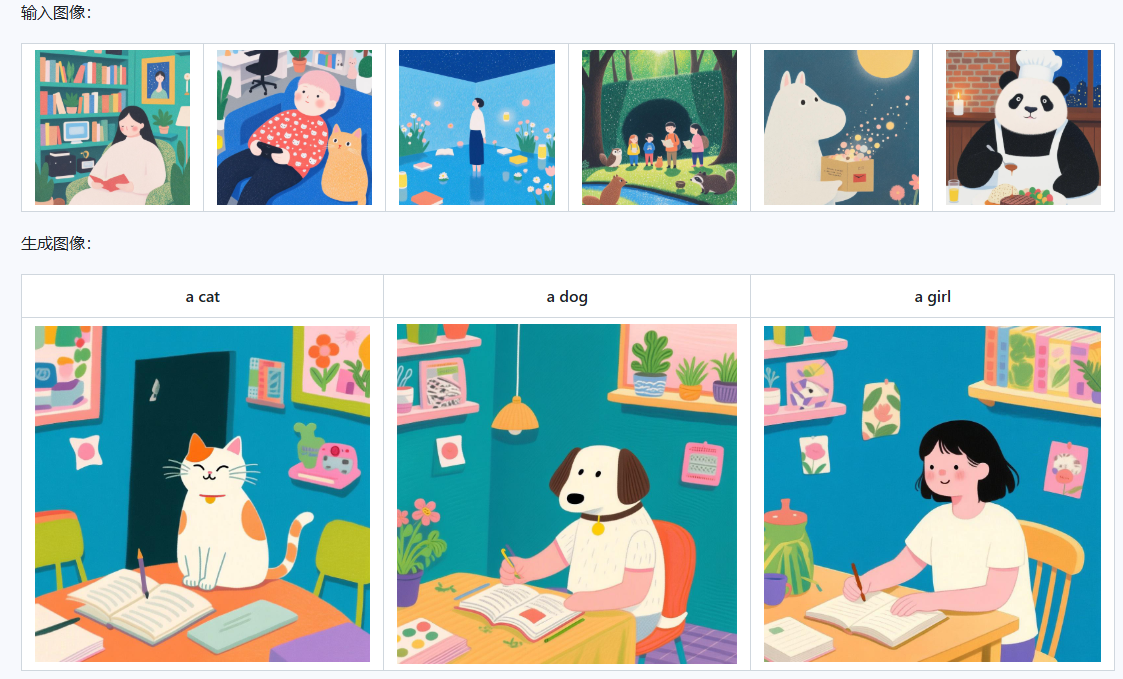
Qwen-Image-i2L这款全球首个单图训练LoRA的开源工具,彻底颠覆了AI风格迁移的游戏规则。只需一张图片,3分钟生成专属LoRA模型,无缝接入Stable Diffusion等主流工具,让个性化创作如呼吸般简单。这场AI艺术平权运动,正在悄然改变内容创作的底层逻辑。
传统上,如果你想把某个画师的风格迁移到自己的生成模型里,大概率要经历: 收集几十上百张图 → 清洗数据 → 配 LoRA 训练脚本 → 等半天训练 → 调参到怀疑人生。
Qwen-Image-i2L 直接把这条链路砍成一句话:“给它一张图,它就能自动生成一个 LoRA。”
你只需要提供一张图:可以是某个画风、角色形象、艺术作品,模型会自动分析这张图里的视觉特征,然后帮你生成一个轻量级 LoRA 模块。 之后你就能把这个 LoRA 加载到其他生成模型中使用,实现“单图风格迁移”,相当于给你的模型装上一个“风格插件”。
Qwen-Image-i2L 的底层是一个多模型特征提取体系:SigLIP2 + DINOv3 + Qwen-VL组合拳。
简单理解,它会对一张图做一次“结构化体检”: 把整体风格、美学气质抽出来,把主要内容、构图关系分离出来,把色调、光影、细节纹理编码成特征。
最后把这些东西压缩进一个 LoRA 模块,既保留风格,又保持轻量级,方便加载和分发。 这意味着,你不是在“复制整张图”,而是在提取一组“可学习、可迁移的视觉 DNA”。
四款模型精准适配场景
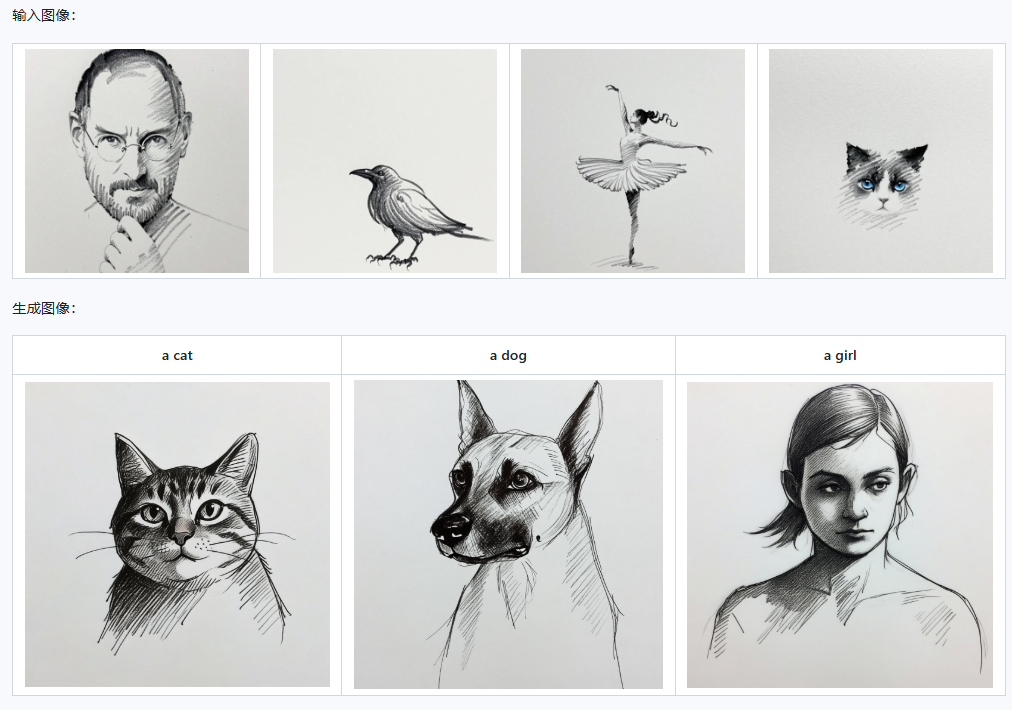
风格模式(2.4B参数):专攻纯美学迁移,如将水彩笔触应用于新图,或让照片秒变油画质感;
粗粒度模式(7.9B参数):内容+风格双抓取,快速重构场景(如把城市街景变赛博朋克风);
精细模式(7.6B参数):支持1024x1024高分辨率,细节控必备(如生成逼真的动物毛发或建筑砖块);
偏见模式(30M参数):企业级应用神器,确保输出与Qwen-Image原生风格一致,避免品牌跑偏。
对普通创作者来说,其实可以简单理解为:先用粗粒度+精细搞定“像不像”+“够不够精致”,再视需求加偏见模块让风格更统一。