
字节跳动Seedance 1.5 Pro在Dreamina上线
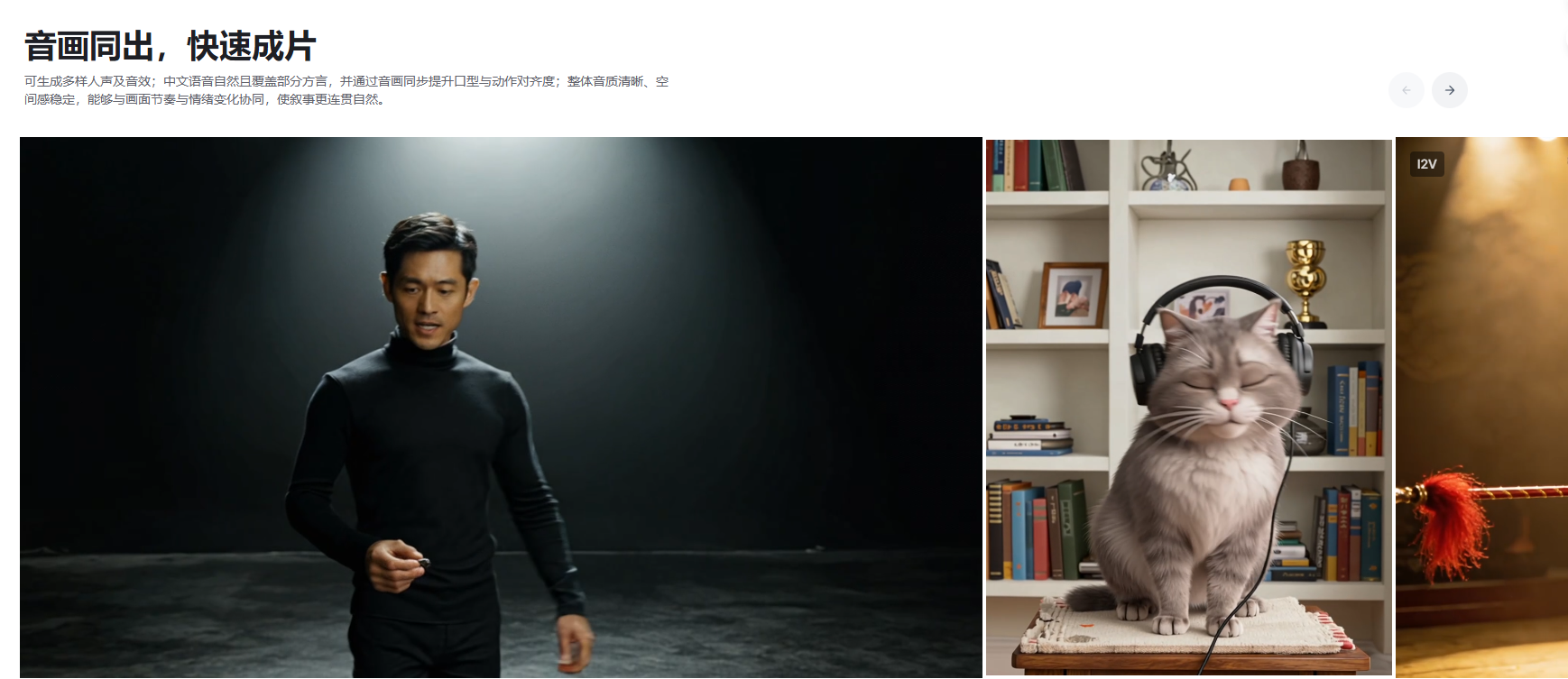
近日,北京的一场发布会可能将重新定义“短视频”的创作逻辑。字节跳动正式揭晓其新一代音视频联合生成模型 Seedance 1.5 Pro。它的核心突破在于一个听起来简单、实现却极具挑战的目标:实现音与画100%的精准同步生成。这意味着,AI不仅能“看图说话”或“听声画画”,更能同时生成高度匹配、富有情感层次的动态画面与人声表演,将音视频创作从“拼接”时代带入“原生”时代。
在Seedance1.0版本中,模型更侧重改善模型表现的“下限”,优化了运动生成的稳定性;
而Seedance1.5pro除了支持音频同步生成外,还致力于提升视觉冲击力和运动效果的“上限”。
通过采用更加大胆的技术方案,Seedance1.5pro在视听协同、视觉张力和叙事协调性等方面实现突破:
精准音画同步与多语言、方言支持:模型在生成中实现了较高的视听一致性,提升了角色的口型、语调与表演节奏的拟合精度。
模型原生支持多语种和特色方言口音,能够捕捉其独有的语音韵律与情感张力。
电影级运镜控制与动态张力:模型具备自发的镜头调度能力,可执行长镜头跟随、希区柯克变焦等高难度运镜,同时还能实现电影级的画面衔接与专业影调,提升了视频的动态张力。
语义理解与叙事协调性增强:通过增强语义理解,模型实现了对叙事语境的较好解析。
它提升了音视频段落的整体叙事协调性,为专业级内容创作提供支撑。
字节跳动Seed表示,在综合评测中,Seedance1.5pro各项关键能力处于“业界前列”。
目前,Seedance1.5pro已上线即梦AI和豆包。
地址如下:https://seed.bytedance.com/seedance1_5_pro
当AI成为最懂你的联合创作者 Seedance 1.5 Pro 的发布,标志着一个音视频“原生智能生成”时代的开启。AI不再是辅助剪辑的工具,而是一位能从剧本(文本/图像)开始,与你共同完成表演、运镜、叙事的联合创作者。创作的边界,正被这项技术以我们想象不到的速度拓宽。