
Meta发布SAM Audio:首个统一多模态新音频分离模型
近日,Meta AI推出了SAM Audio,这是一个创新的统一模型,能够从复杂的音频混合中隔离出任何所需的声音。SAM Audio通过利用文本、视觉或时间提示来实现这一目标,为音频处理带来了前所未有的灵活性。
为了推动该技术的发展,Meta AI向社区开放了SAM Audio模型,同时提供了感知编码器模型、基准测试和相关研究论文。这些资源将帮助研究人员和开发者探索新的表达形式,并构建以前难以实现的应用程序。
文本提示:用户可以通过简单的文字描述来指定需要分离的声音。
视觉提示:结合图像或视频帧中的信息,精准定位并提取特定声源。
时间提示:利用时间范围标记,准确地从音频中剪辑出特定时间段内的声音。
SAM Audio的推出标志着音频处理领域的一大进步,有望在音乐制作、语音识别、环境音效等领域带来革命性的变化。
目前我们可以直接在Meta官方的Demo演示页面免费体验,首页有许多现成的模板,我们可以直接拿来用,亲测效果相当炸裂。
那么废话不多说,下面直接上实测案例。
SAM3实测演示
我准备了一段打斗视频,这个视频里人物的动作幅度很大,出招也很快,我个人感觉处理起来难度不算低。

首先我想试试它是否真的可以把我视频里的人物给识别出来,于是我选了个简单遮罩的模板,在输入框里输入了“people”这个单词,然后点击应用模板
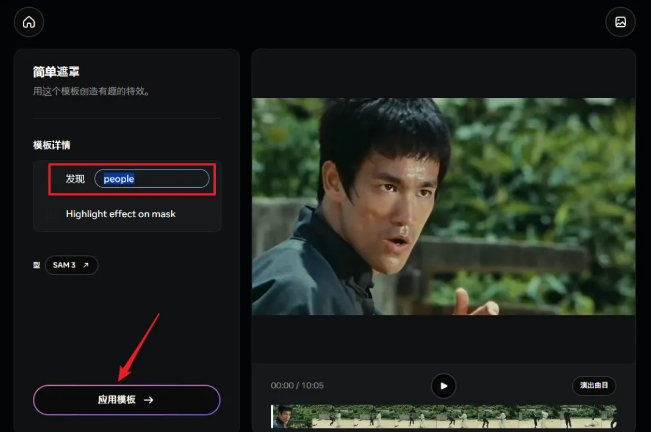
稍加等待过后,最终效果让我颇为震惊,感觉它就像是带了自瞄,始终都能把人物完美框选
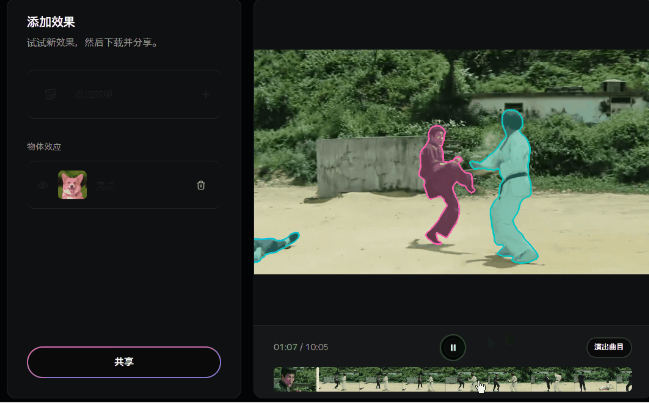
亲测,就算人再多点也无妨~

果然,Meta诚不欺我。
下面我直接上强度,单独新建了一个视频编辑项目,还是用同样的方法把人物给精准识别出来。
与使用模板不同的是,单独创建项目可以更好的对视频进行后续处理,你甚至可以挨个选择想要处理的视频人物及任何元素。
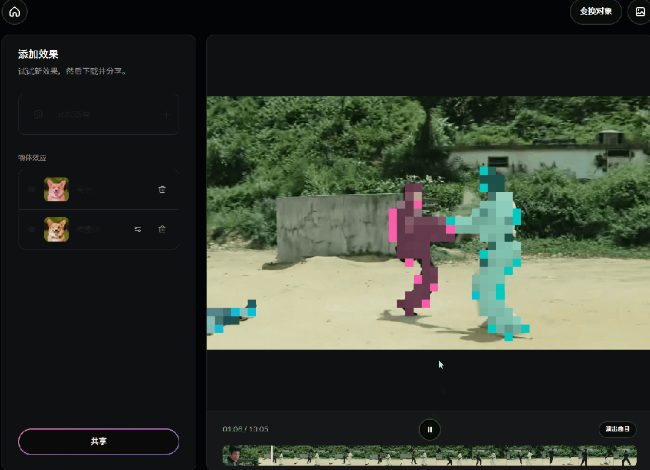
比如把视频里的人物打上厚厚的马赛克
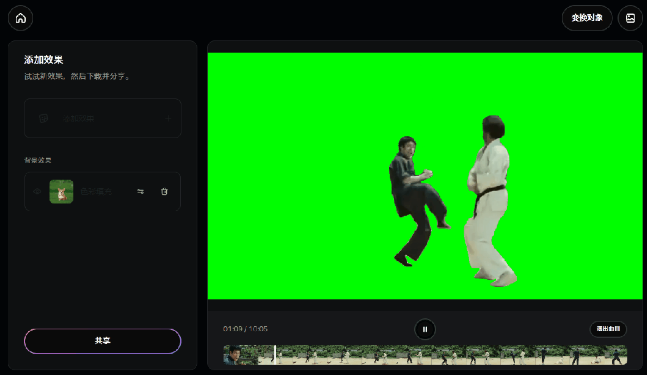
或者再简单粗暴点,直接把视频里的目标给抠出来,再加个绿幕
当然,以上只是一些简单的尝试,它也有很多实际应用场景。
比如给视频里的汽车车牌打码

另外,它的演示页面提供了许多现成的特效模板,感兴趣的可以自行尝试~
处理完成的视频可以直接无水印导出,而这整个过程我甚至都没有登录,不得不说,Meta这次着实让我有点刮目相看了
其实早在2023年,Meta就发布了SAM一代模型,但当时还只能处理图像,现在则是真正做到了“分割一切”。
如何使用?
说了这么多,估计大家已经迫不及待的想去体验一番了,那么下面给大家整理好了相关的一切链接,赶紧收藏吧~
项目主页:
ai.meta.com/sam3
在线体验地址:
aidemos.meta.com/segment-anything
Github地址:
github.com/facebookresearch/sam3
Hugging Face:
huggingface.co/facebook/sam3
魔搭社区:
modelscope.cn/models/facebook/sam3
不得不说,Meta这波开源确实很顶,SAM3最可怕的地方不在于能把人抠得多干净,而在于它让“精准识别”这件事变得极其廉价且高效。