
豆包1.8好用么?Seed-1.8实测测评!
2025-12-19 11:38
175
12月18日,在火山引擎2025冬季Force原动力大会上,火山引擎总裁谭待正式发布了豆包大模型1.8。
据介绍,豆包1.8有更强的Agent能力、升级的多模态理解和更灵活的上下文管理。据大会上公布的数据,截至今年12月,豆包大模型日均调用量已经超过50万亿,相比去年12月增长超过十倍,对比发布初则是实现了417倍的增长。
Seed-1.8重回第一梯队其实没有什么悬念,但惊喜之处在于,这一次Seed团队掌握了高效推理能力,Seed-1.8(medium)可以仅使用5K Token就达到Seed-1.6需要15K Token才能获得的智力,搭配2块钱的起步价,对常规任务来说,性价比十分优秀,与DeepSeek系列殊途同归。而high档位的推理可以充分利用更多思考预算去冲击更高智力,十分逼近北美御三家。
考虑到Seed-1.8同样优秀的视觉理解,多模态能力,字节家也有只差半代的生图,生视频模型。把Seed看做小号Gemini并不为过。
逻辑成绩:
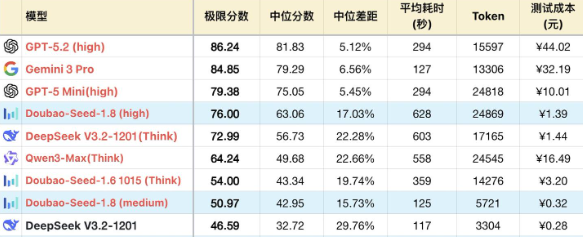
1、表格为了突出对比关系,仅展示部分可对照模型,不是完整排序。
2、题目及测试方式,参见:大语言模型-逻辑能力横评25-11月榜(Gemini 3/GPT-5.1/Opus 4.5),新增#53、#54题。
下面对比Seed-1.8与前代Seed-1.6,以及能力接近的其他模型。没有明确说明时,Seed-1.8指的是high档位。
改进:
长链推理:
复杂长链推理问题中,模型需要保持长时间高精度工作,准确召回上文出现的中间数据,抑制幻觉。长链推理是头部模型的决战场地。Seed-1.8可以在比1.6翻倍的CoT过程中保持高度专注,逐步验证和排除不同解分支,最终准确找到正确解。如果Seed团队愿意,或许也可以进一步拉高思考预算,推出一版类似GPT 5.2 Pro那样的研究用模型,来解决更复杂困难的科学问题。不过现实的一面是,Seed-1.8在复杂问题上体现的人类思辨能力较少,大部分是依托强专注力进行暴力穷举。而上位的Gemini 3 Pro,GPT-5.2取得更高成绩,只需要Seed-1.8 60%的Token,证明了更强的硬智力水平。
信息提取:
在信息提取类问题上,Seed-1.8表现尚佳,精度高,但代价是推理并不高效,会在CoT中完整复述原文细节来做记录和标记,一个10K文本的简单信息抓取问题,Seed-1.8需要花费2倍Token来完成。这意味着,如果增加输入文本长度,Seed-1.8未必可以保持高精度抓取。并且当Seed-1.8的思考档位降低,CoT长度限制提高时,其抓取精度就会大幅下降。不开推理模式,提取能力几乎不可用。作为对比,Gemini 3 Pro只使用4K Token来处理相同问题。
编程能力:
编程能力是豆包系列模型的传统短板,但最近也有起色,上个月发布的Code模型就代表了Seed团队在编程方向上的探索成果。而Seed-1.8基本继承了Code模型的编程能力,在编程基本功测试中成绩相近。但需要指出,Seed-1.8离头部编程特优模型差距还十分显著,尤其工程思维不足。用于从0到1 vibe coding构建可以一用,但难以作为复杂工程的主模型使用。
不足:
多轮能力:作为一款针对Agent优化的模型,其多轮能力理所当然是有提高的。但这只是跟前代Seed-1.6比,从几乎不可用提升到基本可用水平。但如果跟多轮标杆模型比较,则还存在明显不足,无法稳定的跟踪任务目标,无法稳定的缩小与目标的差距。轮次到十几轮后,思路开始发散。
空间智力:在涉及平面二维或三维空间的问题上,Seed-1.8显著缺乏训练。较为简单的空间物体旋转(#4题),Seed-1.8表现和前代差别不大。复杂的空间形状问题,Seed-1.8没有正确思路,无法稳定解答。而GPT-5 Mini是有思路,只是精度不高。Gemini 3 Pro/Flash则明显在这类问题上有独到优势。
赛博史官曰:
Gemini 2.5 Pro展示了强大统一的多模态模型在应用场景里的可能性,Gemini 3 Pro/Flash则将这种可能性进一步巩固,形成独特的护城河。反观国模产品线,大部分还在文本模型生态圈中厮杀。字节Seed团队从去年就明确要做统一多模态的决策无疑是正确的,只不过Seed模型的历史欠账太多,即便有多模态,也难担大任。Seed-1.8还有遗憾,并不完美。而随着短板一个个被补齐,多轮强化,编程特训,知识扩充,Seed模型这颗属于下一个时代的恒星也终将被点亮。字节系积累的无尽的互联网资源将化作核聚变原料,支撑这颗恒星爆发出耀眼的光芒。
0
好文章,需要你的鼓励