
Google发布T5Gemma2,新一代多模态编码器-解码器模型!
2025-12-19 18:57
200
临近过年了,谷歌的发布突然变得特别密集。昨天刚发布全球性价比最高的模型Gemini 3 Flash。

当大家都以为谷歌今年的模型发布已经收官的时候,谷歌却又掏出了一个让大家都意想不到的模型更新:T5Gemma 2。
T5Gemma系列模型似乎没能给大众留下什么深刻印象。
今年7月,谷歌第一次发布了T5Gemma模型系列,并且一口气发布了32个模型。
从模型名称可以看出,T5Gemma系列模型与T5息息相关。T5(Text-to-Text Transfer Transformer)是Google在2019年提出的一种编码器-解码器(Encoder–Decoder)大模型框架,「编解码器大模型」的思想源头,几乎都能追溯到T5。
T5Gemma使用了「适应(adaptation)」技术将已经完成预训练的仅解码器模型转换为编码器-解码器架构。
但遗憾的是,「编码器-解码器架构」始终没有成为大模型世界的主流,在「仅解码器」大语言模型快速迭代的大背景下难逃逐渐被边缘化的命运。
谷歌是为数不多仍在坚持编码器-解码器架构大模型的玩家。
今年上半年,谷歌发布了开放模型Gemma 3系列,性能强大,反响热烈,衍生出许多基于Gemma 3系列模型的优秀工作。这次更新的T5Gemma 2模型正是其中之一。
简而言之:T5Gemma 2,是谷歌新一代编码器-解码器模型,是首个多模态和长上下文的编码器-解码器模型,建立在Gemma 3的强大功能之上。
主要创新和升级功能包括:
支持多模态
扩展长上下文
开箱即用,支持140多种语言
效率提升的架构创新
同时,谷歌向社区发布了270M–270M、1B–1B以及4B–4B三种规模的预训练模型,是社区中首个支持超长上下文(最高128K)的高性能编解码器大语言模型。
T5Gemma 2延续了T5Gemma的「适应(adaptation)」训练路线:将一个预训练的纯解码器模型适配为编解码器模型;同时,底座采用Gemma 3模型,通过结合Gemma 3中的关键创新,将这一技术扩展到了视觉-语言模型领域。
新架构,新能力
高效的架构创新
T5Gemma 2不仅仅是一次再训练。它在继承Gemma 3系列许多强大特性的同时,还进行了重要的架构变更:
1.词嵌入绑定
在编码器与解码器之间共享词嵌入参数。这一设计显著降低了模型的总体参数量,使我们能够在相同的显存/内存占用下容纳更多有效能力——这对全新的270M–270M紧凑模型尤为关键。
2.合并注意力
在解码器中,我们采用了合并注意力机制,将自注意力(self-attention)与交叉注意力(cross-attention)融合为单一、统一的注意力层。这一做法减少了模型参数和架构复杂度,提升了模型并行化效率,同时也有利于推理性能的提升。
新一代模型能力
得益于Gemma 3的能力,T5Gemma 2在模型能力上实现了显著升级:
1.多模态能力
T5Gemma 2模型能够同时理解和处理图像与文本。通过引入一个高效的视觉编码器,模型可以自然地完成视觉问答和多模态推理等任务。
2.超长上下文
我们对上下文窗口进行了大幅扩展。借助Gemma 3的局部—全局交替注意力机制(alternating local and global attention),T5Gemma 2能够支持最长达128K token的上下文输入。
3.大规模多语言支持
通过在规模更大、更加多样化的数据集上进行训练,T5Gemma 2开箱即用即可支持140多种语言。
性能结果
T5Gemma 2为紧凑型编码器-解码器模型设定了新的标准,在关键能力领域表现出色,继承了Gemma 3架构强大的多模态和长上下文特性。
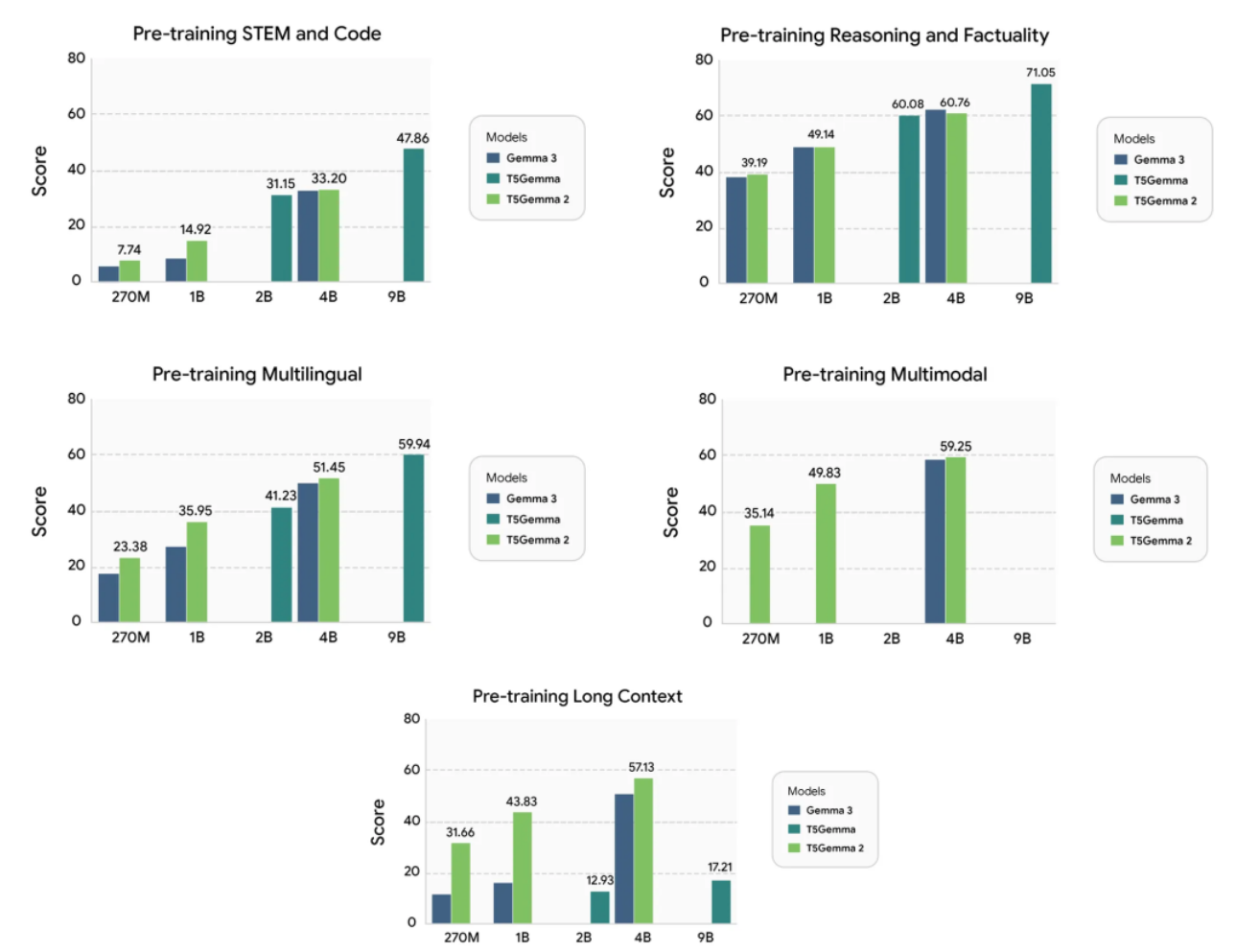
Gemma 3、T5Gemma和T5Gemma 2在五个独特能力上的预训练性能。
如上图所示,T5Gemma 2展现出以下突出优势:
强大的多模态性能:在多个基准测试中超越Gemma 3。原本仅支持文本的Gemma 3基础模型(270M与1B)成功适配为高效的多模态编解码器模型。
卓越的长上下文能力:相较于Gemma 3和T5Gemma,在生成质量上取得了显著提升。通过引入独立的编码器,T5Gemma 2在处理长上下文问题时表现更佳。
全面提升的通用能力:在代码、推理和多语言等任务上,T5Gemma 2整体上均优于其对应规模的Gemma 3模型。
训练后性能。这里的结果仅用于说明,研究团队对T5Gemma 2进行了最小的SFT,未使用RL。另外请注意,预训练和训练后基准是不同的,因此不同图表中的分数不可比较。
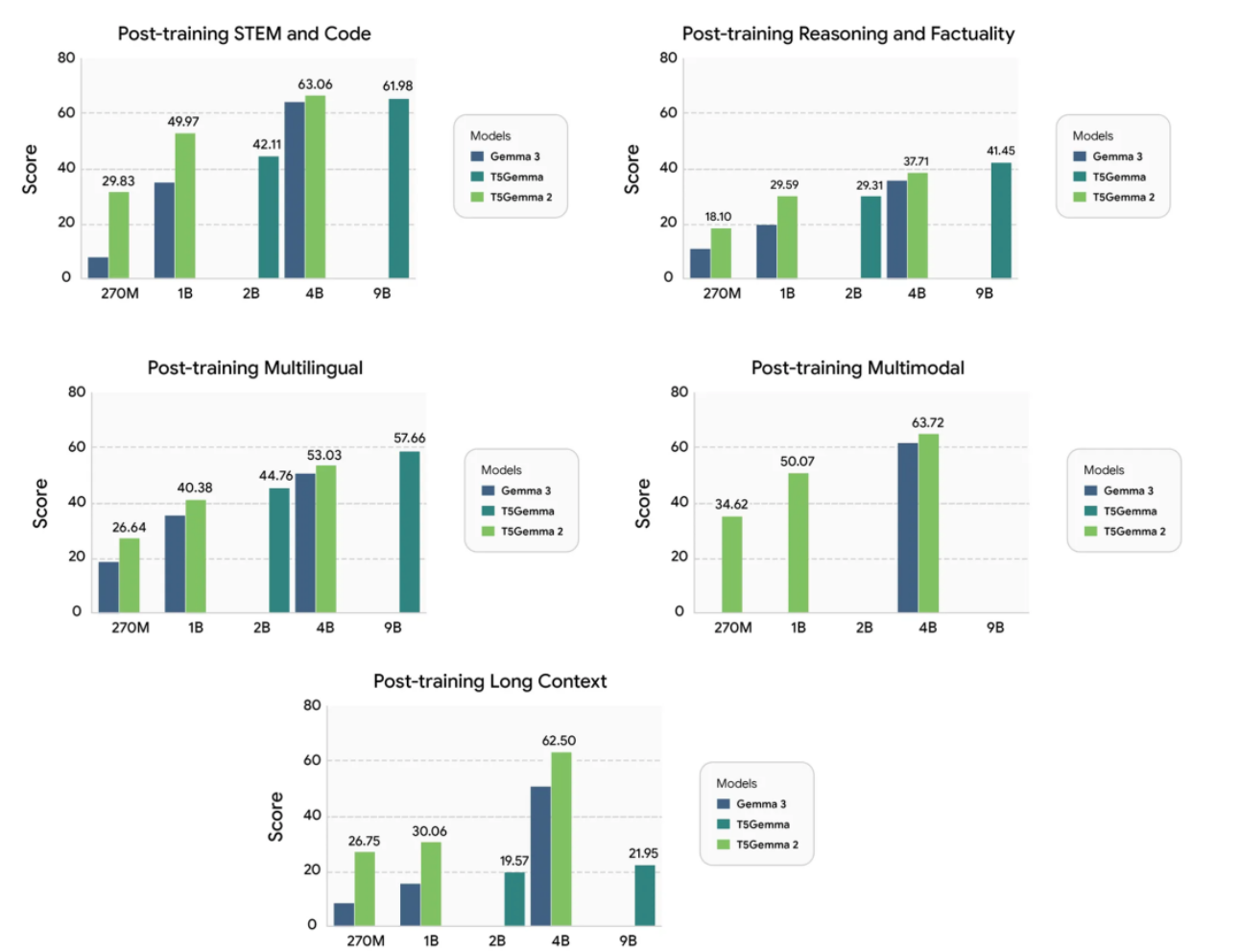
Gemma 3、T5Gemma与T5Gemma 2的详细预训练结果。需要注意的是,Gemma 3的270M与1B模型,以及T5Gemma的2B–2B和9B–9B模型均为纯文本模型。带有“∗”标记的结果为近似值,无法在不同论文之间直接比较。
Gemma 3、T5Gemma与T5Gemma 2的详细后训练结果。尽管T5Gemma 2的后训练过程相对轻量化,但其在大多数能力维度上仍然优于Gemma 3。
实验结果表明,该适配策略在不同模型架构与不同模态上都具有良好的通用性,同时也验证了编解码器架构在长上下文建模方面的独特优势。与T5Gemma类似,T5Gemma 2在预训练阶段的性能可达到或超过其Gemma 3对应模型,而在后训练阶段则取得了显著更优的表现。
我们能看到,编码器-解码器架构下的大模型并不弱于仅解码器架构的模型,甚至具备自己独特的优势。
谷歌继续坚持的编码器-解码器架构,能否打破被边缘化的现状,让我们拭目以待。
0
好文章,需要你的鼓励