
苹果UniGen 1.5发布:图像理解+生成+编辑三合一
2025-12-21 21:04
140
苹果研究团队近日发布多模态AI模型UniGen 1.5,首次在单一系统中实现图像理解、生成与编辑三大功能的统一。
该模型采用统一架构,通过强化图像理解能力提升生成效果的精准度。
为解决图像编辑中指令理解不准的问题,团队首创“编辑指令对齐”后训练阶段,要求模型先根据原图和指令预测目标图像的文本描述,再生成图像,从而深度内化用户意图,提高修改准确率。
与主要依赖不同模型分别处理任务的传统方案不同,UniGen 1.5最大的突破在于构建了一个统一的框架,仅凭一个模型即可同时完成图像理解、图像生成以及图像编辑任务。研究人员认为,这种统一架构能让模型利用强大的图像理解能力反哺生成效果,从而实现更精准的视觉输出。
在图像编辑领域,模型往往难以精准捕捉用户微妙或复杂的修改指令。苹果团队为解决这一难题,首创引入了名为“编辑指令对齐”的后训练阶段。
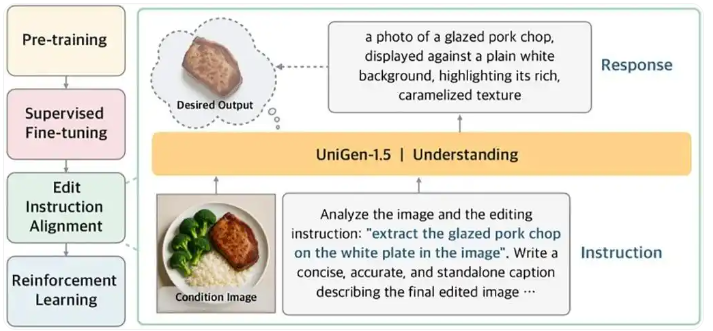
该技术并不直接让模型修改图片,而是要求模型先根据原图和指令,预测出目标图像的详细文本描述。这种“先想后画”的中间步骤,迫使模型在生成最终图像前,必须深度内化用户的编辑意图,从而大幅提升了修改的准确度。
这一中间步骤有助于模型在生成最终图像之前更好地理解预期的编辑内容。
除了指令对齐,UniGen 1.5的另一大贡献在于强化学习层面的创新。研究团队成功设计了一套统一的奖励系统,能够同时应用于图像生成和图像编辑的训练过程。
此前,由于编辑任务涉及从微调到重构的巨大跨度,统一奖励机制极难实现,而这一突破让模型在处理不同类型的视觉任务时,能够遵循一致的质量标准,显著增强了系统的“抗干扰”性。

在多项行业标准基准测试中,UniGen 1.5展现了强劲的竞争力。数据显示,该模型在GenEval和DPG-Bench测试中分别获得0.89和86.83的高分,显著优于BAGEL和BLIP3o等近期热门方法。
在图像编辑专项测试ImgEdit中,其4.31的综合得分不仅超越了OminiGen2等开源模型,更与GPT-Image-1等专有闭源模型表现持平。
尽管整体表现优异,UniGen 1.5目前仍存在一定局限性。研究人员在论文中坦承,由于离散去标记器(discrete detokenizer)在控制细粒度结构方面存在不足,模型在生成图片内的文字时容易出错。
此外,在部分编辑场景下,模型偶尔会出现主体特征漂移的问题,例如猫的毛发纹理改变或鸟的羽毛颜色偏差,这些问题将是团队未来的优化重点。
0
好文章,需要你的鼓励