
如何用AI开发简单应用?低成本搭建本地多模态知识库实操分享!
2025-12-24 17:14
98
起因是我出去旅游,去现场才发现需要预约,但是我压根没提前做攻略,我也不知道大家都在那得到最新的同步信息的。
于是我想做一个文旅助手,把真实景区文字描述、地理位置,开放时间,游玩的季节建议和门票等信息丢进去。
这样我出行的时候就可以不用单独拉群了,提前一周搜了一大堆某书,然后出发当天所有人跟失忆一样,又开始问又重新搜无限循环。
我脑子里过了一遍技术方案
首先,图片识别得用一套向量数据库。
景点的文字介绍,这些是非结构化文本,得用全文检索。然后,地理位置信息得有专门的空间数据库来处理。最后,门票价格、开放时间这些,又是传统的关系型数据库的活。
要把这四五套系统捏合在一起的话,查询逻辑就得好几步,
拿图片去向量库里比对,拿到ID,再去文本库搜描述,最后再用业务数据库里的价格和时间做过滤。
遇事不决先看Github,说不定世界的某一处已经有大神跟我的想法一样,我就不需要重复造轮子了,然后发现了Langchain(老牌Agent构建框架)跟一个叫OceanBase seekdb的数据库合作了。
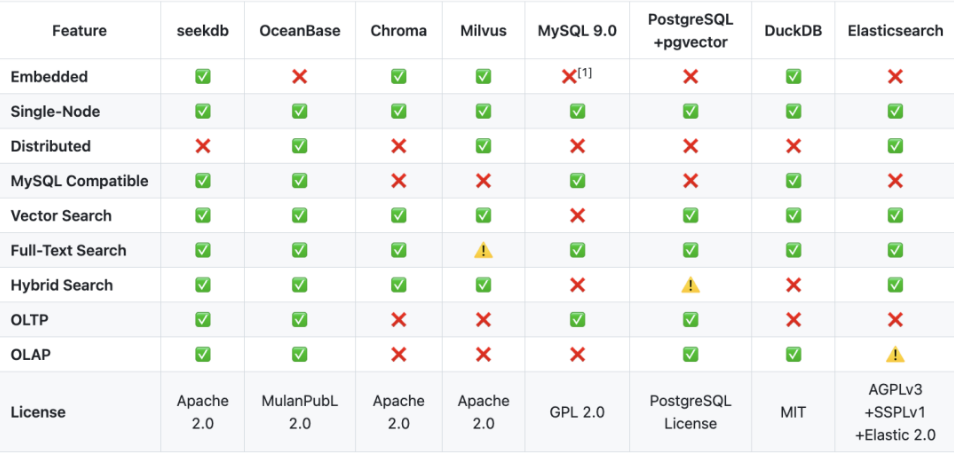
看了眼使用指南,seekdb竟然支持在一张表里,同时存储和索引向量、文本、JSON、GIS这些乱七八糟的数据。而大多数其他数据库要么只擅长关系型事务,要么只擅长向量,要么只擅长全文,混合能力通常需要多系统拼装。
LangChain解决的是把一个AI应用搭出来,有对话流程、工具调用、记忆、评估等,但它需要数据库来解决检索到底要落在哪个后端,怎么做混合过滤,怎么控制延迟和成本。
我这个文旅助手是RAG最难的检索,图片要相似(向量),描述要命中(全文),位置要限定(GIS),价格时间要过滤(结构化)。如果后端是多套系统拼起来,LangChain只能把这些步骤串成一条链,跑是能跑,但很长很慢,很容易报错。
seekdb负责把检索+过滤+排序三板斧在底层一次性做完,中间少很多胶水代码,也少很多不确定性。它把所有数据类型都拉到了同一个维度上。我可以像跟人说话一样,用一条SQL指令告诉它,
河南安阳的距离市中心50公里以内的,80分以上,适合春季旅行的人文景点
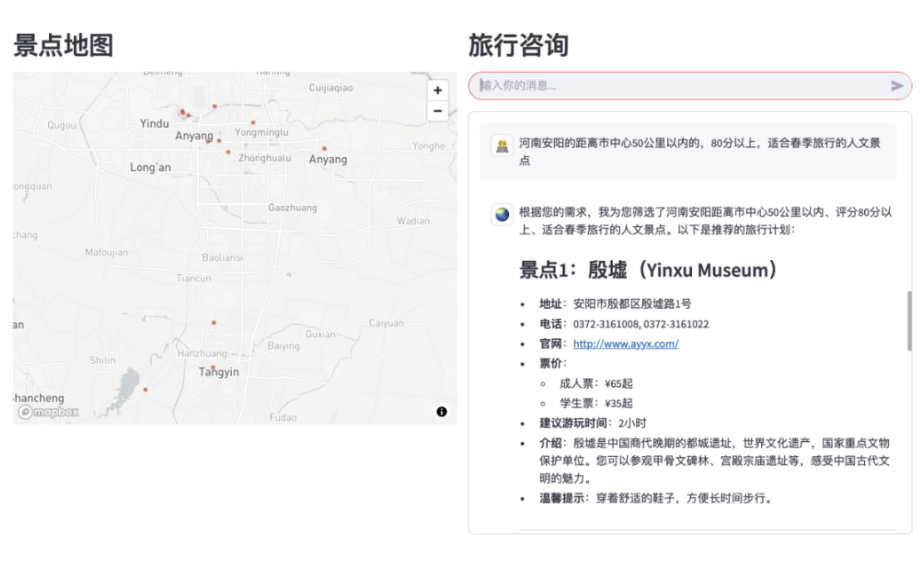
数据库自己会在底层把图片相似度、文本相关性、GIS空间关系和价格这些硬性指标一次性算好,然后直接把最精准的结果吐给我。
这里我想稍微解释一下混合搜索到底是在混什么,我这条需求里其实有四类信号,这张照片“像不像”另一个景点(图像),描述里有没有幽静古朴这类硬条件(全文检索+倒排),只要我周围5公里(GIS距离+范围查询),票价<50、开放时间符合(关系型过滤)。
难的是把这些信号合并成一次可控的检索执行,我还是用旅游类比一下,我要在一堆目的地里选一个最适合跨年的。
常规做法是先捞一小撮候选,向量召回是按你想要的感觉找相似目的地,比如氛围感,雪景,夜景,烟花,全文召回是按你搜的词再捞一批,比如直飞,温泉,跨年烟花,免签,地理范围再选一次,比如飞行不超过6小时。
这时候你会先拿到一个候选清单TopK,还没结束,要给每个候选算分,再加权合成总分排出优先级(重排Rerank)。再加硬条件过滤:预算、请假天数、出发时间、是否直飞,最后才是按总分排序选出我心仪的。
seekdb就是在同一条流水线里把语义找相似+关键词匹配+距离计算+预算时间过滤一次性算完,少了跨系统搬运和多次回表速度也就上来了。
最低1核CPU、2GB内存就能跑起来。在现在人均模型起手就要24GB的节点,我都有点不适应了。seekdb还能当MCP Server用,直接接入Cursor,Trae啥的。
还跟Dify打通了,可以直接做Dify的知识库。
那我就把这两天折腾的过程复盘一下。
第一步,部署,非常简单,电脑有Docker环境,直接一行命令搞定了。
docker run-d--name seekdb-p 2881:2881 oceanbase/seekdb:latest
如果习惯用Python,那更简单,pip install pyseekdb就行了。
接下来就是构建我想要的文旅小助手,我需要一个大模型的API key,把文本转成向量和后续问答。还需要一个地图服务的API key,用来处理地理位置,这里我用的是千问和高德。
数据集我用的是Kaggle上一个公开的352个中国城市景点数据。
准备就绪后,就是三件套,克隆项目代码,安装依赖,把申请的API密钥和本地数据库的连接信息填进去。
当浏览器里弹出那个简洁的对话框时,我感觉这几天的折腾都值了。
它能够理解我问题里那种模糊的的描述,然后通过向量搜索找到语义上相似的景点,再结合地理位置和一些我预设的偏好进行过滤。
这在一年多以前,是很难想象的。
有了多模态知识库和混合搜索,工程师拍下故障机器的照片,用语音描述刺耳的异响,系统就能瞬间从海量的维修手册,历史工单和实时传感器数据里,找出最可能的解决方案。
你也可以上传在街上看到的衣服照片,然后说,我想要类似风格,但材质是纯棉的,价格在三百块以内的。系统不再是简单推荐一堆长得像的图片,而是真正理解了你所有维度的需求。
到现在我还是有种想当然的荒谬的感觉,但忘掉脑子凭直觉去想,多模态的数据不就是应该放在一个数据库里面吗?
很合理吧!
目前模型的前端都可以vibe出那么多效果了,再把数据库打通
AI时代,每个人都可以做个自己的应用
0
好文章,需要你的鼓励