
通义千问发布Qwen3-TTS新模型:同时强化“音色生成”和“音色克隆”
2025-12-25 11:10
160
通义千问团队宣布Qwen3-TTS语音合成家族迎来两位新成员:声音设计模型Qwen3-TTS-VD-Flash和声音克隆模型Qwen3-TTS-VC-Flash,两款模型均已通过Qwen API对外开放。
在Qwen3-TTS-VD-Flash中,用户不需要再从有限的音色列表里做选择,只要用自然语言描述,就能定义一个全新的声音形象。比如声音的厚度、语速、情绪、角色气质,甚至“更像纪录片旁白,还是新闻主播”,都可以直接说明。
在InstructTTS-Eval测试中,Qwen3-TTS-VD-Flash的整体表现明显优于GPT-4o-mini-tts和Mimo-audio-7b-instruct,在角色扮演相关测试中,也超过了Gemini-2.5-pro-preview-tts。
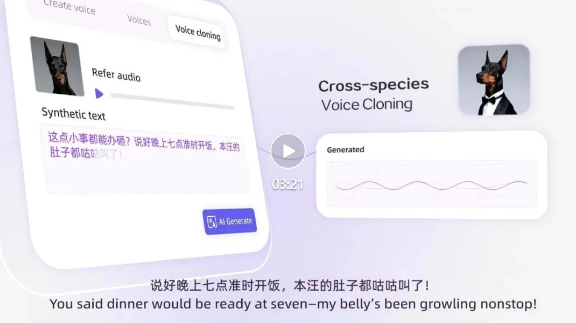
Qwen3-TTS-VC-Flash,只需要3秒语音样本,就可以完成声音克隆,并支持在中文、英文、日语、韩语、法语、德语、西班牙语、意大利语、葡萄牙语、俄语等10种主流语言中进行语音生成。
在MiniMax TTS多语言测试集上,Qwen3-TTS的平均词错误率(WER)表现优于MiniMax、ElevenLabs以及GPT-4o-Audio-Preview,尤其在跨语言场景中,内容稳定性优势明显。
无论是声音设计还是声音克隆,Qwen3-TTS的一个共同特点是表达自然度更高。模型会根据语义自动调整语气、停顿和节奏,而是更接近真实说话的感觉。

同时,两款模型在复杂文本处理上也更稳:面对非标准格式、长句或结构复杂的内容,依然能准确抓住重点并顺畅输出。
Qwen3-TTS这次更新更像一次“能力补齐”:既解决了“能不能快速复刻”,也解决了“能不能自由创造”。接下来,语音应用的想象空间,显然会更大一些。
目前,两款模型已通过通义模型服务接口对外开放。
Qwen3-TTS-Voice-Design API文档:
Qwen3-TTS-Voice-Clone API文档:
0
好文章,需要你的鼓励