
谷歌Gemini 3 Flash,为什么比Pro还聪明?
2025-12-25 11:18
126
Gemini 3 Flash发布已经有段时间了,速度快3倍,同时智力还反超Pro。但目前依然没人能够说明白:为啥Flash能比Pro还要「聪明」。
为何一个在参数规模上显著缩减的模型,能够在更大规模的模型擅长的领域实现超越?
长期以来,业界奉行着“参数即正义”的信条,认为更大的模型、更多的参数量必然带来更强的智能表现。
然而Gemini 3 Flash的出现打破了这一线性逻辑,它不仅在成本和速度上保持了「Flash」系列的轻量级特征,更在多项关键基准测试中,尤其是涉及复杂推理和超长上下文的任务上,击败了前一代甚至当代的「Pro」级模型。
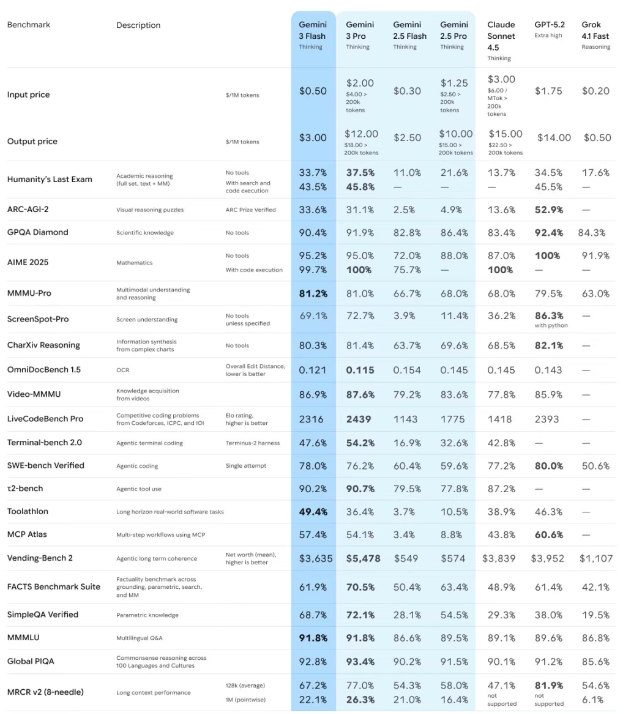
在长下文测试中,Gemini 3 Flash更是遥遥领先!
在OpenAI的MRCR基准测试中,Gemini 3 Flash在100万上下文长度下达到了90%的准确率!
这一表现在所有模型中均属最先进水平,大多数顶尖模型甚至无法突破256k的上下文长度。
那么谷歌到底用了什么魔法?Gemini 3 Flash凭什么在百万长文本与低成本间实现「降维打击」?
知名AI研究员 bycloudai在深入评测后指出,谷歌可能在模型架构研究上已处于「遥遥领先」的隐形地位。
这一表现打破了行业常规认知:它既没有像标准注意力机制那样产生高昂算力成本,也没有像常见的线性注意力或SSM混合模型那样导致知识推理能力下降。
Gemini 3 Flash似乎掌握了某种未知的「高效注意力机制」,令外界对其背后的技术原理直呼「看不懂」但大受震撼。
再挖掘Gemini 3 Flash的奥秘前,有必要先介绍一下这个评测标准。
在2023年至2024年间,评估大语言模型长上下文能力的主流方法是「大海捞针」(Needle In A Haystack,NIAH)。
该测试将一个特定的事实(针)插入到长篇文档(大海)的随机位置,要求模型将其检索出来。
然而,随着模型上下文窗口扩展至128k甚至1M token,NIAH测试迅速饱和。
Gemini 1.5 Pro、GPT-4 Turbo等早期模型在该测试中均能达到近乎100%的准确率。
NIAH本质上测试的是检索能力,而非推理能力。
它要求模型找到信息,但不要求模型理解信息之间的复杂依赖关系。
这导致了一种错觉:似乎所有模型都完美掌握了长上下文。
但在实际的企业级应用(如法律文档分析、代码库理解)中,用户不仅需要模型找到「条款A」,还需要模型理解「条款A」与「条款B」在特定条件下的冲突,这种高阶能力是NIAH无法覆盖的。
正是在这种背景下,Context Arena应运而生。
这是一个由独立研究者(如Dillon Uzar等人)维护的、专注于长上下文理解能力评估的基准平台。
Context Arena不仅仅是一个排行榜,它是一个针对大模型「注意力缺陷」的诊断工具看,衡量模型「智商」和长程记忆稳定性的试炼场。
Context Arena最具杀伤力的武器是MRCR(Multi-Round Co-Reference Resolution)基准测试。
OpenAI受到Gemini的启发,也搞了一个OpenAI-MRCR,就是一开始上面所说的评测基准。
这是一个设计精巧的压力测试,旨在击穿那些使用近似注意力机制(如线性注意力或稀疏注意力)的模型的防线。
测试机制是这样的,MRCR会生成一段极长的、多轮次的合成对话或文本。
在这些文本中,系统会植入多个高度相似的「针」(Needles)。
例如,文本中可能包含8首关于「貘」(tapir)的诗,每首诗的风格略有不同但主题一致。
挑战点在于系统会向模型提出极其刁钻的指令,如:「请复述关于貘的第二首诗」或「找出第四次提到貘时的具体描述」。
在Context Arena的MRCR榜单上,Gemini 3 Flash展现出了惊人的统治力。
这直接证明了Gemini 3 Flash并未为了速度而牺牲核心的「注意力精度」。
0
好文章,需要你的鼓励