
DeepSeekV4春节来袭!编码能力碾压GPT与Claude
2026-01-10 14:03
146
Information爆料称,DeepSeek将计划在2月中旬,也正是春节前后,正式发布下一代V4模型。
而这一次,所有目光都聚焦在同一维度上——编程能力。
目标:编程之王。
据称,DeepSeek V4编程实力可以赶超Claude、GPT系列等顶尖闭源模型。要知道,如今Claude是全网公认的编程王者,真要击败了它,那可真不是小事儿。毫无疑问,V4是继去年12月V3的重大迭代版,但内部测试者普遍反馈:这不是一次常规的升级,而是一次质的跨越。
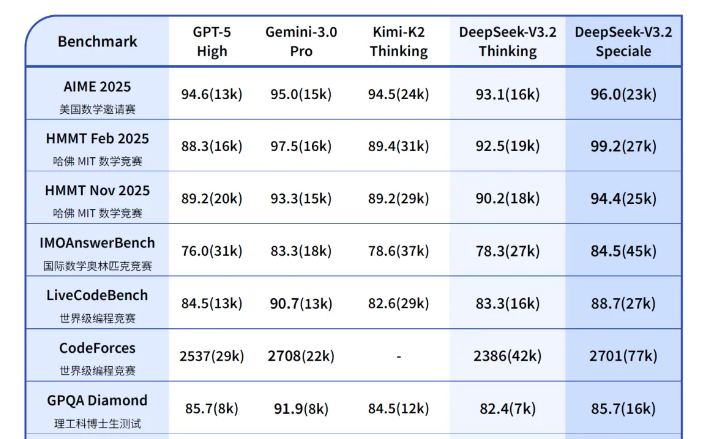
上个月,DeepSeek V3.2出世,在部分基准测试上碾压GPT-5、Gemini 3.0 Pro。这是DeepSeek在一直未推出真正意义上的重大换代模型的情况下,实现的反超。
也正因如此,V4被赋予了比以往任何一次迭代都更高的期待。
从目前流出的信息来看,DeepSeek V4在以下四个关键方向上,实现了核心突破,或将改变游戏规则。编程能力:剑指Claude王座
2025开年,Claude一夜之间成为公认的编程之王。无论是代码生成、调试还是重构,几乎没有对手。但现在,这个格局可能要变了。知情人士透露,DeepSeek内部的初步基准测试显示,V4在编程任务上的表现已经超越了目前的主流模型,包括Claude系列、GPT系列。如果消息属实,DeepSeek将从追赶者一步跃升为领跑者——至少在编程这个AI应用最核心的赛道上。超长上下文代码处理:工程师的终极利器
V4的另一个技术突破在于,处理和解析极长代码提示词的能力。对于日常写几十行代码的用户来说,这可能感知不强。但对于真正在大型项目中工作的软件工程师来说,这是一个革命性的能力。想象一下:你有一个几万行代码的项目,你需要AI理解整个代码库的上下文,然后在正确的位置插入新功能、修复bug或者进行重构。以前的模型往往会忘记之前的代码,或者在长上下文中迷失方向。V4在这个维度上取得了技术突破,能够一次性理解更庞大的代码库上下文。这对于企业级开发来说,是真正的生产力革命。算法提升,不易出现衰减
据透露,V4在训练过程的各个阶段,对数据模式的理解能力也得到了提升,并且不容易出现衰减。AI训练需要模型从海量数据集中反复学习,但学到的模式/特征可能会在多轮训练中逐渐衰减。通常来说,拥有大量AI芯片储备的开发者可以通过增加训练轮次来缓解这一问题。推理能力提升:更严密、更可靠
知情人士还透露了一个关键细节:用户会发现V4的输出在逻辑上更加严密和清晰。
这不是一个小改进。
这意味着模型在整个训练流程中对数据模式的理解能力有了质的提升,而且更重要的是——性能没有出现退化。在AI模型的世界里,没有退化是一个非常高的评价。很多模型在提升某些能力时,会不可避免地牺牲其他维度的表现。V4似乎找到了一个更优的平衡点。
最近一周,CEO梁文锋参与合著的一篇论文,也透露出一些线索:他们提出了一种全新的训练架构,在无需按比例增加芯片数量的情况下,可以Scaling更大规模的模型。
0
好文章,需要你的鼓励