
GPT-5.2考赢人类!大模型能力进入过剩年代
2026-01-11 16:16
135
GPT-5.2刚刚刷新了一项新纪录!
OpenAI联合创始人Greg Brockman发帖称使用GPT-5.2在ARC-AGI-2基准测试上,表现超过了人类基线水平。

在基准测试时技能爆表,但一到实际应用就「掉链子」,OpenAI前首席科学家Ilya Sutskever提到的这种大模型「性能悖论」我们并不陌生。
这也是AGI评估领域一个长期存在的难题——如何区分大模型「真正的推理能力」与「刷题型能力」。
而ARC-AGI-2的出现正好打破了这一难题。
ARC-AGI-2的全称为「Abstraction and Reasoning Corpus for Artificial General Intelligence-Version 2」,是ARC系列基准的最新升级版本。
该基准由François Chollet(Keras之父、前Google Brain研究员)及其团队在2025年推出,其设计初衷十分明确:
测试AI是否具备AGI所必需的抽象、归纳与迁移推理能力,而非记忆或统计模式匹配。
ARC系列与传统NLP或多模态benchmark最大的不同在于:它没有大规模训练集,每道题目都是从未见过的新任务,因此不存在通过「刷数据」获得高分的可能。
它要求AI像人类一样具备真正的推理和举一反三的能力。
Chollet曾多次公开表示,如果一个系统只能在见过的数据分布上表现良好,那它并不具备AGI所需的能力。
因此,ARC基准测试刚好直击大模型的「软肋」。
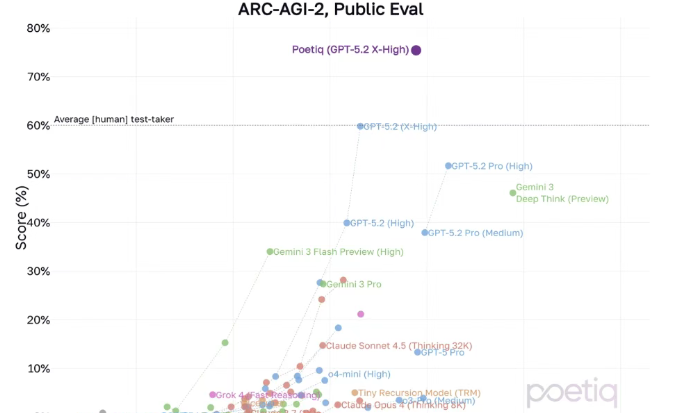
新纪录的刷新者,并非单一模型,而是一个名为Poetiq(GPT-5.2X-High)的系统。
Poetiq是一家专注于元系统(Meta-System)架构的AI公司。
其核心理念并不是训练一个更大的模型,而是通过软件层面的系统设计,自动构建「会调用模型的系统」。
Poetiq(GPT-5.2X-High)在ARC-AGI-2数据集上实现了75%准确率,每问题成本不到8美元,超越前SOTA 15个百分点。
在Poetiq(GPT-5.2X-High)系统出现之前,GPT-5.2(X-High)已经非常接近人类平均水平。
ARC-AGI-2榜单中,人类平均准确率约为60%,GPT-5.2X-High的成绩与之几乎持平,代表了当时AI在该基准上的最强推理能力。
但Poetiq的加入,使GPT-5.2(X-High)的得分从60%直接拉升到了75%,从勉强及格(人类平均水平)迈入了优等生的行列(显著超越人类平均水平)。
在同一榜单上,还能看到Gemini 3 Deep Think(Preview)的身影。
该模型主打「深度思考(Deep Think)」技术,在ARC-AGI-2上的成绩约为46%,明显落后于GPT-5.2系列,并且成本相对后者也略高。

Poetiq表示,整个过程没有对GPT-5.2进行任何训练或者特定优化。
这正是Poetiq元系统的初衷,旨在自动构建完整的系统,通过调用任何现有的前沿模型来解决特定任务。
图片
从15%的提升数据来看,Poetiq对于基础模型性能的提升幅度还是非常明显的。
它的存在证明了不需要堆算力,通过优秀的软件架构也能大幅提升AI性能。
从这个角度上,它也验证了接下来OpenAI的一个判断——当前大模型,正逐渐进入「能力过剩」阶段。
0
好文章,需要你的鼓励