
梁文锋署名开源"记忆"模块,DeepSeek V4更细节
2026-01-13 17:33
115
就在十几个小时前,DeepSeek发布了一篇新论文,主题为《Conditional Memory via Scalable Lookup:A New Axis of Sparsity for Large Language Models》,与北京大学合作完成,作者中同样有梁文锋署名。

简单总结一波这项新研究要解决的问题:目前大语言模型主要通过混合专家(MoE)来实现稀疏化,这被称为「条件计算」。但是,现有的Transformer缺少原生的知识查找机制,只能被迫通过计算过程低效地模拟检索行为。
针对这一现状,DeepSeek提出了条件记忆(conditional memory),从而与MoE的条件计算互补,并通过引入一个新模块Engram来实现。
目前,模块「Engram」相关的实现已经上传到了GitHub。
这让网友们感慨:「DeepSeek is back!」
此外,结合元旦期间公布的研究《mHC:Manifold-ConstrainedHyper-Connections》,我们可以明确的是DeepSeek v4的模样愈发清晰,就等上新了!
除了条件计算(MoE),LLM还需要一个独立的条件记忆Engram
MoE模型通过条件计算实现了模型容量的扩展,但现有的Transformer架构缺乏原生的知识查找原语,只能通过计算过程低效地模拟检索行为。
为了解决这一问题,DeepSeek提出了条件记忆(conditional memory)这一与条件计算互补的稀疏化维度,并通过Engram模块加以实现。Engram在经典𝑁-gram嵌入的基础上进行了现代化改造,使其能够以O(1)时间复杂度完成知识查找。
通过形式化提出稀疏性分配问题,DeepSeek还发现了一条呈U型的扩展规律,用以刻画神经计算(MoE)与静态记忆(Engram)之间的最优权衡关系。
在这一规律的指导下,DeepSeek将Engram扩展至270亿参数规模,并在严格等参数量、等FLOPs的条件下,其整体性能显著优于纯MoE基线模型。
尤为值得注意的是,尽管记忆模块本身主要被用于提升知识检索能力(如MMLU提升+3.4、CMMLU提升+4.0),但DeepSeek观察到其在通用推理能力(如BBH提升+5.0、ARC-Challenge提升+3.7)以及代码与数学推理任务(HumanEval提升+3.0、MATH提升+2.4)上带来了更为显著的增益。
进一步的分析表明,Engram能够将静态知识的重建负担从模型的浅层中剥离出来,从而有效加深网络用于复杂推理的有效深度。此外,通过将局部依赖关系交由查表机制处理,Engram释放了注意力机制的容量,使其能够更专注于全局上下文建模,从而显著提升了长上下文检索能力(例如Multi-Query NIAH的准确率从84.2提升至97.0)。
最后,Engram在系统层面同样展现出基础设施感知的高效性:其确定性的寻址方式支持在运行时从主机内存进行预取,几乎不会带来额外的性能开销。
DeepSeek认为,条件记忆将成为下一代稀疏大模型中不可或缺的核心建模原语。
Engram架构如下,其设计目标是在结构上将静态模式存储与动态计算过程从Transformer主干网络中分离出来,从而对其进行增强。该模块对序列中每一个位置依次执行两个功能阶段:检索与融合。
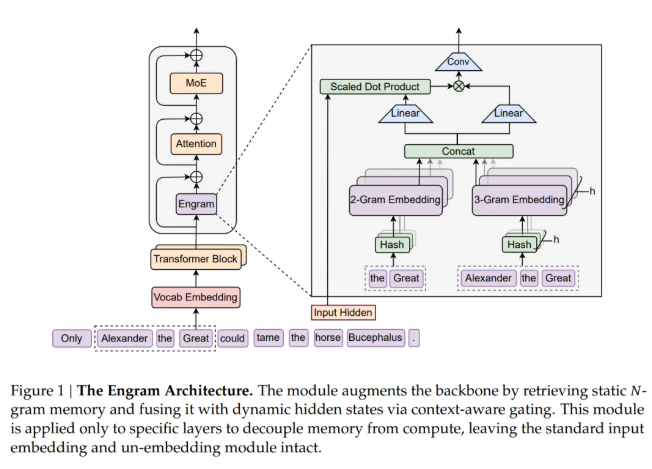
在运行过程中,DeepSeek首先对当前位置的后缀N-gram进行提取与压缩,并通过哈希机制以确定性的方式检索对应的静态嵌入向量。随后,这些被检索到的嵌入会在当前隐藏状态的调制下进行动态调整,并进一步通过一个轻量级卷积操作加以精炼。最后,Engram与多分支架构进行集成。
0
好文章,需要你的鼓励