
智谱AI开源图像生成模型GLM-Image:AI绘图圈变天?
2026-01-14 10:30
136
1月14日,智谱AI发布开源图像生成模型GLM-Image。该模型采用"自回归+扩散解码器"混合架构,自回归部分基于GLM-4-9B负责全局语义理解,扩散解码器约7B参数专注高保真细节渲染。
GLM-Image在文字渲染和知识密集型生成上达到开源SOTA水平,擅长生成海报、PPT、科普图等场景,支持任意分辨率输出。API价格仅0.1元/张,代码权重已在Hugging Face和GitHub开源。

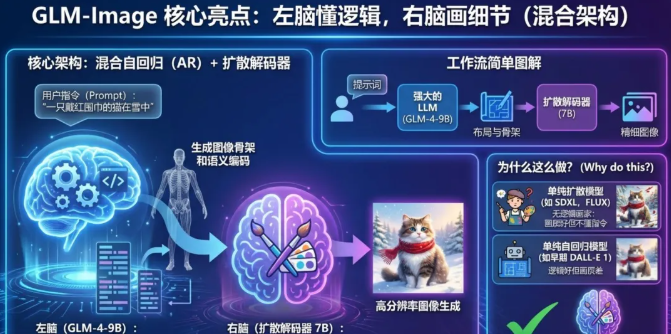
核心亮点一:左脑懂逻辑,右脑画细节(混合架构)
现在的生图模型(比如SDXL,FLUX)大多是纯粹的“扩散模型”。而GLM-Image搞了个“缝合怪”创新——混合自回归(AR)+扩散(Diffusion)解码器。
通俗点说,它的工作流程是这样的:
“大脑”(GLM-4-9B):
先用一个强大的大语言模型(LLM)去理解你的提示词。它不直接画图,而是先规划布局,生成图像的“骨架”和语义编码。
“画师”(Diffusion Decoder 7B):
接着,一个专门的扩散解码器接过“骨架”,负责填色、光影、渲染纹理,把它变成一张高清大图。
为什么要这么做?
单纯的扩散模型有时候像个“没有逻辑的画家”,画质好但听不懂复杂指令;单纯的自回归模型(像早期的DALL-E 1)逻辑好但画质糙。GLM-Image把两者结合了:既有LLM的超强理解力,又有Diffusion的细腻画质。
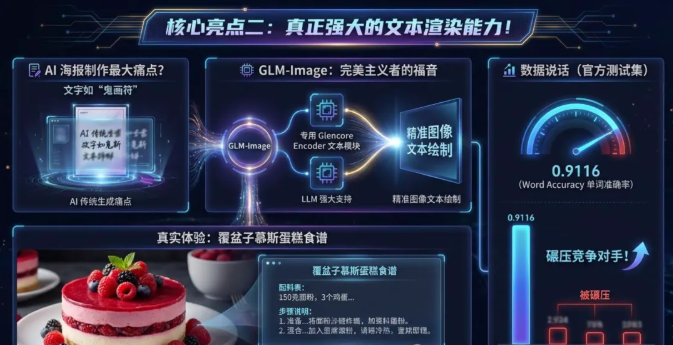
核心亮点二:文字渲染能力,真的强!
大家用AI画海报最大的痛点是什么?字写得像鬼画符。
GLM-Image在这方面简直是“强迫症福音”。因为它有一个专门的Glencore Encoder文本模块,加上LLM的加持,它在图片里写字非常精准。
数据说话(官方测试集):
在文本渲染准确率上,GLM-Image达到了0.9116(Word Accuracy)。
对比同行:
这一项分数直接碾压了FLUX、SD3甚至闭源的DALL-E 3。
实际体验:
你让它画一个“树莓慕斯蛋糕的食谱”,上面要有标题、配料表(面粉150g、鸡蛋3个...)、步骤图。它不仅能画出诱人的蛋糕,还能把上面的每一行小字都排版得整整齐齐,几乎没有错别字!
核心亮点三:是个“学霸”,也是个“修图师”
1.知识密集型生成
得益于它用了GLM-4这种大模型作为底座,它非常擅长处理信息密度极高的提示词。
以前你让AI画“一张海报,左上角是标题,右下角是四个步骤图,底部是营养成分表”,AI大概率会崩溃,元素乱飞。GLM-Image却能像专业排版师一样,严格遵循你的空间指令。
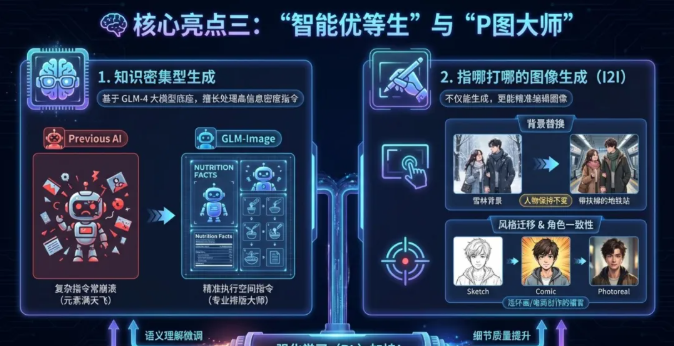
2.指哪打哪的图生图(I2I)
它不仅能生图,还能修图。
换背景:
“把雪地森林背景换成带有自动扶梯的地铁站”,人物保持不变。
风格迁移&角色一致性:
这一点对于做连环画或电商图的朋友来说非常重要。
而且,它是用强化学习(RL)训练过的!采用了GRPO算法(没错,类似DeepSeek R1的那种思路),专门针对语义理解和细节质量进行了微调。
0
好文章,需要你的鼓励