
智谱发布GLM-4.7-Flash开源模型,30B参数仅激活3B
2026-01-21 09:47
153
2026年1月20日,智谱AI发布了GLM-4.7-Flash,一个让整个社区沸腾的模型。总参数30B,激活参数仅3B,却达到了接近70B模型的性能。更让人激动的是:在智谱开放平台完全免费调用。
这意味着什么?你可以在一台24GB显存的GPU甚至Mac电脑上,运行一个性能媲美70B模型的AI助手。不用再为大模型的昂贵成本发愁,不用再担心数据隐私泄露。
技术架构:30B如何做到70B性能?
GLM-4.7-Flash的核心秘密,就是混合专家架构(MoE)。
什么是MoE?
想象一个医院:医院里有30个医生,但每个患者看病时,只需要看3个最相关的科室。
MoE也是如此:
总参数30B:就像医院的30个医生,涵盖了所有领域的知识
激活参数3B:每次推理只调用3个最相关的专家,就像患者只看3个科室
这带来两个直接好处:
1.速度快
每次只计算3B参数,速度可达60-80+令牌/秒,比传统30B模型快10倍。
2.硬件要求低
24GB GPU或Mac M系列芯片就能跑,个人开发者也能负担得起。
多潜在注意力(MLA):记住关键信息
除了MoE,GLM-4.7-Flash还使用了多潜在注意力机制(MLA)。
传统注意力:像一个人试图记住所有对话内容,大脑很快超载。
MLA:像做会议纪要,只提取关键信息,大幅降低记忆负担。
简单来说,MLA通过压缩注意力键值(KV Cache),在不损失性能的情况下,大幅降低显存占用。
这就让GLM-4.7-Flash在处理长文本时,依然保持高效。
🚀立即可用:本地部署命令
#使用ollama运行GLM-4.7-Flash
ollama pull glm4.7-flash
ollama run glm4.7-flash
#或者使用llama.cpp
llama-cli-m glm4.7-flash.gguf-p"你好"-n 100
🏆性能表现:数据不说谎
性能怎么样?我们看实际数据。
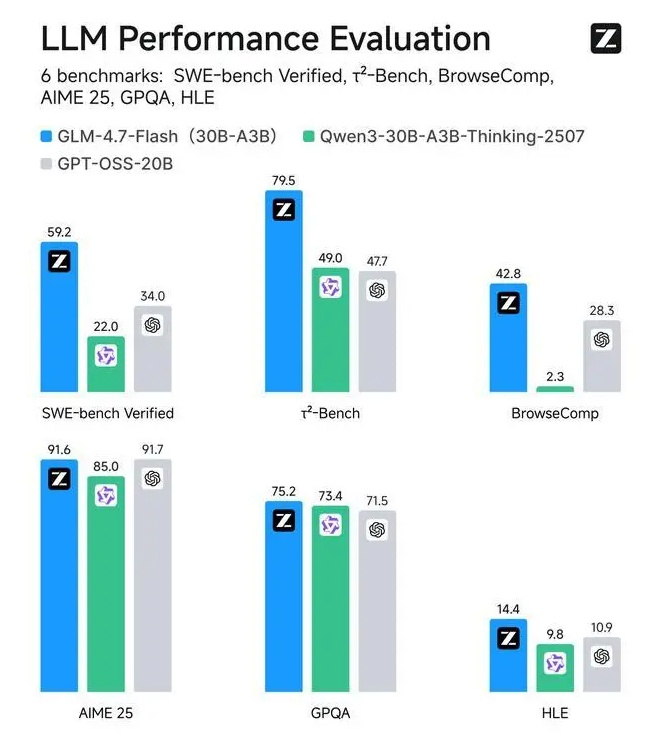
在主流基准测试中,GLM-4.7-Flash的综合表现已经超过gpt-oss-20b和Qwen3-30B-A3B-Thinking-2507。
更令人惊讶的是,在SWE-bench Verified、τ-Bench等专业基准测试中,它取得了开源SOTA分数。
这就是为什么社区评价它为"70B以下最佳模型"。
0
好文章,需要你的鼓励