
DeepSeek开源OCR专用模型DeepSeek-OCR 2,采用类人阅读方式理解复杂文档
2026-01-27 16:18
113
DeepSeek今日开源了面向OCR场景的专用模型DeepSeek-OCR 2,并同步发布技术报告。
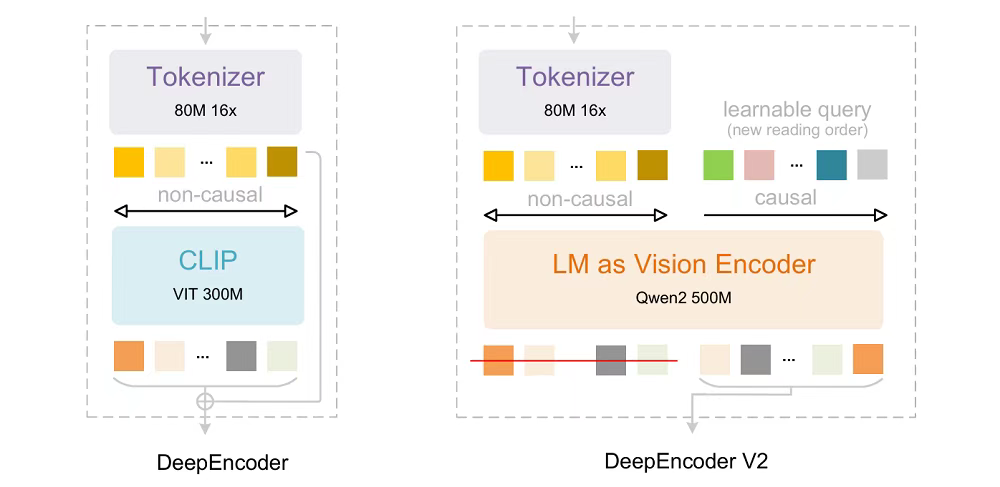
这款模型是去年DeepSeek-OCR的升级版本。核心改进在于全新的解码器设计——让模型阅读图片和文件的方式更接近人类习惯,而非机械式扫描。
传统OCR模型的阅读模式通常是从左上到右下逐行扫描。DeepSeek-OCR 2则能先理解文档结构,再按结构逐步读取内容。这种视觉理解方式使模型在处理复杂布局、公式和表格时表现更佳。
技术架构:从"强制排序"到"语义排序"
DeepSeek-OCR 2延续了前代的编码器-解码器架构,关键升级集中在编码器部分。新版DeepEncoder V2将原本基于CLIP的编码器替换为基于LLM的架构,并引入因果推理机制。
研究团队指出,当二维图像被映射为一维序列后,固定的线性顺序往往与真实语义组织方式不匹配,尤其在OCR、表格等复杂布局场景中问题更为突出。
DeepEncoder V2的解决方案是:先通过窗口注意力实现约16倍的token压缩,再引入"因果流查询"机制。这种设计让模型在观察全局视觉上下文后,自主生成符合语义的阅读顺序,而非依赖预设的空间展开规则。
性能表现:多项指标领先
在文档理解基准测试OmniDocBench v1.5上,DeepSeek-OCR 2取得91.09%的得分,较前代提升3.73%。该基准涵盖1355个文档页面,包括杂志、学术论文、研究报告等9个类别。
阅读顺序的编辑距离从0.085降至0.057,表明新编码器能更有效地排列视觉信息。在相似的视觉token预算下,DeepSeek-OCR 2的文档解析编辑距离(0.100)低于Gemini-3 Pro(0.115)。
不过研究团队也指出,模型在文本密度极高的报纸类文档上表现欠佳,后续可通过增加局部裁剪或补充训练样本来改善。
未来方向:统一全模态编码器
DeepSeek研究团队认为,DeepEncoder V2验证了LLM风格编码器在视觉任务上的可行性,并具有演变为统一全模态编码器的潜力——在同一参数空间内处理文本、语音和视觉内容。
团队表示,DeepSeek-OCR的光学压缩代表了向原生多模态的初步探索,未来将继续通过共享编码器框架集成更多模态。
相关链接:
0
好文章,需要你的鼓励