
Z-Image 全量基座模型开源:告别蒸馏缩水,重塑 AI 图像生成精度
2026-01-28 21:42
78
Tongyi-MAI发布Z-Image(造相)全量图像生成基座模型,这是一款基于单流Diffusion Transformer(S³-DiT)架构的未蒸馏模型,旨在为创作者、研究者提供“满血级”创意控制能力,解决蒸馏模型(如Z-Image-Turbo)在细节、微调潜力上的缩水问题,同时兼容消费级硬件部署,填补“高性能与低门槛”的行业缺口。

一、模型定位:创作与研究的“原力基座”
Z-Image与追求“快推理”的Z-Image-Turbo形成明确分工,核心定位是**“高精度、高可控、高扩展”的基础模型**:
区别于蒸馏模型的“速度优先”,Z-Image保留完整训练信号,不做任何性能妥协,专注满足专业级需求(如时尚摄影、艺术创作、模型微调);
支持LoRA训练、ControlNet结构控制、语义微调等进阶操作,是研究人员探索图像生成技术的理想载体;
6B参数规模(据arXiv论文),训练成本仅需314K H800 GPU小时(约63万美元),远低于同类开源模型(如Qwen-Image 20B、Flux.2 32B),兼顾性能与经济性。
二、核心技术优势:五大能力突破蒸馏局限
完整CFG支持,精准解析复杂提示词
支持Classifer-Free Guidance(分类器自由引导),能精准理解专业级Prompt(如“蝴蝶光+胶片质感+高定剪裁”),避免蒸馏模型“解析模糊”问题,适配时尚、艺术等需要精细控制的场景。
全风格覆盖,从写实到艺术无短板
可驾驭超现实浪漫主义摄影、黑白高定肖像、暗黑哥特风、赛博生物发光等多元风格,无论是8K分辨率的时尚大片细节(如衣料纹理、金属光泽),还是胶片质感(Ilford HP5 Plus、Kodachrome 64),均能高度还原。
高生成多样性,拒绝“同质化”
不同种子值(Seed)下,能产出差异化的构图、面部特征与光影效果,避免快速模型“换皮不换骨”的局限,适合需要多方案创意发散的场景。
强微调潜力,支持全链路扩展
保留完整训练信号,是LoRA训练(如特定风格、人物微调)、ControlNet结构控制(如姿态、轮廓约束)的优质基座,同时支持Z-Image-Edit衍生模型(据arXiv论文),具备指令级图像编辑能力。
精准负向提示,剔除画面瑕疵
对Negative Prompt响应灵敏,可精准去除“模糊、多余装饰、光影断层”等问题,无需反复生成试错,提升专业创作效率。
三、与Z-Image-Turbo对比:按需选择,各有所长
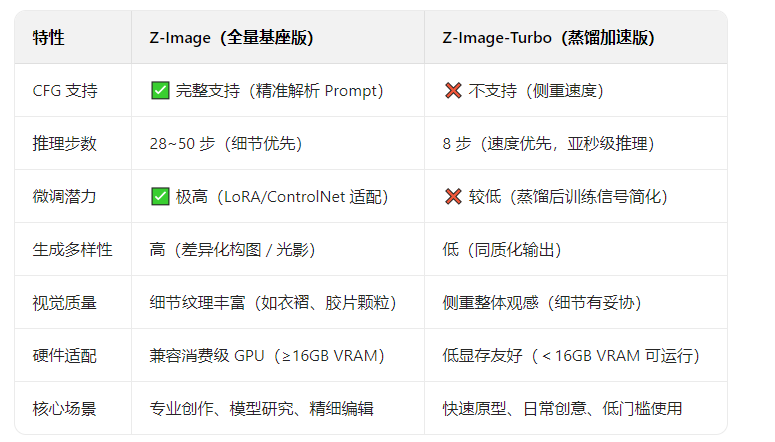
四、部署与实操指南:ComfyUI无缝适配
Z-Image已集成至diffusers库,支持ComfyUI官方工作流,本地部署仅需3步:
1.推荐参数设置
分辨率:512×512~2048×2048(支持任意长宽比);
引导系数(Guidance Scale):3.0~5.0(平衡创意与精准度);
推理步数:28~50步(推荐AuraFlow采样器,细节还原最佳);
量化版适配:GGUF Q4_K_M版在16GB VRAM设备上可流畅运行,推理速度约1.6~3秒/张。
2.工作流替换
在Z-Image-Turbo原有工作流中,替换“模型加载器”为GGUF Loader(量化版)或常规Diffusion模型加载器(BF16版),无需修改其他节点,即可直接生成。
五、补充信息:开源生态与扩展能力
许可证:Creative Commons Attribution 4.0(CC BY 4.0),允许自由共享、改编,商用需注明出处;
多语言支持:含中英文README,适配全球开发者与创作者;
提示词资源:提供50+场景化模板(3D建模、艺术风格转换等),支持与Gemini/GPT-4o等多模型协作;
在线体验:本地算力不足可使用RunningHub,新用户注册送1000点,每日登录送100点。
Z-Image的开源,打破了“高性能模型必靠大参数、快推理必牺牲细节”的行业误区——通过单流Diffusion Transformer架构优化与高效训练流程,它以6B参数实现“细节不缩水、微调不妥协、部署不复杂”,既为专业创作者提供“像素级控制”的创作工具,也为研究者降低了高性能模型的探索门槛,堪称2026年开源图像生成领域的“精度标杆”。
0
好文章,需要你的鼓励