
腾讯混元开源 HPC-Ops:解决推理卡性能瓶颈,LLM 推理吞吐提升 30%
2026-01-28 22:01
139
腾讯混元AI Infra团队正式开源生产级高性能LLM推理核心算子库HPC-Ops。该算子库基于CUDA与CuTe从零构建,针对国内主流推理卡(如H20)适配优化,解决了现有算子库“硬件不匹配、开发门槛高”的痛点,将核心算子性能逼近硬件峰值,在真实场景中实现混元模型推理QPM提升30%、DeepSeek模型QPM提升17%,单算子性能最高超越主流方案2.22倍,为大模型推理效率突破提供底层支撑。
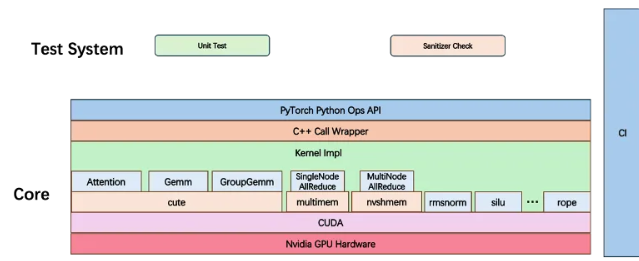
一、开源背景:瞄准大模型推理的两大核心痛点
现有主流算子库(如FlashInfer、DeepGEMM、TensorRT-LLM)存在明显局限,难以满足国内大规模推理需求:
硬件适配错位:多以NVIDIA H800等训练卡为优化目标,而国内主流推理服务依赖H20等推理型显卡。不同硬件的算力带宽差异导致现有算子库无法发挥推理卡峰值性能,造成资源浪费;
开发与使用成本高:核心Kernel封装深、代码复杂度高,普通AI研究者难以修改适配,导致量化算法、投机采样等加速技术因缺乏匹配算子而无法落地(如早期4bit/8bit量化因无低精度算子沦为“负优化”);
功能覆盖不足:业务侧对“极致吞吐、低延迟、Blockwise FP8量化”的需求日益迫切,现有库难以提供全面支持。
二、HPC-Ops核心定位与架构:轻量、高效、易扩展
HPC-Ops是面向LLM推理场景的生产级算子库,核心目标是“适配推理卡、降低门槛、突破性能”,架构包含六大核心模块:
核心计算模块:Attention(注意力计算)、GroupGEMM(分组矩阵乘法)、FusedMoE(融合混合专家系统),覆盖LLM推理的关键算力环节;
辅助功能模块:机内/机间通信(支持多GPU协同)、Norm(归一化)、Sampler(采样)及小算子融合(如SiLU、RoPE),形成全链路优化;
工程抽象层:基于CuTe扩展vec抽象层(统一高效数据搬运)与Layout代数抽象(隔离Tiling与计算逻辑),让开发者聚焦算法而非硬件细节,降低CUDA开发门槛。
三、三大技术亮点:从硬件到开发的全链路优化
1.任务特性与硬件能力深度对齐
访存瓶颈突破:针对推理卡带宽特性,通过“指令发射顺序调整+数据预取优化”,确保数据传输单元高利用率,访存带宽可达硬件峰值的80%以上;
指令级精准适配:针对Decode Attention、小Batch GroupGEMM等场景,优化AB矩阵交换逻辑,对齐硬件wgmma指令,去除冗余操作(如无效算力消耗),提升计算效率。
2.精细任务调度与数据重排
负载均衡与缓存优化:重新设计任务划分策略,确保每个SM(流多处理器)任务均衡,同时兼顾Cache连续性,减少数据访问延迟;
Persistent Kernel隐藏开销:采用持久化内核技术,掩盖Kernel启动(Prologue)与收尾(Epilogue)的耗时,提升整体吞吐量;
创新数据重排:FP8 Attention中引入Interleave重排技术,解决指令不匹配问题,减少线程间数据Shuffle,性能超越业界SOTA。
3.低门槛开发:聚焦算法本身
抽象层简化复杂度:通过vec抽象层统一数据搬运逻辑,Layout代数抽象隔离复杂的分块(Tiling)操作,避免开发者陷入GPU编程的细节(如数据重解释、格式转换);
实践范本价值:代码可作为CUTLASS与CuTe工业级开发的学习案例,数百行代码即可构建SOTA算子,降低高性能算子的开发门槛。
四、性能表现:端到端与单算子双突破
1.端到端推理提升
混元模型:基于HPC-Ops优化后,推理QPM(每秒查询数)提升30%,直接提升大规模服务的吞吐能力;
DeepSeek模型:QPM提升17%,验证了算子库对不同LLM的适配性。
2.单算子性能碾压主流方案
算子模块对比对象性能提升幅度关键场景优势
Attention FlashInfer/FlashAttention BF16精度最高2.22倍(Decode场景);FP8精度最高2.0倍(长序列)小Batch、长序列推理优势显著
GroupGEMM DeepGEMM(v2.2.0)低Batch(≤64)最高1.88倍;大Batch约1.1倍兼容Token不连续输入,减少临时显存
FusedMoE TensorRT-LLM(v1.1.0)TP(张量并行)场景最高1.49倍;EP场景最高1.09倍全流程封装(数据重排→计算→Reduce)
五、当前能力与未来规划
1.现有核心能力
框架与精度兼容:API无缝对接vLLM、SGLang等主流推理框架,原生支持BF16、FP8多精度量化,满足不同精度需求;
生产级验证:已在腾讯大规模LLM推理服务中落地,经过高并发场景验证,稳定性与性能兼具。
2.未来发展方向
长上下文优化:研发稀疏Attention算子,解决长序列(如64K+)大模型的内存与算力瓶颈;
更多量化策略:拓展4bit/8bit混合精度、Blockwise量化等方案,平衡推理速度与模型精度;
分布式推理优化:布局计算-通信协同内核,融合多GPU计算与通信逻辑,降低分布式场景的通信开销。
六、开源价值:推动推理技术生态共建
HPC-Ops已开源至GitHub,不仅为开发者提供“适配推理卡、高性能、低门槛”的算子工具,更以工业级代码作为学习范本,助力AI社区深入理解高效算子开发。腾讯混元团队欢迎行业贡献PR(如边缘场景优化、教程案例),共同推动大模型推理技术边界拓展。
0
好文章,需要你的鼓励