
智谱开源GLM-OCR:0.9B参数刷新文档解析榜单,成本仅为传统方案1/10
2026-02-03 13:34
122
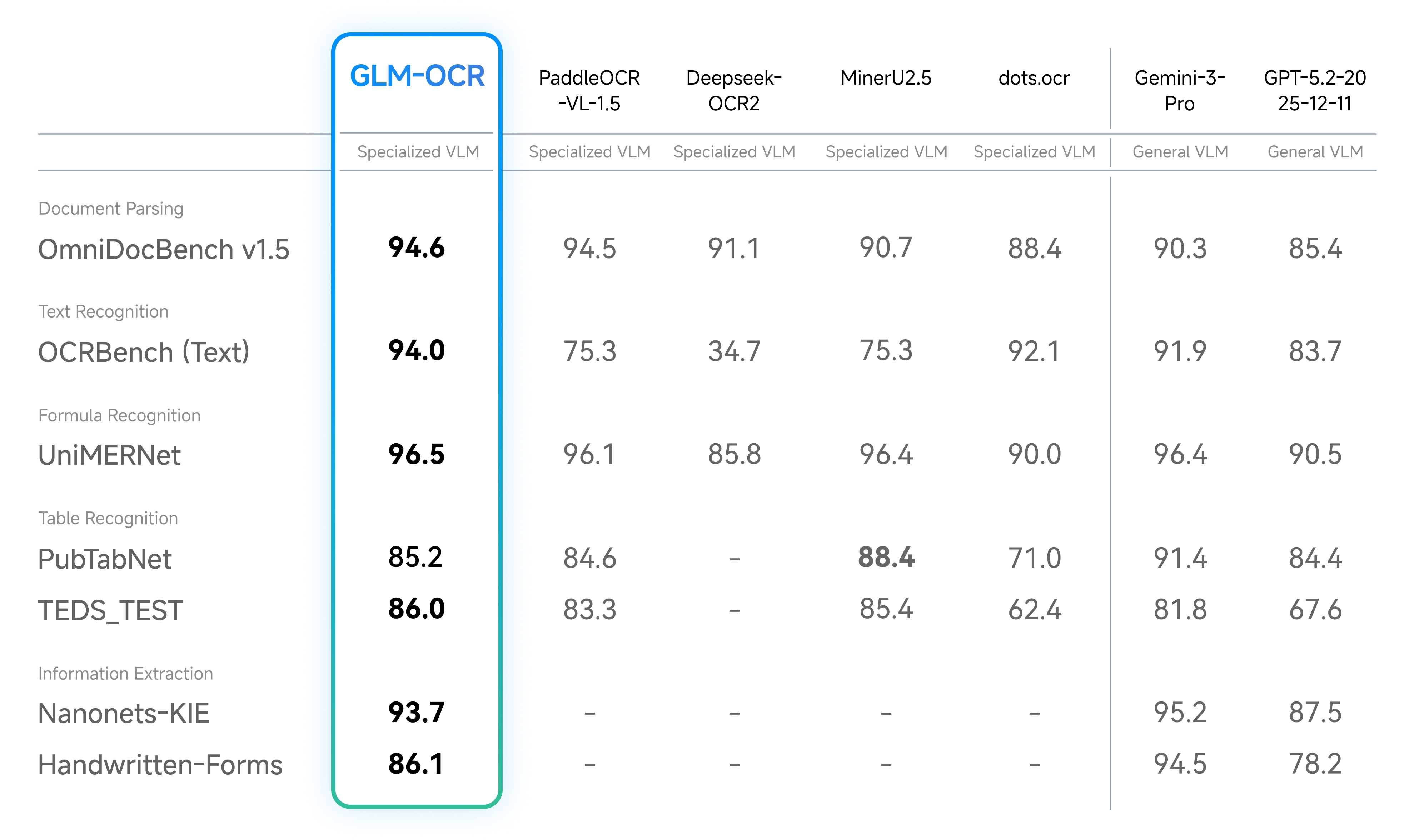
2月3日,智谱正式发布并开源GLM-OCR模型。这款仅0.9B参数的轻量级OCR模型,在权威文档解析榜单OmniDocBench V1.5中以94.6分登顶,性能接近Gemini-3-Pro,刷新了小模型在OCR领域的能力上限。
极致轻量,性能不减
GLM-OCR参数量仅0.9B,却在公式识别、表格识别、信息抽取等多项主流基准中取得SOTA表现。模型支持vLLM、SGLang和Ollama部署,适合高并发与边缘部署场景。
六大场景全面领先
智谱针对真实业务痛点进行了深度优化,GLM-OCR在代码文档、复杂表格、手写体、多语言、印章识别、票据提取六大核心场景均取得显著优势,能够精准解析扫描件、PDF及各类票据,有效解决手写、印章、竖排及多语言混排等难题。
速度快,成本低
处理效率方面,GLM-OCR处理PDF文档的吞吐量达1.86页/秒,图片达0.67张/秒,速度显著优于同类模型。
价格方面,API输入输出同价,仅需0.2元/百万Tokens。1元即可处理约2000张A4大小扫描图片或200份10页PDF,成本约为传统OCR方案的1/10。
技术架构
GLM-OCR采用"编码器-解码器"架构,集成了自研的CogViT视觉编码器(400M参数),并在数十亿级图文对数据上进行大规模预训练。模型首次将多Tokens预测损失(MTP)引入OCR训练过程,通过全任务强化学习显著提升了复杂文档场景下的识别精度。
在系统层面,GLM-OCR采用"版面分析→并行识别"的两阶段技术范式,基于PP-DocLayout-V3实现版面分析,确保在复杂版式下的稳定表现。
应用场景
- 通用文本识别:支持照片、截图、扫描件输入,可识别手写体、印章、代码等特殊文字
- 复杂表格解析:精准处理合并单元格、多层表头,直接输出HTML代码
- 信息结构化提取:从卡证、票据中智能提取关键字段,输出标准JSON格式
- 批量处理与RAG支持:高精度识别能力可为检索增强生成(RAG)提供坚实基础
开源与体验
- Hugging Face:https://huggingface.co/zai-org/GLM-OCR
- 在线体验:https://ocr.z.ai
- 特惠礼包:2.9元享5000万Tokens
智谱表示,未来将持续迭代GLM-OCR,推出更多尺寸版本,并将能力延伸至更多语言和视频OCR领域。
0
好文章,需要你的鼓励