
蚂蚁集团开源发布全模态大模型Ming-Flash-Omni 2.0
2026-02-11 13:42
76
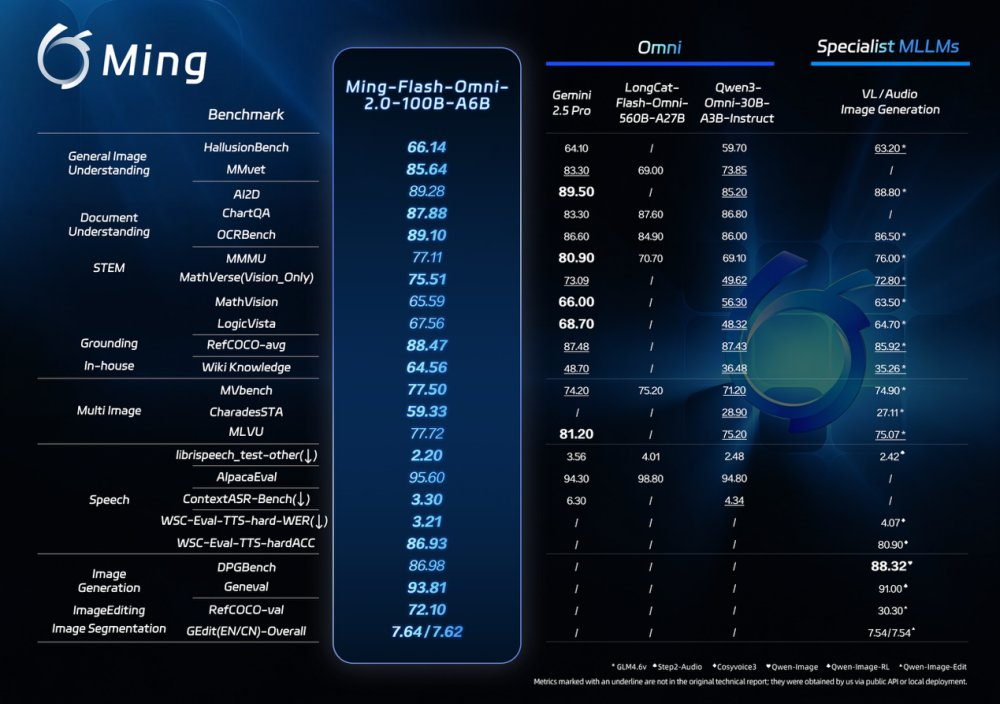
2月11日——蚂蚁集团今日正式开源其最新全模态大模型Ming-Flash-Omni 2.0,该模型在多项公开基准测试中表现出色,尤其在视觉语言理解、语音可控生成、图像生成与编辑等领域部分指标超越Gemini 2.5 Pro,成为开源全模态大模型的新性能标杆。
据介绍,Ming-Flash-Omni 2.0是业界首个全场景音频统一生成模型,能够在同一条音轨中同时生成语音、环境音效与音乐。用户仅需通过自然语言指令,即可精细控制音色、语速、语调、音量、情绪以及方言等多种参数,支持零样本音色克隆与定制功能。
这一突破性能力极大降低了音频内容创作的门槛,为影视配音、游戏音效、虚拟角色互动等场景提供高效解决方案。
在推理效率方面,模型实现了3.1Hz的极低推理帧率,支持分钟级长音频的实时高保真生成,在保持行业领先效率的同时显著控制计算成本。
该模型基于Ling-2.0架构(MoE结构,总参数100B,激活6B)训练,围绕“看得更准、听得更细、生成更稳”三大目标进行全面优化:
- 视觉能力:融合亿级细粒度数据与难例训练策略,提升对复杂对象的识别精度,如近缘动植物、工艺细节及稀有文物。
- 音频能力:实现语音、音效、音乐同轨统一生成,并支持自然语言精细控制。
- 图像能力:增强复杂编辑稳定性,支持光影调整、场景替换、人物姿态优化及一键修图,在动态场景中保持画面连贯与细节真实。
蚂蚁集团在全模态方向持续投入多年,Ming-Omni系列从早期统一多模态底座,到中期验证规模增长带来的能力提升,再到2.0版本通过更大规模数据与系统优化,将理解与生成能力推至开源领先水平,并在部分领域超越顶级专用模型。
此次开源意味着其核心能力以“可复用底座”形式对外释放,为端到端多模态应用开发提供统一能力入口。
0
好文章,需要你的鼓励