
小红书开源FireRed-Image-Edit通用图像编辑模型
2026-02-13 11:15
107
图像编辑技术又有新动作了。小红书基础模型团队刚刚在GitHub上线了FireRed-Image-Edit,这次他们在图像编辑的精准度和实用性上下了不少功夫。从测试数据看,这个模型在处理复杂指令、风格转换还有文字编辑这些难啃的骨头上,表现确实挺能打的。代码、技术报告和在线体验都已经开放,模型权重这几天也会放出来。

RedEdit Bench
你可能会好奇,市面上评测标准那么多,为什么还要自己搞一套?说实话,现有的基准测试确实有点跟不上用户的真实需求了。RedEdit Bench覆盖了15个子任务,除了常规的增删改,还把人像美化、画质增强这些高频场景加了进去——毕竟这些才是大家日常真正会用到的功能。
对比下来,这套评测体系在衡量编辑模型通用能力方面,比ImgEdit和GEdit更精准些。团队后续会把这个Bench开源出来,算是给图像编辑模型的评估立个新标杆吧。
数据构造与模型训练
好的模型离不开好数据。FireRed-Image-Edit搭了一套专门的数据生产引擎,核心思路是把复杂编辑拆成可组合的小任务,然后通过三种路径大规模生产训练数据:指令控制的专家模型合成、结构化控制(分割、关键点、深度图之类)的专家模型合成,还有模板化合成(3D、布局、文字等)。
长尾任务样本不够怎么办?他们用了"检查—补齐"的策略,哪里弱就针对性地补哪里。数据质量这块也没马虎,三层去重加上十多种清洗算子,再配个严格的一致性把关,确保指令遵循度、视觉自然度和内容一致性都在线。
模型训练分了三个阶段走。预训练时用多条件感知桶采样平衡不同编辑任务,随机动态指令提升泛化能力,提前抽取embedding加快训练速度。微调阶段引入高质量数据拉高表现上限。最后在强化学习环节,用非对称梯度优化强化正样本反馈,基于OCR奖励的diffusionNFT专门提升文字编辑准确率。
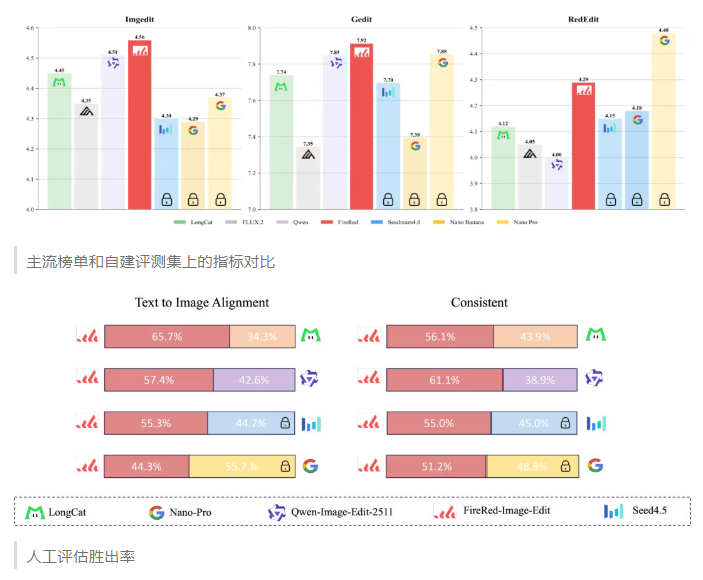
开源这个模型,你们团队是想给社区提供一个高效可控的基础工具。接下来几个月还会持续更新,重点优化人像美化、一致性和文字编辑能力,文生图基座模型也在计划里。感兴趣的话可以去GitHub体验一下,顺手点个Star支持一波。
Super Intelligence团队这两年动作挺多的,发了40多篇顶会论文,做出来的InstantID、StoryMaker、FireRedTTS这些项目在行业里也有些影响力。产品侧像语音评论、文字大字报、长文、满屏高清这些功能,用户反响都还不错。他们的定位比较清楚——既要做前沿模型研究,也要把技术真正落地成能用的产品。
0
好文章,需要你的鼓励