
华为升级行业Agent算法架构MindScale:MindScale自己写prompt和工作流
2026-02-13 11:28
127
大模型想要真正落地到各行各业,专业Agent绝对是个绕不开的话题。但现实很骨感——每个行业都有自己的门道、专业知识和工具链,想把这些都塞进智能体里,难度不小。
好在业界已经有Skills、OpenClaw这样的框架在降低开发门槛,不过算法层面的优化需求也越来越明显了。这不,华为诺亚方舟实验室最近上线了MindScale算法包,把实验室的技术积累和华为在行业智能化方面的实践经验都整合进去了,算是给开发者们提供了一份实用的技术指南。
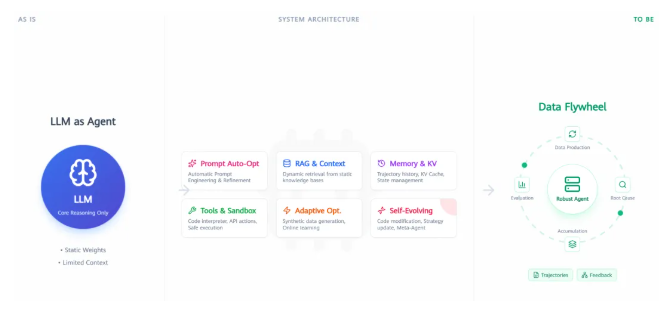
制约行业Agent发展的四大核心挑战
MindScale项目里,研究团队梳理出了四个比较要命的问题:
工作流得靠人工维护,专家要把业务规则一点点"翻译"成Agent能理解的流程;历史数据利用率低,之前的推理路径和反馈很难让系统自己迭代优化;训练推理成本压力大,模型部署多、思考链路长,算力开销直线上升;还有就是评测体系跟不上,多步骤、多工具协同的复杂推理,用单一指标根本看不出模型的真实水平。
实现工作流自进化与提示词自动化闭环
针对工作流开发这个高频场景,算法包提供了EvoFabric这个自进化方案。你不用再依赖专家手动提取流程了,通过SOP2Workflow可以直接从文档和工具库生成能跑的Workflow。
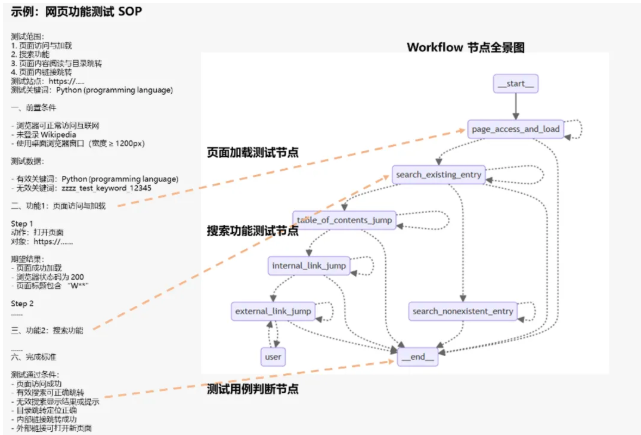
技术实现上,他们用了状态图引擎做内核,天然支持Agent、工具等各种节点的混合编排,状态可以改写、分组、融合处理。多智能体、多工具、多记忆形态都能深度整合,还支持DSL文件的导入导出,复杂流程想复制、迁移都很方便。
更有意思的是记忆演进机制——系统会记住历史执行轨迹和评估结果,形成经验上下文,让Agent越用效果越好。
prompt优化方面也有新玩法。基于SCOPE算法,你可以在每步推理时进行在线优化,从历史路径里提取有效信息来改进提示词。在HLE、GAIA这些agentic reasoning场景里,精度能提升20%以上。
另外还有个C-MOP优化器,通过改进样本选择和梯度更新策略,解决了"文本梯度"冲突的问题,真正实现了基于正负反馈的prompt自动优化闭环。
榨干算力潜能并适配国产硬件生态
精度之外,训推效率优化也是重点。
TrimR这个方案挺巧妙,用预训练的轻量验证器在线检测并砍掉无用的中间思考步骤,全程不用微调大模型。配套的工业级异步系统能扛住高并发场景。在MATH、AIME、GPQA等测试集上,准确率基本不掉的情况下,推理时延能降低不少,高并发场景最高提速约70%。
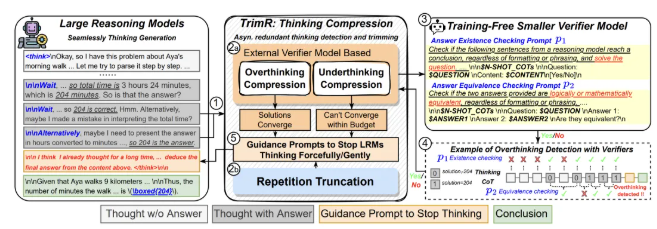
KV Cache这块也有创新。传统方案里它只是个加速解码的后台工具,现在研究团队把它当成"免费"的轻量表示来用——提出了KV-Embeddings概念,不需要额外计算或存储完整隐状态,在链式表示推理、快慢思考切换这些场景里,性能能持平甚至超过专用embedding模型,生成token数最多能减少5.7倍。
这说明KV Cache的潜力还没被完全挖掘出来,它不只是个加速器,更像是个"思考缓存",给推理阶段的表示复用开辟了新思路。
除此之外,诺亚方舟实验室和合作团队在任务记忆、Agentic RAG、通用算法发现等方向也沉淀了不少经过实战检验的技术。值得一提的是,MindScale还适配了昇腾硬件,国产算力也能跑出高精度、高效率的Agent应用了。
对于想在行业场景里落地Agent的开发者来说,MindScale提供的这套算法工具链和技术方案,确实能帮你少走不少弯路。从工作流自动生成到prompt自优化,再到推理加速和硬件适配,该考虑到的点基本都覆盖了。
0
好文章,需要你的鼓励