
Loop-ViT:让AI学会「反复思考」,3.8M参数小模型追平人类平均水平
2026-02-13 11:34
50
你有没有想过,为什么有些数学题需要你反复琢磨才能解开?大脑在这个过程中其实是在不断迭代、推演。可传统的AI模型呢,它们更像是"一口气读完"——数据进去,经过固定的网络层,答案就出来了。这种方式处理图像识别没问题,但碰到需要多步推理的抽象题目,就有点吃力了。
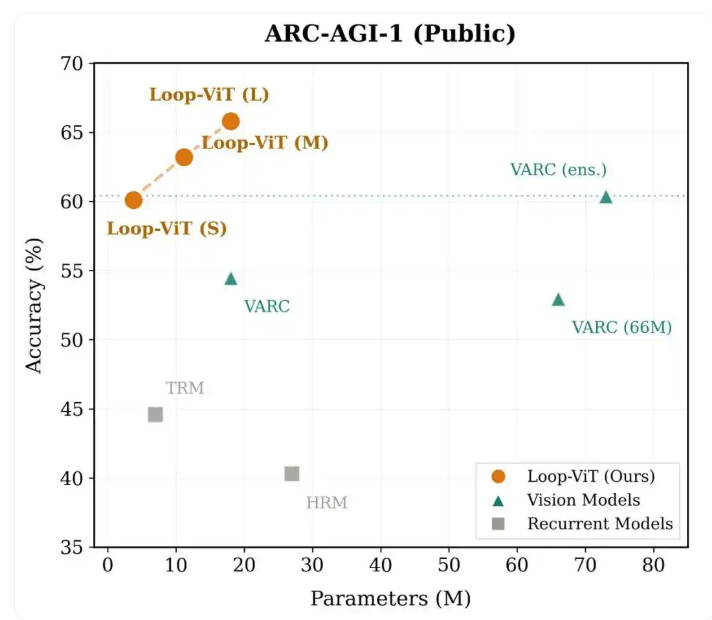
最近香港科技大学、中科院自动化所和UC Santa Cruz的团队搞出了个新东西——Loop-ViT。这个只有18M参数的模型,在ARC-AGI-1基准测试上拿到了65.8%的准确率,超过了参数多达73M的VARC集成模型。更夸张的是,它那个3.8M的迷你版也能达到60.1%,几乎赶上人类平均水平(60.2%)。
什么是ARC-AGI?为什么它如此困难?
ARC-AGI是Keras创始人François Chollet设计的抽象推理测试。跟ImageNet那种认猫认狗的任务不一样,ARC考的是归纳推理能力。
每道题只给你2到4个示例,你得从这些例子里找出隐藏的规则,然后把规则用到新题目上。这些规则可能包括物体的旋转、镜像,图案的重复填充,根据颜色做条件变换,甚至模拟重力之类的物理现象。
人类解这类题目时会观察、假设、验证,不断调整思路。但传统神经网络缺少这种"反复琢磨"的能力——它们的计算深度被网络层数给限死了。
Loop-ViT的核心创新
循环架构:解耦计算深度与参数量
普通Vision Transformer是线性流程:输入→第1层→第2层→……→第L层→输出。每加一层就得多一堆参数。
Loop-ViT的思路完全不同:反复使用同一组权重。核心就是一个权重共享的Transformer块,可以循环执行T次。这样一来,计算深度能随意扩展而不增加参数,模型被迫学会一个通用的"思考步骤",而不是针对特定任务的技巧。
混合编码块:全局推理+局部更新
团队发现ARC任务需要两种处理方式:全局规则归纳(比如理解"所有蓝色变红色"),以及局部模式执行(比如精确填充某个封闭区域)。
为此Loop-ViT设计了Hybrid Block,把自注意力机制(捕捉全局依赖)和深度可分离卷积(处理局部空间模式)结合在一起。
动态退出:知道何时停止思考
不是所有题目都需要想那么久。简单的几何变换可能几步就搞定,复杂的算法推理就得多迭代几轮。
Loop-ViT用了个基于熵的动态退出机制:每次迭代后算一下预测分布的Shannon熵,当熵值低于阈值(说明模型"想清楚了"),就直接停止。不需要额外参数,完全靠模型自己判断。
实验数据显示,能"早退"的样本准确率高达83.33%,需要完整迭代的困难样本准确率是45.80%。这跟人类的认知策略很像——简单问题快速解决,复杂问题多花点时间。
实验结果:小参数,大性能
Loop-ViT在ARC-AGI-1基准上的表现确实惊艳。
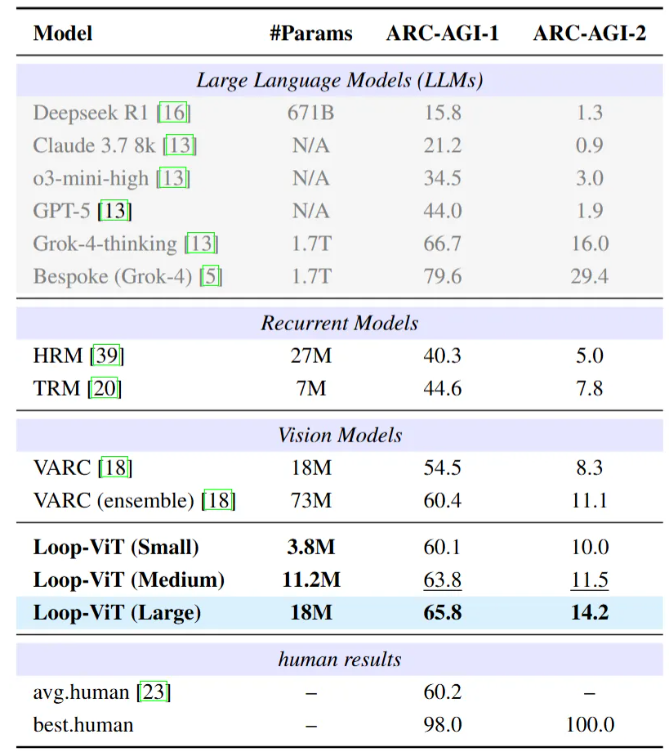
3.8M的小型版超过了18M的VARC,只用了五分之一的参数。18M的版本更是超越了73M的VARC四模型集成。
深入理解:模型在「思考」什么?
团队对Loop-ViT的内部机制做了可视化,发现了些有意思的现象:
预测会经历一个"结晶"过程——开始时预测模糊不定,随着迭代进行逐渐清晰稳定,就像溶液里的晶体慢慢析出。
注意力模式也在变化:早期迭代时注意力分布很广,模型在"扫描"整个输入收集信息;后期注意力变得集中,精确对准需要操作的区域。这种从"全局探索"到"局部执行"的转变,跟人类解决视觉推理问题的方式高度相似。
Loop-ViT的出现证明了一点:AI要想真正具备推理能力,光靠堆参数是不够的。让模型学会"反复思考",可能才是通往通用智能的关键一步。
0
好文章,需要你的鼓励