
腾讯混元 x MBZUAI 港中文新研究:将纠错纳入策略空间,Search-R2 重构搜索增强推理学习方式
2026-02-13 12:13
43
大语言模型这几年主要靠堆参数、堆数据来提升能力,但当它们真正被拿来做研究助理、网页搜索这些实际任务时,问题就暴露了。模型在长链推理中失败往往不是能力不够,而是没法处理错误的传播——早期某次检索出了偏差,后面的推理就会在错误的语义空间里越走越远。

现有训练方法只看最终答案对不对,这导致"蒙对的"和"推理严密的"轨迹获得同样反馈。MBZUAI、港中文和腾讯混元的联合团队提出了《Search-R2》,把推理生成、轨迹判断和错误定位放进同一个强化学习框架,让训练信号能回传到错误首次发生的地方。这项工作不假设推理过程天然可靠,而是承认错误不可避免,让模型在训练中学会定位并修正它们。
完整闭环,而不是单一技巧
实验结果显示,这个方法的优势在任务难度最高、错误最容易累积的场景中特别明显。
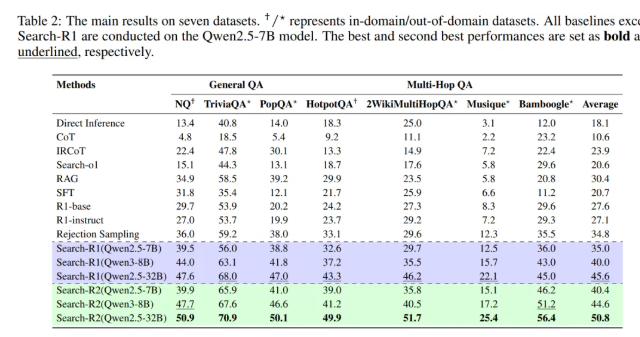
评测覆盖了普通事实问答和多跳推理问答两大类。前者通常一两次检索就能搞定,后者必须经历多轮"搜索-推理-再搜索"。在HotpotQA、2WikiMultiHopQA和Bamboogle这些需要多轮检索的数据集上,相比基线带来了几个到十几个百分点的准确率提升,Bamboogle上的相对提升甚至超过20%。
多跳推理任务的失败通常不是模型生成不出答案,而是中途某次搜索引入了错误信息,把推理方向带偏了。这个方法正是针对这种失败模式设计的。
与拒绝采样的对比实验更说明问题。研究团队把基线方法的采样次数提升到两倍甚至更多,但基线性能仍然低于该方法在较小采样预算下的结果。这说明性能提升不是靠"多试几次总能蒙对",关键是能不能准确识别错误首次出现的位置。拒绝采样会直接丢弃整条失败轨迹,而这个方法认为失败轨迹的前半部分往往仍然正确。
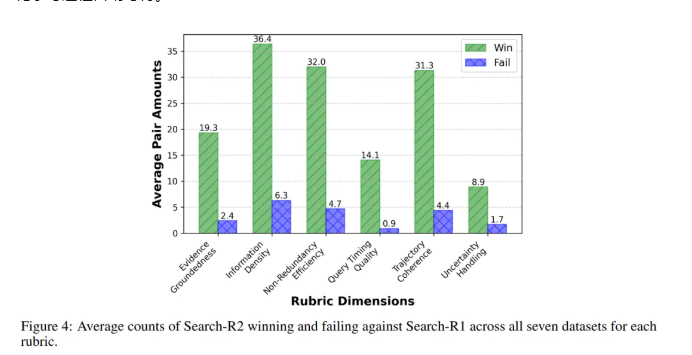
消融实验显示,仅引入中途纠错机制,模型性能就有显著提升。加入用于衡量搜索结果信息密度的过程奖励后,性能继续提升。在对推理生成模块与纠错模块联合优化的完整设置下,所有数据集上都取得最优结果。你会发现,性能提升不是靠单一技巧,而是中途纠错、搜索质量建模和联合优化共同构成的完整机制。
把纠错本身纳入策略空间
在方法设计上,团队明确指出仅依赖最终答案正确与否作为奖励信号,在搜索推理任务中会系统性失效。
模型实际上需要连续做多尺度决策:要不要发起搜索、搜什么、什么时候搜、拿到检索结果后该不该信。传统强化学习只提供"答对或答错"的单一反馈,没法区分这些中间决策的质量。时间长了,模型就学会了"搜索随意展开,早期错误不受惩罚,最终答案能生成就行"。
方法中对不同功能做了明确分工。推理生成模块负责像常规方法那样完整生成一条轨迹,允许犯错和探索。纠错模块会对整条轨迹进行判断,关注点不是最终答案对不对,而是推理过程有没有出现实体偏移、主题漂移。这个判断决定了轨迹值不值得修复——标准太宽松,错误会被放过;太严格,高质量轨迹会被反复打断。这个平衡是通过强化学习自动习得的。
当轨迹被判定需要修复时,系统会定位第一次发生实质性偏离的位置。识别出这个位置后,系统完整保留之前的推理前缀,丢弃后面的内容,从那个点重新生成。这样既避免浪费已有的正确推理,又能让奖励信号精确回传到错误发生的位置。
为防止模型出现"只改结果不管根源"的投机行为,训练中还引入了过程层面的奖励信号,用来衡量检索到的证据里有多少真正支持答案的信息。而且这个过程奖励只在最终答案正确时才生效。
推理生成、轨迹判断和错误定位这几个模块共享同一套参数,在同一强化学习目标下联合优化。是否触发纠错、在哪里纠错,都被视为策略决策的一部分。
一种更贴近失败模式的学习思路
从强化学习角度看,这项研究解决的是搜索推理中长期存在的信用分配难题。模型需要在多个时间尺度上连续决策,传统方法只能根据最终答案分配回报,没法区分高质量轨迹和偶然成功的轨迹。
研究团队通过轨迹筛选、错误定位和受控纠错三种机制,把难处理的信用分配问题拆解成可操作的学习目标。理论分析证明,只有当模型能区分哪些轨迹值得保留、能定位关键错误位置、在训练中触发适量纠错操作时,性能才会稳定提升。
这个方法改变了以往反思与修正仅靠人工提示的做法,把是否反思、在哪修正纳入策略空间,使其成为可通过强化学习直接优化的决策行为。它的设计直接针对真实智能体任务中常见的失败模式:搜索结果有噪声、推理链条长、早期错误影响不可逆。通过在推理过程中显式建模错误传播并提供中途干预机制,为搜索型智能体在复杂任务中的稳定运行提供了更具针对性的解决思路。
说到底,这项工作的价值在于,它不是试图让模型变得"完美无误",而是教会模型如何在不完美的搜索环境中稳定工作。当你的智能体需要在真实世界中执行复杂任务时,这种与错误共处、及时修正的能力,可能比单纯的性能指标更重要。
0
好文章,需要你的鼓励