
2026春节AI圈新动向:Qwen3.5与DeepSeek V4的技术对决
2026-02-14 22:03
85
过年本该是放松的时候,AI圈却没闲着。2月份,阿里千问Qwen3.5的代码在HuggingFace上意外曝光,DeepSeek也传出要发V4的消息。这两家的动作,基本代表了国产大模型在2026年的发展方向——不再盲目堆参数了,开始玩真正的技术创新。
一、Qwen3.5:从代码提交看新一代模型的技术升级
1.混合注意力机制:兼顾性能与效率的技术突破
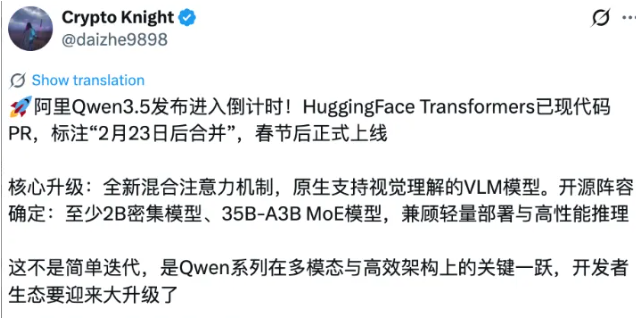
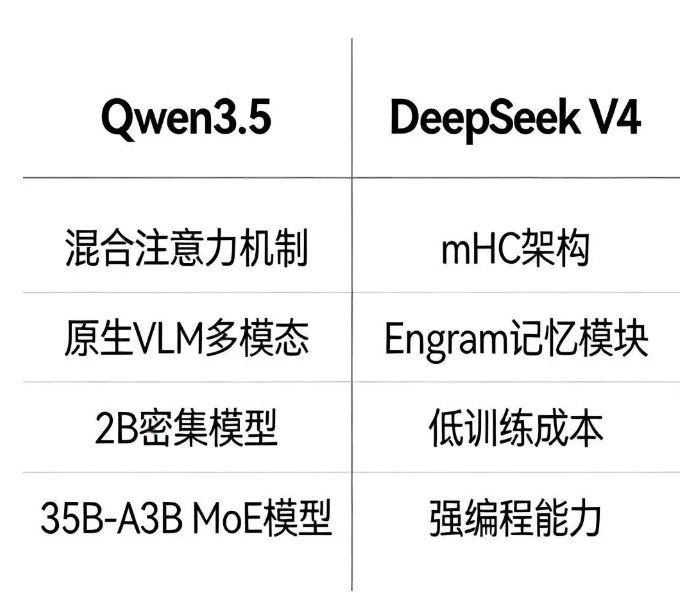
2月9日,HuggingFace的Transformers项目里突然出现了Qwen3.5的代码合并申请。从代码来看,这次升级挺有意思的——用了全新的混合注意力机制,把密集注意力和稀疏注意力结合起来,处理长文本的时候既准又快。据说采用了3:1的混合策略,配合GatedDeltanet的优化设计,处理256K甚至更长的上下文时,速度能比传统模型快好几倍,理解能力还不掉线。
2.原生VLM多模态:从文本到视觉的原生融合
更值得关注的是,Qwen3.5很可能原生就支持视觉理解。代码里出现了Qwen3_5VisionModel、Qwen3_5ForConditionalGeneration这些类名,说明它从设计之初就考虑了多模态融合,不是后期硬加的那种。这样的好处显而易见,处理图像、视频的时候能跟文本理解无缝衔接,像OCR识别、图表解析这类任务的精度应该会高不少。你想想看,扫描个古籍文档,模型直接就能看懂,不用再做一堆预处理了。
3.家族化模型布局:覆盖不同场景的需求
Qwen3.5这次会推家族化的模型,计划开源2B参数的密集模型和35B-A3B架构的MoE模型。2B那个体积小,能在手机上跑,以后手机AI助手的能力可能真的会逼近顶级大模型。35B-A3B的MoE模型则是给高性能场景准备的,通过稀疏激活的专家网络,在成本可控的情况下拉高性能上限。
二、DeepSeek V4:架构创新打破算力内卷
1.mHC架构与Engram记忆模块:底层架构的革新
和Qwen3.5几乎同时,DeepSeek也爆出要发V4的消息。这次主打架构创新,用了两项自研技术:mHC(流形约束超连接)架构和Engram记忆模块。mHC架构改变了传统大模型的连接方式,通过流形约束减少冗余连接,训练的时候算力利用效率更高。Engram记忆模块让模型能更好地存储和调用历史信息,多轮对话或者长任务处理的时候,前后文衔接会更流畅。
2.成本革命:低训练成本与推理成本
V4在成本控制上确实狠。内部数据显示训练成本只要557万美元,传统大模型动不动就上亿,这直接降了几十倍。推理成本更夸张,每百万Token才16元,大概是GPT-4 Turbo的1/70。成本降到这个程度,意味着中小企业和个人开发者也能用得起高性能大模型了,AI落地的门槛又低了一大截。
3.编程能力的突破:瞄准代码生成赛道
V4的核心定位是编程专家,内部测试显示编程能力已经超过了ChatGPT和Claude这些顶级模型。能处理30万行以上的代码逻辑链,在代码生成、调试、优化上表现都不错。DeepSeek本来在代码领域就有积累,V4这一发布估计会进一步巩固他们在这个赛道的优势。
三、国产大模型的新趋势:从参数竞赛到技术创新
1.架构创新成为核心竞争力
过去几年,大模型发展有点陷入参数内卷的怪圈,大家都在比谁的参数多,但算力成本飙升、部署难度也在增加。现在Qwen3.5的混合注意力、DeepSeek V4的mHC架构,都说明国产大模型开始在底层架构上做文章了,通过优化结构来提升性能,而不是无脑堆参数。
2.多模态成为标配
从Qwen3.5的原生VLM设计能看出来,多模态已经是新一代大模型的标配了。未来的AI模型不会只是个聊天工具,而是能处理文本、图像、视频、音频的综合智能体。这对智能办公、智能教育、智能医疗这些场景来说,实用价值会大很多。
3.成本优化推动商用落地
DeepSeek V4在成本上的突破,预示着大模型商用会进入新阶段。训练和推理成本大幅降低后,大模型能更广泛地应用到中小企业甚至个人开发者的项目里,AI技术的普及速度肯定会再快一档。
从Qwen3.5和DeepSeek V4的动向来看,2026年的国产大模型已经走出了单纯的参数竞争,开始在架构创新、多模态融合和成本优化上发力。这种转变,可能才是真正推动AI技术大规模落地的关键。
0
好文章,需要你的鼓励