
Anthropic说被偷了,Musk说你自己也是贼——AI蒸馏攻击争议全解读
2026-02-24 11:55
38
2月23日,一则消息引爆了全球AI圈:美国AI公司Anthropic在官方博客发布长文,指控三家中国AI实验室——DeepSeek、Moonshot AI(月之暗面)和MiniMax(稀宇科技)——利用超过24,000个欺诈账户,与其旗舰模型Claude产生超过1,600万次交互,系统性地提取Claude的核心能力来训练自己的模型。
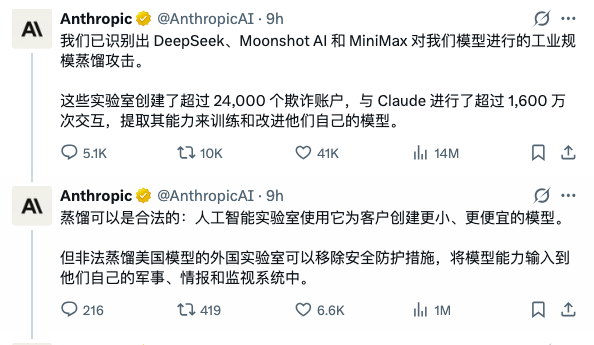
Anthropic将这种行为定义为"蒸馏攻击"(Distillation Attack)。
这不是一个简单的商业纠纷。同一天,路透社独家报道称美国政府高级官员指控DeepSeek使用被禁的英伟达Blackwell芯片训练即将发布的V4模型。而Elon Musk则在X平台反击Anthropic,称其自身"因大规模窃取训练数据而支付了数十亿美元和解金"。
要理解这场争议,我们需要先搞清楚一个核心技术概念:什么是蒸馏?
一、什么是AI蒸馏?5分钟搞懂核心原理
蒸馏(Knowledge Distillation)是机器学习领域的一项基础技术,最早由深度学习先驱Geoffrey Hinton在2015年的论文中系统提出。
它的核心思路非常直观:让一个小模型向一个大模型"学习"。
在AI训练中,大模型("教师模型")虽然能力强,但运行成本高、速度慢,不适合大规模部署。蒸馏的目的是将大模型的"知识"压缩到一个更小、更高效的模型("学生模型")中——学生不需要从零开始学习世界知识,而是直接学习教师"怎么思考、怎么回答"。
打个直觉性的比方:一个学生不需要重新发明微积分,只需要跟着一个好老师学习解题思路,就能快速掌握解题方法。
蒸馏出的小模型通常能保留大模型80-90%的能力,但推理成本可能只有十分之一。正因如此,蒸馏是所有主流AI公司的标准操作。OpenAI的GPT-4o mini、Anthropic的Claude Haiku、Google的Gemini Flash——这些"轻量版"模型本质上都是从更大的旗舰模型蒸馏而来。
这是完全合法且被广泛认可的做法。
二、什么是蒸馏攻击?与正常蒸馏有何区别?
蒸馏攻击的核心区别在于一个字:偷。
正常蒸馏是用自己的大模型训练自己的小模型。蒸馏攻击是未经授权,大规模利用竞争对手的模型输出来训练自己的模型。
以Anthropic指控的场景为例,一次典型的蒸馏攻击分为三个步骤。
第一步是获取访问权。攻击者通过商业代理服务和大量虚假账户访问Claude API,绕过地区限制和身份验证。Anthropic称一个代理网络曾同时管理超过20,000个欺诈账户,形成他们所说的"水螺集群"(hydra cluster)架构——封一个号,立刻补一个。
第二步是系统性提取。与普通用户的随机提问不同,攻击者发送大量精心设计的提示词(prompt),专门针对模型最强的能力领域。Anthropic披露的数据显示,DeepSeek主要针对推理能力和审查安全查询的替代方案,Moonshot AI针对智能体推理、工具使用和计算机视觉,MiniMax针对智能体编码和工具编排。
第三步是训练自己的模型。收集到的海量"问题-回答"对被用作训练数据,或者用来生成强化学习所需的奖励信号。效果相当于用极低成本"搬运"了对方投入数亿美元研发出的核心能力。
简单理解两者的区别:合法蒸馏是自家厨师把招牌菜的做法教给新厨师,蒸馏攻击是派人反复去竞争对手的餐厅点菜、拍照、记录配方,然后回来复制整个菜单。
三、Anthropic是如何发现蒸馏攻击的?
这是很多技术从业者最关心的问题。根据Anthropic官方博文及TechCrunch、CyberScoop等媒体报道,检测体系涉及多个技术层面。
流量模式异常检测
正常用户和蒸馏攻击者的行为模式存在本质差异。普通用户的提问随机、多样、有上下文——今天问做菜,明天问代码,后天闲聊。蒸馏攻击流量则呈现出显著特征:极高的请求量、高度集中在特定能力领域、提示词结构高度重复且系统化。
Anthropic构建了多种分类器来自动识别这类模式。当账户的请求在频率、主题集中度、提示词结构上偏离正常用户分布时,系统会触发警报。
行为指纹识别
即使攻击者试图伪装成正常用户,行为仍会留下"指纹"。
Anthropic特别提到了思维链引出检测:蒸馏最有价值的数据不是模型的最终答案,而是推理过程。攻击者会刻意设计提示词来引出模型的完整推理链,因为这些数据正是训练强化学习所需的。Anthropic专门构建了系统来识别这类"刻意引出推理过程"的提示词模式。
协调行为检测也是关键手段。单个账户容易被封禁,攻击者因此使用数千个账户分散流量,但这些账户之间往往存在协调痕迹——相同的支付方式、同步的使用时间、相似的提示词模板、IP地址的关联性。
基础设施溯源与归因
Anthropic通过IP地址关联、请求元数据分析和基础设施指标,将攻击流量聚类归因到具体公司。他们声称以"高置信度"完成了归因,并与行业合作伙伴进行了交叉验证。
其中最有力的证据来自MiniMax案例。Anthropic声称在MiniMax的攻击仍在进行时就检测到了活动,并观察到一个关键行为:当Anthropic发布新模型时,MiniMax在24小时内将近一半流量转向新模型。这种"追新"行为几乎不可能是正常用户产生的,直接暴露了蒸馏意图,也让Anthropic能将攻击时间线与MiniMax的产品发布路线图进行比对。
检测的完整逻辑链
总结下来,Anthropic的检测逻辑链为:异常流量模式触发警报,行为指纹进行聚类分析,跨账户协调行为被识别,基础设施元数据完成溯源,与公开产品路线图比对,最后通过行业伙伴交叉验证,最终以"高置信度"归因到具体公司。
需要指出的是,Anthropic出于安全考虑没有公布完整的技术细节——公布检测方法本身会帮助攻击者改进规避策略。
四、既然会被发现,为什么还要蒸馏?
这是一个非常现实的问题。答案在于:被抓的代价远低于蒸馏带来的收益。
经济账算得过来
训练一个前沿模型从零开始需要数亿美元算力和数年研发时间。蒸馏的成本是几万个API账户的费用加上代理服务,可能几百万美元就能提取到对手花了几亿美元才训练出的核心能力。即使被发现、被封号,在账户被封之前已经获取的数据仍然可以使用。
被发现和被阻止是两回事
Anthropic说检测到了攻击,但MiniMax产生了1,300万次交互才被完整识别,数据早已到手。代理网络的"水螺集群"架构就是为此设计的——单次攻击可能被中断,但在被系统性发现之前,已经提取了足够的训练数据。检测系统永远是滞后于攻击行为的。
跨境执法几乎不可能
Anthropic能起诉中国公司吗?理论上可以,但在中国管辖权范围内执行美国法院判决几乎没有可操作性。这和Anthropic自己被美国作者起诉完全不同——那个案子在美国法院打,所以不得不赔15亿美元。对中国公司的跨境法律追责目前没有有效路径。
舆论代价也有限
三家公司截至目前都没有公开回应,沉默本身就是有效策略。而且在中美科技博弈的大背景下,这类指控天然带有地缘政治色彩——被指控方可以轻松将自己定位为"美国技术封锁的受害者"而非"知识产权的窃取者"。事实上,连很多美国网友都在社交媒体上嘲讽Anthropic"贼喊捉贼"。
所以理性计算的结论很简单:被发现的概率乘以被发现后的实际惩罚,远小于蒸馏获得的能力提升乘以该能力带来的商业价值。只要这个不等式成立,蒸馏攻击就不会停止。
五、蒸馏能缩小差距,但无法消除差距
如果蒸馏这么好用,被蒸馏的一方为什么还能保持领先?因为蒸馏有一个根本性的天花板:它能复制"答案",但复制不了"出题能力"。
蒸馏只能提取你知道要问的东西
你通过大量提问获取了Claude在代码生成、推理、工具使用上的表现,然后训练自己的模型去模仿。但如果你不知道Claude在某个特定场景下有独特能力,你就不会去设计相关的提示词,也就提取不到。就像一个学生只能抄到他看见的考试题——没看见的题永远抄不到。
蒸馏拿到的是输出,不是架构
Claude为什么能给出高质量的答案?背后是Anthropic花了数年迭代的模型架构、训练方法、RLHF策略、安全对齐技术。蒸馏只能拿到最表层的"回答质量",拿不到产生这些回答的底层工程能力。就像你可以临摹一幅名画,但学不会画家观察世界的方式。
蒸馏数据有"保质期"
今天蒸馏了Claude Opus 4.5的能力,Anthropic下个月发布Opus 4.6,你又落后了。蒸馏方永远在追赶上一代,而原创方在研发下一代。
真正的护城河是原创研究能力
Anthropic发明了Constitutional AI和安全对齐框架,OpenAI发明了GPT架构的多代迭代和o系列推理范式,Google DeepMind有AlphaFold和多模态架构。这些原创性研究突破是蒸馏完全无法获取的。
但也要看到另一面:DeepSeek在2025-2026年发表了多篇原创论文(mHC、Engram、DSA等架构创新),这些不是蒸馏能得来的。而且Anthropic的数据显示DeepSeek的蒸馏规模其实最小(15万次交互),远少于MiniMax的1,300万次。这说明中国实验室的快速进步,更可能是"原创研究 + 工程效率 + 蒸馏加速 + 有限算力下的极致优化"的综合结果。
真正让差距持续存在的核心因素,与其说是技术能力,不如说是算力——出口管制限制了先进GPU的获取,而训练下一代前沿模型需要数万块顶级GPU连续运行数月。蒸馏能绕过一部分算力需求,但无法完全替代。
六、如何客观评价蒸馏攻击?一个中立视角
技术层面:蒸馏是AI发展的自然产物
蒸馏本身就是机器学习领域的基础技术,2015年Hinton的论文就已经奠定了理论基础。它的存在是因为一个客观事实:大模型的能力可以通过输出被部分转移。只要你提供API服务,别人就能通过你的输出学到东西——这不是漏洞,而是这项技术的内在属性。
这和软件行业不太一样。你可以用加密、混淆来保护软件代码,但你没办法让一个模型"只给答案但不泄露任何能力信号"——答案本身就是能力的体现。所以从技术本质上说,开放API和保护模型能力之间存在结构性矛盾。每一家提供API服务的公司都在承受这个风险,包括OpenAI、Anthropic、Google。
法律层面:确实违规,但边界模糊
三家中国实验室的行为有几个层面的违规是比较清晰的:使用虚假账户违反了服务条款,从中国访问Claude违反了地区限制,大规模系统性提取可能构成对计算资源的滥用。这些在合同法层面是站得住的。
但更深层的问题变得模糊:模型的输出是否构成受保护的知识产权?目前全球没有明确的法律先例。蒸馏提取的是模型的"行为模式",不是代码、不是权重、不是训练数据本身。这在现有知识产权框架下很难清晰定性。
而且"合法蒸馏"和"非法蒸馏"的边界在实操中非常难划。一个付费用户大量使用Claude来辅助自己的研究、用Claude的回答来构建数据集、再用这些数据训练自己的模型——这算正常使用还是蒸馏攻击?差别可能只在于规模和意图,而意图是很难从技术上证明的。
道德层面:没有哪一方是干净的
这是最让人不舒服但不得不面对的部分。
Anthropic 的立场有合理性。 他们投入了数亿美元研发Claude,竞争对手通过几百万美元的API费用就提取了核心能力,这确实不公平。如果所有公司都可以免费搭便车,那就没有人有动力投入巨资做原创研发了,整个行业的创新引擎会熄火。
但Anthropic自身的记录削弱了其道德权威。 他们下载了700多万本盗版书籍训练Claude,为此赔了15亿美元。Reddit指控他们抓取用户内容。音乐出版商也在起诉他们。他们用别人的创作成果训练模型,然后指责别人用他们模型的输出训练模型——这在逻辑结构上是一致的行为,只是方向相反。
中国实验室的行为也不能因此被洗白。 "你也偷过所以我偷没问题"不是一个有效的道德论证。违反服务条款就是违反服务条款,使用欺诈账户就是使用欺诈账户。两件错事不会因为共存而变成对的。
整个AI行业目前都建立在一个道德灰色地带上。 几乎所有前沿模型都在训练过程中使用了未经明确授权的数据。区别只在于谁的"偷窃"被法律体系所覆盖、谁的不被覆盖。Anthropic用盗版书训练模型,在美国法院有管辖权所以赔了钱;中国实验室蒸馏Claude,在美国法院没有管辖权所以目前没有后果。这是法律执行力的差异,不是道德高度的差异。
我的整体判断
蒸馏攻击是不对的。 不是因为"美国公司的利益需要保护"这种立场性理由,而是因为一个更普适的原则:未经授权、通过欺诈手段大规模提取他人的商业成果,在任何法律和商业伦理框架下都很难被辩护。
但Anthropic不是一个合格的原告。 一个因使用盗版数据赔了15亿美元的公司,来指控别人窃取自己的模型输出——这在道德叙事上是割裂的。他们的指控在事实层面可能完全准确,但他们缺乏高举道德大旗的资格。
真正需要的不是互相指责,而是规则。 目前AI行业在数据使用、模型输出的知识产权归属、跨境AI服务的法律框架上几乎是无法可依的状态。所有参与者都在灰色地带中博弈,然后在对自己有利时喊规则、不利时喊创新。这个行业需要的是一套所有参与者都受约束的国际规则——既约束"用盗版书训练模型",也约束"用欺诈账户蒸馏模型"。
最后一个观察: 如果蒸馏真的能轻松复制前沿能力,那前沿实验室的"护城河"本身就没有它们声称的那么深。如果蒸馏不能真正复制核心能力,那蒸馏攻击造成的实际损害就没有Anthropic渲染的那么严重。这两种情况下,都不支持Anthropic博文中那种"天塌了"的紧迫语气。真正驱动那种语气的,可能更多是政策游说的需要,而非技术现实。
参考来源:
- Anthropic官方博客:《Detecting and preventing distillation attacks》,2026年2月23日
- Reuters独家报道:Steve Holland & Alexandra Alper,2026年2月23日
- TechCrunch:Rebecca Bellan,2026年2月23日
- CyberScoop:Derek B. Johnson,2026年2月23日
- Decrypt:2026年2月23日
- PBS/NPR:Anthropic 15亿美元和解报道,2025年9月5日
- Elon Musk X平台帖文,2026年2月23日
免责声明: 本文基于截至2026年2月24日的公开信息撰写。本文不构成对任何一方的法律判断。ChooseAI作为AI工具导航平台与文中提及的公司均无商业利益关系。
0
好文章,需要你的鼓励