
OpenClaw 生态黑马突围!中国阶跃 Step 3.5 Flash 凭 196B 模型征服全球开发者
2026-03-01 10:01
52
2026年Agent时代全面到来,OpenClaw以“自动执行中枢”定位爆火,GitHub星标狂飙200k,其核心Skill平台ClawHub汇集超5000个社区技能,国内同类平台“水产市场”也快速崛起(3.3k下载量)。在此风口下,中国团队阶跃星辰(StepFun)发布的Step 3.5 Flash模型异军突起,未做任何官方推广却凭借开发者自发选择,强势跻身OpenRouter榜单前列,成为OpenClaw生态的现象级黑马。
一、榜单逆袭:无推广凭实力登顶海外热榜
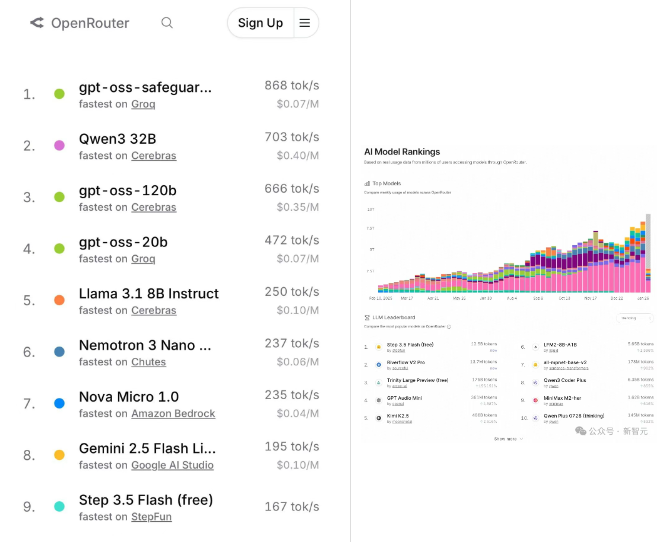
Step 3.5 Flash在全球最大模型聚合平台OpenRouter上表现惊艳:不仅跻身Fastest榜第一梯队(167 tok/s),更一度拿下Trending榜榜首,“Last 30天”调用量稳居全球第四,2月26日后单天调用量冲至第三,仅次于Kimi K2.5与Trinity Large Preview。
这份成绩完全源于开发者“用脚投票”——该模型既不在OpenClaw默认推荐列表,也未与OpenClaw开展官方合作,却凭借适配Agent场景的硬实力,成为全球“逮虾户”(OpenClaw用户)的首选模型之一,充分印证了Agent时代“实战为王”的竞争逻辑。
二、核心优势:直击Agent时代三大痛点
1.极速推理:Agent任务的“效率命脉”
Agent时代的核心需求已从“对话体验”转向“任务交付速度”,Step 3.5 Flash以167 tok/s的推理速度精准契合这一需求。海外用户实测反馈,其在OpenClaw长程任务中“速度奇快无比”,能高效支撑办公自动化、多工具联动等耗时场景,自然兼容性远超同类模型。
2.尺寸神级卡点:完美适配128GB内存
模型采用196B MoE架构,堪称开发者友好的“黄金尺寸”——4-bit量化后可轻松放入128GB内存,同时兼容256K长上下文,解决了230B级模型量化后超内存、需牺牲精度或忍受慢加载的行业痛点。这一设计源于团队深度共情:CTO朱亦博自购128GB内存设备实测,首席科学家也配备同款硬件,确保模型贴合真实部署场景。
3.强逻辑对齐:RL优化保障指令执行
通过RL(强化学习)对齐技术,模型极少出现JSON格式错误或“忘步骤”问题,指令遵循精准度突出,能稳定作为Agent大脑操控外部工具。架构上采用高效稀疏MoE与SWA结构,适配8卡并行推理,兼顾智能密度与运行效率,成为Agent工作流的“性能小钢炮”。
三、AMA坦诚破圈:硬核团队赢得开源社区尊重
阶跃星辰核心团队(含CEO、CTO、首席科学家等11人)做客Reddit硬核社区r/LocalLLaMA,以真诚透明的态度完成AMA互动,征服全球挑剔极客:
1.直面缺陷不回避
针对发布首日工具调用在vLLM、llama.cpp等推理栈不可用的问题,CTO朱亦博公开道歉,承认团队在工具调用模型发布上经验不足,表示已修复多数问题,并承诺未来版本将实现“第0天支持”;对“无限推理循环”Bug,团队解释为缺乏多强度推理训练数据,同步公开RL显式长度控制的修复方案。
2.深剖技术难题
面对“世界知识遗忘”问题,团队坦诚200B级推理模型在对齐阶段易陷入“知识贫乏的闭合子空间”,付出过高“对齐税”,并分享了相关假设与优化思路,这种“拆解坑点”的透明态度赢得社区深度认可,甚至有用户主动提出帮忙开发自动解析器,助力llama.cpp工具调用支持。
四、设计哲学:中国创业公司的破局之道
Step 3.5 Flash的成功背后,是阶跃星辰对Agent时代的深刻判断:
赛道切换认知:大模型已从L1(对话机器人)、L2(推理器)演进至L3(智能体),需适配专属基座架构,低效堆砌参数无意义;
速度优先逻辑:Agent时代速度是核心竞争力,而非参数规模,模型设计以“强逻辑、长上下文、快”为三大目标;
拒绝豪赌思维:摒弃“梭哈大参数”的创业模式,聚焦算力约束下的效率平衡,通过系统与算法联合设计,实现“小而强”的突破。
五、行业启示:2026年AI竞争的真实模样
Step 3.5 Flash的突围印证了AI行业的竞争逻辑重构:从“实验室跑分”转向“真实工作流价值”,从“参数竞赛”转向“场景适配精度”。对于算力不占优势的中国创业公司而言,这种“定点爆破痛点+深度共情开发者+坦诚社区互动”的路径,提供了极具启发性的破局范式。
在OpenClaw生态持续扩张、Agent应用遍地开花的2026年,Step 3.5 Flash用代码与数据证明:真正的模型竞争力,终究藏在“是否解决实际问题”的细节里,而这份源于实战的价值,正是全球开发者最认可的硬通货。
0
好文章,需要你的鼓励