
阿里通义发布语音生成双模型 Fun-CosyVoice3.5 与 Fun-AudioGen-VD
2026-03-02 11:49
59
3月2日消息,阿里巴巴通义实验室语音团队今日正式发布两款支持"FreeStyle"指令生成的语音模型——Fun-CosyVoice3.5 与 Fun-AudioGen-VD,标志着语音合成技术从依赖预设标签的传统模式,正式迈入"自然语言控制表达"的新阶段。
在传统语音生成流程中,用户通常只能从固定的情绪选项、预定义语气类别或限定风格模板中进行选择,难以实现真正细腻、自由的表达控制。此次发布的两款模型打破了这一限制,用户可以直接用自然语言描述想要的语音效果,模型即可理解并生成相应的声音表达。
两款模型各有侧重
两款模型虽然都支持自然语言指令控制,但应用方向截然不同。Fun-CosyVoice3.5 聚焦于多语种音色复刻与精细化表达控制,解决的是"如何让声音说得更好"的问题;Fun-AudioGen-VD 则面向音色设计与场景化音频生成,让声音可以从无到有地被"设计"出来。
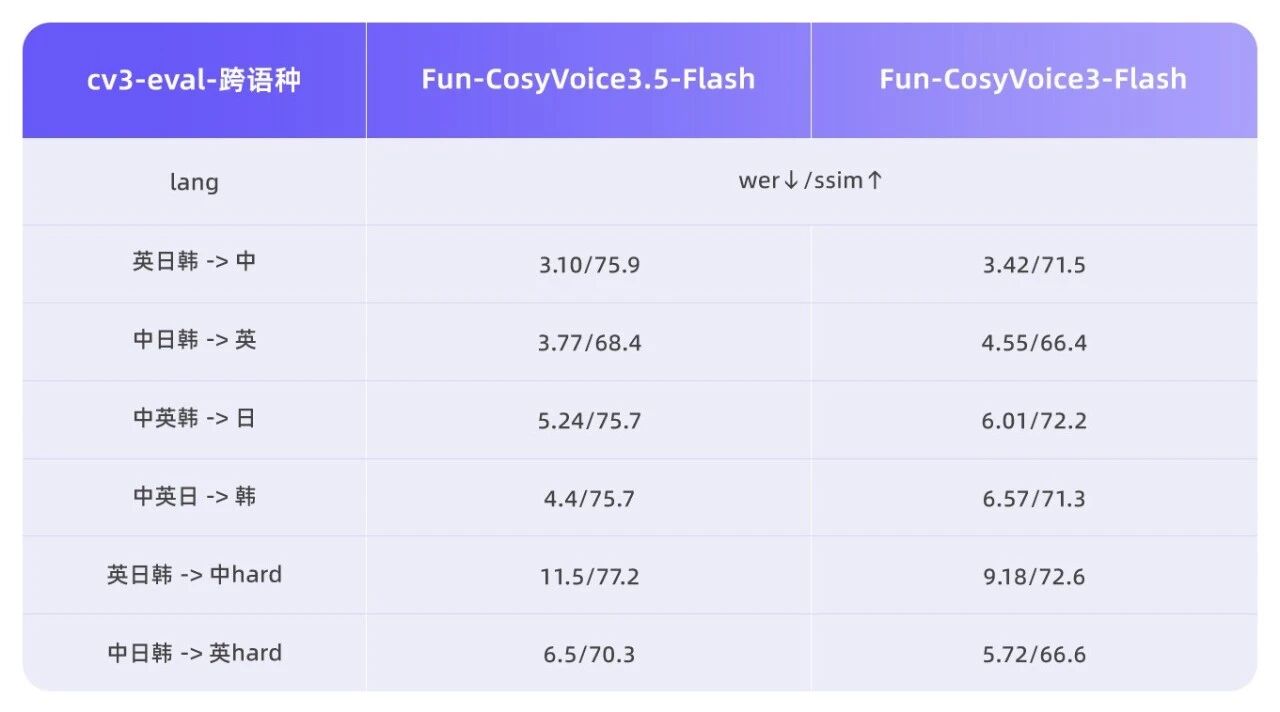
Fun-CosyVoice3.5:表达更自然,响应更快
作为 Instruct-TTS 方向的重要升级,Fun-CosyVoice3.5 支持用户通过一句话描述来控制生成效果。例如输入"语气坚定一点""稍微压低音调,语速慢一点""带一点情绪起伏"等指令,模型便能理解并输出相应表达。同一段参考音频,还可以通过不同指令分别生成普通话或粤语等方言版本。
在语种覆盖方面,该模型新增了泰语、印尼语、葡萄牙语和越南语四个小语种的支持,并在13种语言的词错误率(WER)和说话人相似度(SpkSim)等客观指标上保持了业内领先水平。
发音准确性也得到了显著提升。针对生僻字和复杂语句等容易出错的场景,团队进行了专项优化,将生僻字读错率从15.2%大幅降至5.3%,长文本朗读也更加稳定流畅。
在底层技术上,模型引入了强化学习进行韵律与音质的双重优化。语言模型部分采用 DiffRO + GRPO 策略,增加时长与韵律的多通道奖励机制;音频生成部分则使用 Flow-GRPO 技术,进一步提升了音色复刻相似度和整体音质。性能层面,Tokenizer 帧率减半,首包延迟降低了35%,在实时交互场景下体验更为流畅。
Fun-AudioGen-VD:从音色到场景的一体化声音设计
如果说 Fun-CosyVoice3.5 让声音"说得更好",Fun-AudioGen-VD 则让声音可以"被设计"。该模型支持根据自然语言描述,生成包含目标音色、情绪表达和完整听觉场景的音频内容,实现"人物+场景"的一体化生成。
在音色控制方面,用户可以通过指令精细化地指定声音的基础属性(性别、年龄、口音、音高、语速)、音质特征(沙哑、清亮、低沉、磁性等)、情绪表达(愤怒、悲伤、兴奋、坚定等),甚至进行角色模拟和复杂心理状态的表达,例如"表面镇定但内心颤抖"这样的细腻情感也能被精准呈现。
更值得关注的是其环境与空间声学模拟能力。Fun-AudioGen-VD 不仅能生成声音本身,还能构建声音所处的"世界"——叠加城市喧嚣、咖啡馆氛围、战场轰鸣等背景音效,模拟大教堂、金属牢房、水下等空间的混响效果,还原老式广播、对讲机等设备的特殊听感,甚至支持风噪断续、回声变化等动态环境互动效果。
从"功能工具"到"创作工具"
这两款模型的发布,意味着语音生成正在从一个"功能工具"升级为"创作工具"。在影视动画配音、游戏角色语音、有声书制作以及AI角色塑造等场景中,创作者不再需要依赖大量录音和反复调试,而是可以通过自然语言快速定义音色、情绪与场景,显著降低制作成本,提升内容的沉浸感。
此外,Fun-AudioGen-VD 还能生成高质量的参考音频,为声音复刻提供更丰富的素材基础,与 Fun-CosyVoice3.5 形成能力上的互补。
值得注意的是,在当前语音AI赛道竞争日趋激烈的背景下,OpenAI 的 gpt-4o-mini-tts 也支持通过 instructions 参数控制语音风格,Bilibili 开源的 IndexTTS2 则实现了情感表达与说话人身份的解耦控制。通义此次推出的 FreeStyle 指令体系,在指令理解的自由度和场景生成的丰富度上做出了差异化尝试,能否在实际应用中赢得开发者和创作者的青睐,仍有待市场检验。
两款模型目前已可通过阿里云百炼平台的API进行调用,相关文档已同步上线。
相关链接:
- API调用文档:https://help.aliyun.com/zh/model-studio/text-to-speech
- CosyVoice 声音复刻 API:https://help.aliyun.com/zh/model-studio/cosyvoice-clone-api
0
好文章,需要你的鼓励