残差连接是现代大语言模型的基础构件,但其固定权重的均匀累加方式存在一个长期被忽视的根本性缺陷——随着网络深度增加,隐藏状态的幅度以O(L)的速度不受控增长,逐层稀释每一层的相对贡献,导致早期层的信息被不可逆地"淹没"。月之暗面(Moonshot AI)旗下Kimi团队近日发布技术报告,提出Attention Residuals(AttnRes),用可学习的softmax注意力机制替代固定累加,让每一层能够选择性地从所有前序层中检索信息,从根本上解决了这一困扰深度网络多年的信息稀释问题。
标准残差连接的核心更新公式是hl = hl-1 + fl-1(hl-1),展开后可以看到,每一层接收到的是所有前序层输出的等权求和。这意味着无论是注意力层还是MLP层,无论输入内容如何变化,深度方向的信息聚合始终由固定的单位权重控制,没有任何机制可以选择性地强调或抑制特定层的贡献。在采用PreNorm范式的现代LLM中,这种均匀累加导致隐藏状态幅度随深度线性增长,迫使深层网络学习越来越大的输出以保持影响力,实验表明相当比例的层甚至可以被裁剪而几乎不影响性能。
Kimi团队观察到,深度方向上的这种固定累加与RNN在时间序列上的递归结构存在形式上的对偶性。正如Transformer通过注意力机制取代了RNN在序列维度上的递归,AttnRes对深度维度做了同样的事情:将固定累加hl = Σvi替换为hl = Σαi→l · vi,其中αi→l是通过softmax注意力计算的权重。每一层配备一个可学习的伪查询向量wl,通过与前序层输出的内积和softmax归一化,生成依赖于输入内容的聚合权重。由于网络深度远小于序列长度(通常L < 1000),深度方向的O(L²)注意力在计算上完全可行。
报告通过统一的结构化矩阵分析框架揭示了一个重要理论洞见:标准残差连接及Highway Network、Hyper-Connections等先前变体,本质上都在执行深度方向的线性注意力,而AttnRes则将其升级为深度方向的softmax注意力,完成了与序列维度上从线性到softmax的同一关键转变。
在标准训练中,Full AttnRes几乎不增加额外开销,因为它所需的前序层输出本就为反向传播而保留在内存中。但在大规模分布式训练中,激活重计算和流水线并行使得这些激活必须被显式保存和跨阶段传输,内存和通信开销增长至O(Ld)。为此团队提出Block AttnRes:将L层划分为N个块,块内通过标准残差累加压缩为单一表示,跨块执行注意力聚合,将内存和通信从O(Ld)降至O(Nd)。实验表明,N≈8即可恢复Full AttnRes的大部分收益,仅需存储8个隐藏状态即可实现高效的跨层信息检索。
为使Block AttnRes在工业规模下真正可用,团队开发了两项关键基础设施优化。一是跨阶段缓存机制:在交错流水线调度中,各物理阶段缓存先前虚拟阶段已接收的块表示,后续传输仅携带增量块,将峰值通信成本从O(C)降至O(P),实现了V倍的改进。二是两阶段推理策略:Phase 1将块内所有层的伪查询批量化为单次矩阵乘法,与缓存的块表示进行注意力计算,将内存访问从S次降至1次;Phase 2按序处理块内依赖并通过online softmax合并两阶段结果,自然支持与RMSNorm等操作的核融合。最终实测,Block AttnRes在流水线并行下的训练开销低于4%,推理延迟开销低于2%。
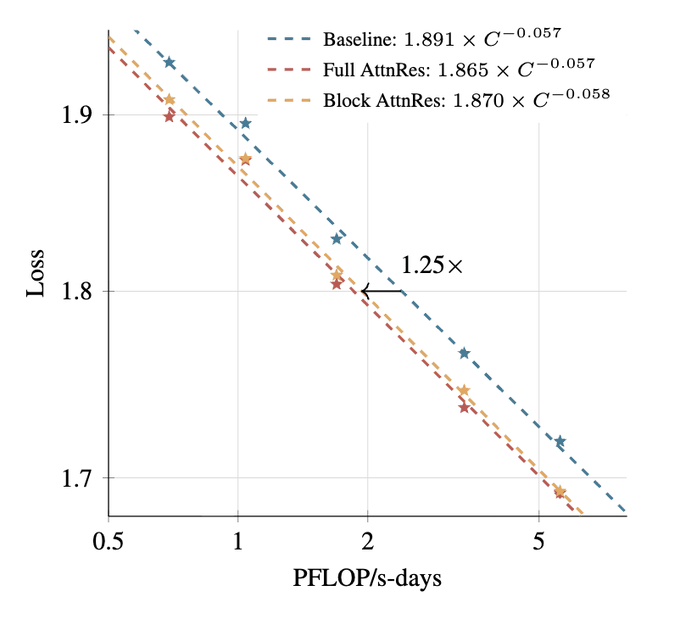
Scaling law实验在五个模型规模上验证了AttnRes的一致性收益。基线模型遵循L = 1.891 × C^(-0.057)的幂律曲线,Block AttnRes拟合为L = 1.870 × C^(-0.058),Full AttnRes为L = 1.865 × C^(-0.057)。三者斜率相近但AttnRes在整个计算预算范围内持续实现更低损失。在5.6 PFLOP/s-days的计算量下,Block AttnRes的验证损失为1.692,对比基线的1.714,等效于1.25倍的计算优势。Full和Block AttnRes之间的差距随规模缩小,在最大规模下仅为0.001。
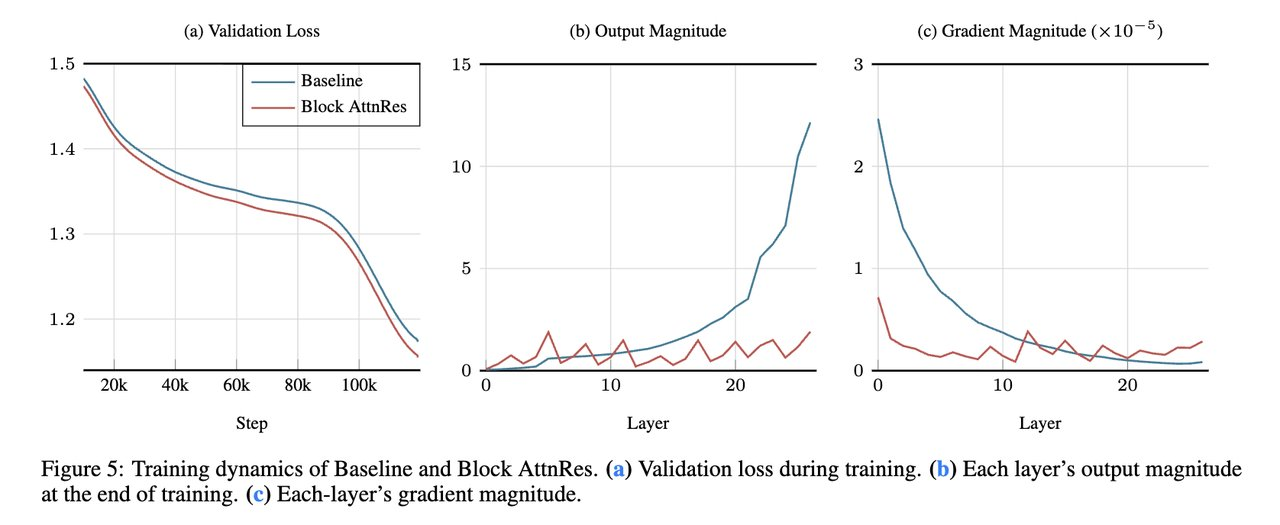
团队进一步将AttnRes集成到完整的Kimi Linear架构中——48B总参数、3B激活参数的MoE Transformer,在1.4T Token上进行预训练。训练动态分析揭示了AttnRes如何从机制层面缓解PreNorm稀释:基线模型的输出幅度随深度单调增长,Block AttnRes则将增长限制在每个块内,在块边界通过选择性聚合重置累积,形成有界的周期性模式;梯度方面,基线的固定残差权重导致最早层梯度不成比例地偏大,而AttnRes的可学习softmax权重引入了概率质量的竞争机制,使梯度分布显著更均匀。
在下游基准测试中,AttnRes在所有评估任务上匹配或超越基线。提升在多步推理任务上尤为显著:GPQA-Diamond从36.9提升至44.4(+7.5),Math从53.5提升至57.1(+3.6),HumanEval从59.1提升至62.2(+3.1)。知识导向的基准如MMLU(+1.1)和TriviaQA(+1.9)同样获得稳固提升。这一模式与改善深度方向信息流有利于组合性任务的假设一致——深层可以选择性地检索并构建于早期表征之上。
消融实验验证了关键设计选择的合理性。与DenseFormer(固定、非输入依赖的标量系数)相比,后者在基线上无收益(1.767 vs 1.766),凸显了输入依赖权重的重要性。与mHC(通过m条并行流实现输入依赖)相比,AttnRes仅凭每层一个查询向量即超越了其表现。softmax优于sigmoid(1.737 vs 1.741),归因于竞争性归一化带来的更尖锐选择。多头注意力反而损害了性能(1.752 vs 1.746),表明深度注意力的收益在于选择强调哪些来源,而非细粒度的通道混合。RMSNorm对于防止大幅度输出主导注意力权重至关重要,移除它会在Full和Block变体上均导致退化。
架构搜索实验揭示了一个有趣的发现:在固定计算预算和参数量下,AttnRes将最优架构配置从基线的dmodel/Lb≈60转移到dmodel/Lb≈45。在固定参数预算下,更低的dmodel/Lb意味着更深更窄的网络,表明AttnRes能够更有效地利用额外深度。团队指出这一深度偏好并不直接转化为部署建议(更深的模型通常推理延迟更高),但它从诊断角度揭示了AttnRes的收益来源。
对学习到的注意力权重模式的可视化分析显示了三个关键特征:局部性保持——每层最强关注其直接前驱,但出现了选择性的跨层跳跃连接;层特化——Token嵌入在整个深度上保持非零权重(尤其在注意力层前),pre-MLP输入更依赖近期表征而pre-attention输入维持更宽的感受野;Block AttnRes保留结构——对角主导、嵌入持久性和层特化从Full变体完整迁移到Block变体,表明块压缩起到了隐式正则化的作用。
Attention Residuals的核心贡献在于将深度维度上信息聚合的"最后一块拼图"补齐:序列维度上从RNN到Transformer的注意力化转变早已完成,专家路由、序列混合等机制均已采用可学习的输入依赖加权,唯独深度方向的残差连接仍停留在固定单位权重的阶段。AttnRes以极低的参数开销(每层仅增加一个RMSNorm和一个d维向量)和可忽略的推理代价,实现了对这一基础组件的系统性升级,为未来更深、更高效的LLM架构探索开辟了新的方向。
项目地址:https://github.com/MoonshotAI/Attention-Residuals