Claude Opus 4.7 全量上线,凭借编码能力、视觉理解、长上下文三大升级引爆 AI 圈,但实测发现其在文字表达、自然交互上明显倒退,成为 “只会写代码、不懂说人话” 的工具化模型。本文从核心升级、关键问题、新功能、行业反思四方面完整解读。
一、核心升级:性能全面狂飙,多项指标登顶
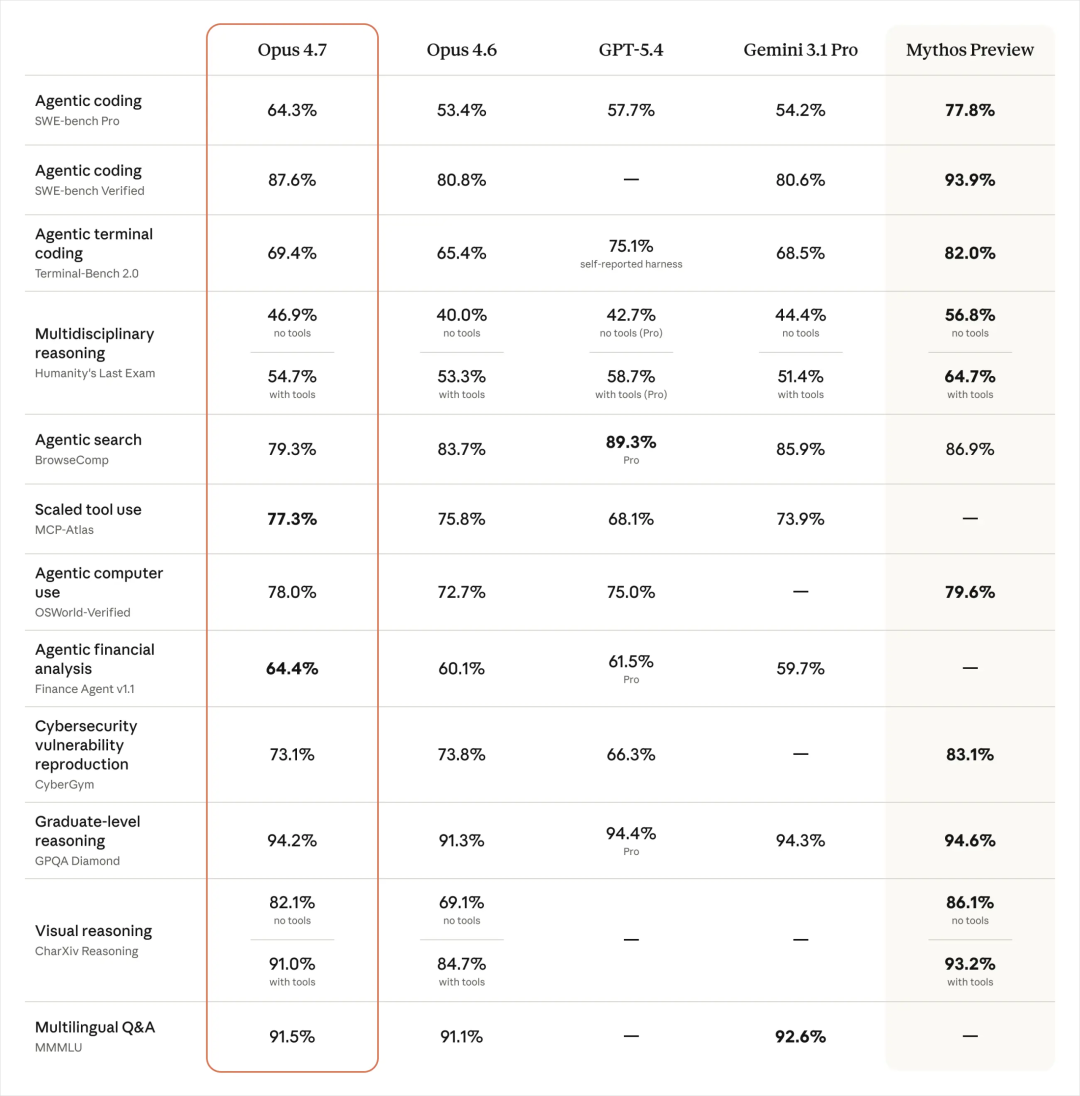
- 编码能力大幅提升SWE-bench 从 53.4% 提升至 64.3%,Verified 准确率达 87.6%,复杂工程任务显著增强,首次解决多项前代无法完成的难题。
- 视觉能力史诗级增强支持最高 2576px 高分辨率图像,视觉识别准确率从 54.5% 飙升至 98.5%,可精准识别界面、图表、PDF、代码截图等高密度信息。
- 保持 1M 上下文窗口超长上下文稳定性行业领先,适合长文档、代码库、研究报告处理。
- 新增 xhigh 思考档位在 high 与 max 之间增加专属强度,默认启用,复杂任务更稳。
二、隐性代价:Token 变相涨价,成本上升
Opus 4.7 更换新分词器,相同内容 Token 消耗增加 0%~35%。虽然官方定价不变(输入 $5/M、输出 $25/M),但实际任务成本明显上涨。官方解释为 “一次通过率提升、减少返工”,但日常轻量任务用户将直接承担更高成本。
三、最大争议:文字品味倒退,开始 “不说人话”
作者作为资深创作者与 UX 设计师,明确指出 Opus 4.7 出现严重问题:
- 文风开始向 GPT-5.4 靠拢:干瘪、工具化、缺乏美感
社区大量用户反馈相同问题:曾经最有 “文字品味” 的模型,如今变得冰冷且模板化。
四、实用新功能:专业场景更强,但更趋工程化
- /ultrareview 超级代码审查深度代码检查,一次成本 5~20 美元,适合企业级重度开发。
- Cyber Verification Program开放白帽子、渗透测试、安全研究申请通道,合法用途可解除安全限制。
- 审美与前端能力提升UI、交互、动效设计更现代化,能直接生成高质量网站与界面。
五、行业反思:大模型集体 “偏科”,只重代码不重人文
Opus 4.7 的变化折射行业趋势:
作者感叹:AI 越来越强,却越来越不会说人话;只会解决工程问题,不再懂得表达与共情。
总结
Claude Opus 4.7 是目前最强的专业级工作模型,尤其适合:
但它不再是那个擅长创作、文案、思考与交流的 “伙伴型 AI”。性能登顶的同时,也失去了最珍贵的 “人味”,成为 AI 行业内卷的典型缩影。